agent harness คืออะไร ชั้นที่ครอบ LLM ให้ทำงานวนเป็นลูปได้จริง ไม่ใช่แค่ถามตอบครั้งเดียว
agent harness คือ environment ที่ครอบ LLM ให้ทำงานวนเป็นลูปต่อเนื่องได้จริง แต่ละรอบเริ่มด้วย context สะอาดใหม่ พร้อมกฎชัดเจนว่าเริ่มงานและจบงานเมื่อไร แทนการพึ่งคำตอบครั้งเดียวหรือการย่อ context ด้วยการ summarize ที่พังเมื่องานยาวขึ้น คำว่า harness engineering เพิ่งถูกตั้งชื่ออย่างเป็นทางการช่วงต้นปี 2026 ทั้งที่เทคนิคนี้ถูกใช้งานมาก่อนหน้านั้นแล้ว

ลองสังเกตงานที่ AI ทำได้น่าเชื่อถือจริงในช่วงนี้ จะเห็นรูปแบบหนึ่งซ้ำกันอยู่ คือมันไม่ได้ตอบทีเดียวจบ แต่ทำงานวนเป็นรอบ ทำทีละชิ้น เสร็จชิ้นหนึ่งค่อยขยับไปชิ้นถัดไป รูปแบบที่ครอบ LLM ไว้แบบนี้เพิ่งถูกตั้งชื่ออย่างเป็นทางการช่วงต้นปี 2026 ว่า agent harness ทั้งที่คนทำของจริงใช้เทคนิคนี้กันมาก่อนหน้านั้นนานแล้ว แค่ยังไม่มีชื่อเรียกเท่านั้นเอง พูดให้สั้นที่สุด harness คือ environment ที่ครอบ LLM ไว้อีกชั้น ทำให้มันกลายเป็น agent ที่ทำงานวนเป็นลูปต่อเนื่องได้จริง ไม่ใช่แค่กล่องถามตอบที่ตอบครั้งเดียวแล้วจบ
แต่คำนิยามที่ได้ยินบ่อยที่สุดอย่าง "environment สำหรับ agent" มันกว้างเกินไปจนแทบไม่ได้บอกอะไร เพื่อจะเข้าใจว่าชั้นนี้ทำหน้าที่อะไรจริง ๆ ต้องย้อนกลับไปดูก่อนว่า ก่อนจะมีมัน เราพยายามให้ LLM ทำงานยาว ๆ ด้วยวิธีไหน แล้ววิธีเดิมพังตรงไหน
ทำไมการตอบครั้งเดียวถึงไม่พอ
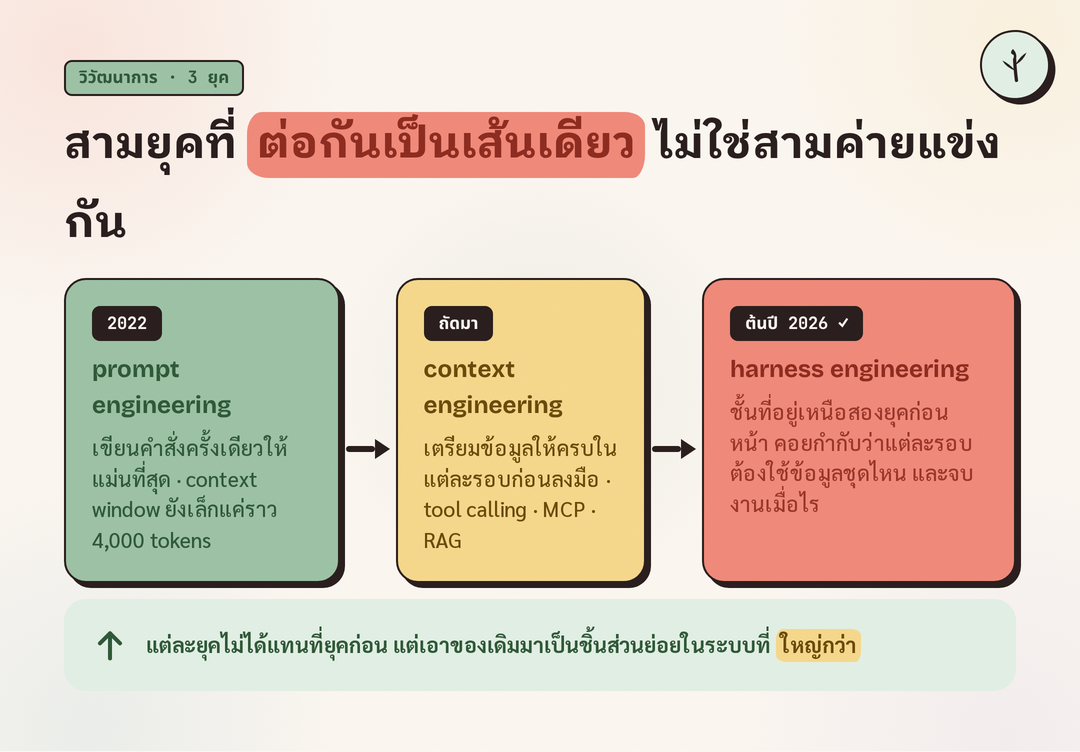
นึกภาพการสั่งงาน LLM เหมือนการบอกให้ใครสักคนเดินทางไกล ถ้าปลายทางอยู่ใกล้ บอกครั้งเดียวก็ไปถึง นี่คือยุคแรกที่เรียกว่า prompt engineering การเขียนคำสั่งครั้งเดียวให้ดีที่สุด เพื่อให้ได้คำตอบแม่นที่สุดในรอบเดียว ยุคนี้สำคัญมากตอนที่ ChatGPT เปิดตัวในปี 2022 เพราะตอนนั้น context window มีแค่ราว 4,000 tokens พื้นที่ใส่ข้อมูลจึงน้อยมาก การเลือกคำในคำสั่งเลยมีผลต่อคุณภาพคำตอบโดยตรง
ปัญหาคือพองานยาวขึ้น ปลายทางไกลขึ้น การบอกครั้งเดียวก็ไม่พอ จึงเกิดยุคที่สองคือ context engineering การป้อนข้อมูลรอบงานให้ครบ เพื่อให้ AI เห็นภาพทั้งหมดก่อนลงมือ เทคนิคในยุคนี้คือสิ่งที่หลายคนคุ้นกันดี ทั้ง tool calling ที่ให้ AI เปิดอ่านเฉพาะไฟล์ที่เกี่ยวข้องและเรียกใช้เครื่องมือภายนอกได้ ทั้ง MCP ที่ต่อความสามารถเฉพาะของแต่ละเจ้ามาใช้ และ RAG ที่เชื่อม AI เข้ากับฐานข้อมูลของเราเอง coding agent รุ่นแรก ๆ อย่าง Cursor, Windsurf, Cline, Roo และ Aider ก็โตมาจากแนวคิดยุคนี้ทั้งนั้น
จุดที่ context engineering เริ่มพัง
วิธีป้อน context ให้ครบทำงานได้ดีมาก จนถึงวันที่งานยาวเกินกว่าที่ context window จะรับไหว ลองนึกถึงงานที่กินเวลา 12 ชั่วโมงขึ้นไป ระหว่างทางข้อมูลที่สะสมเข้ามาจะล้นพื้นที่ที่มีอยู่ พอใกล้เต็ม agent ก็จะใช้วิธีย่อความหรือ summarize สิ่งที่ทำมาทั้งหมดให้สั้นลง แล้วเอาฉบับย่อนั้นไปใช้ทำงานต่อ
ฟังดูเข้าท่า แต่ตรงนี้แหละที่เริ่มมีรอยรั่ว เวลาย่อความ บางทีมันตัดรายละเอียดที่ยังจำเป็นทิ้งไป บางทีมันด่วนสรุปไปเองว่างานเสร็จแล้วทั้งที่ยังไม่เสร็จ หรือมองข้ามสิ่งที่ยังไม่ได้ตรวจสอบให้แน่ใจ เปรียบเหมือนคนเดินทางไกลที่จำทางเดิมไม่ไหว เลยจดโน้ตย่อ ๆ ไว้ พอเดินไปเรื่อย ๆ โน้ตที่เคยชัดก็เริ่มเลือนและคลาดเคลื่อน สุดท้ายก็หลงทางทั้งที่มั่นใจว่ามาถูก
ช่วงรอยต่อนั้นมีคนลองหาทางออกกันหลายแบบ ทางหนึ่งคือใช้ sub-agent หรือปล่อย agent หลายตัวออกไปทำงานพร้อมกัน แบ่งงานกันถือ context คนละส่วน วิธีพวกนี้ช่วยได้อยู่ แต่ก็เป็นเหมือนทางผ่านมากกว่าคำตอบจริง เพราะมันยังพยายามแก้ที่การจัดการ context ก้อนเดิมที่นับวันมีแต่จะใหญ่ขึ้น
harness แก้ที่โครงสร้าง ไม่ใช่ที่ context
ทางออกที่อยู่ตัวกว่าคือเปลี่ยนวิธีคิดทั้งหมด แทนที่จะดิ้นรนแบกข้อมูลทั้งกองไว้ในรอบเดียวให้ได้ harness เลือกซอยการเดินทางไกลออกเป็นช่วงสั้น ๆ แล้วเดินทีละช่วง จบช่วงหนึ่งค่อยเริ่มช่วงใหม่ด้วยหัวที่โล่ง นี่คือหัวใจของยุคที่สามที่เรียกว่า harness engineering
สิ่งที่ทำให้ harness ต่างจากของเดิมมีสองอย่างที่ต้องเข้าใจให้ชัด
อย่างแรกคือ การวนลูป harness ไม่ได้พยายามทำงานทั้งหมดให้จบในการคิดครั้งเดียว แต่ทำงานเป็นรอบ แต่ละรอบหยิบงานมาทำทีละชิ้น เสร็จแล้ววนกลับมาหยิบชิ้นถัดไป จนกว่างานทั้งหมดจะหมด อย่างที่สองคือ context สะอาดใหม่ทุกรอบ ตรงนี้ต่างจากวิธีเดิมแบบกลับด้าน แทนที่จะสะสม context เก่าทบไปเรื่อย ๆ จนรกและเลือน harness เริ่มแต่ละรอบด้วย context ที่สะอาด เหมือนคนเดินทางที่พอถึงจุดพักก็วางสัมภาระลง พักให้หายเหนื่อย แล้วค่อยออกเดินช่วงใหม่ด้วยแรงเต็ม ไม่ต้องแบกความเหนื่อยล้าของทั้งวันติดตัวไปทุกก้าว
แล้วถ้าเริ่มใหม่ทุกรอบ AI จะรู้ได้ยังไงว่าทำอะไรไปแล้วบ้าง เหลืออะไรต้องทำต่อ คำตอบอยู่ที่ตัวเอกสารงาน ไม่ใช่ที่ความจำของ AI
ลูปจริงหน้าตาเป็นแบบไหน
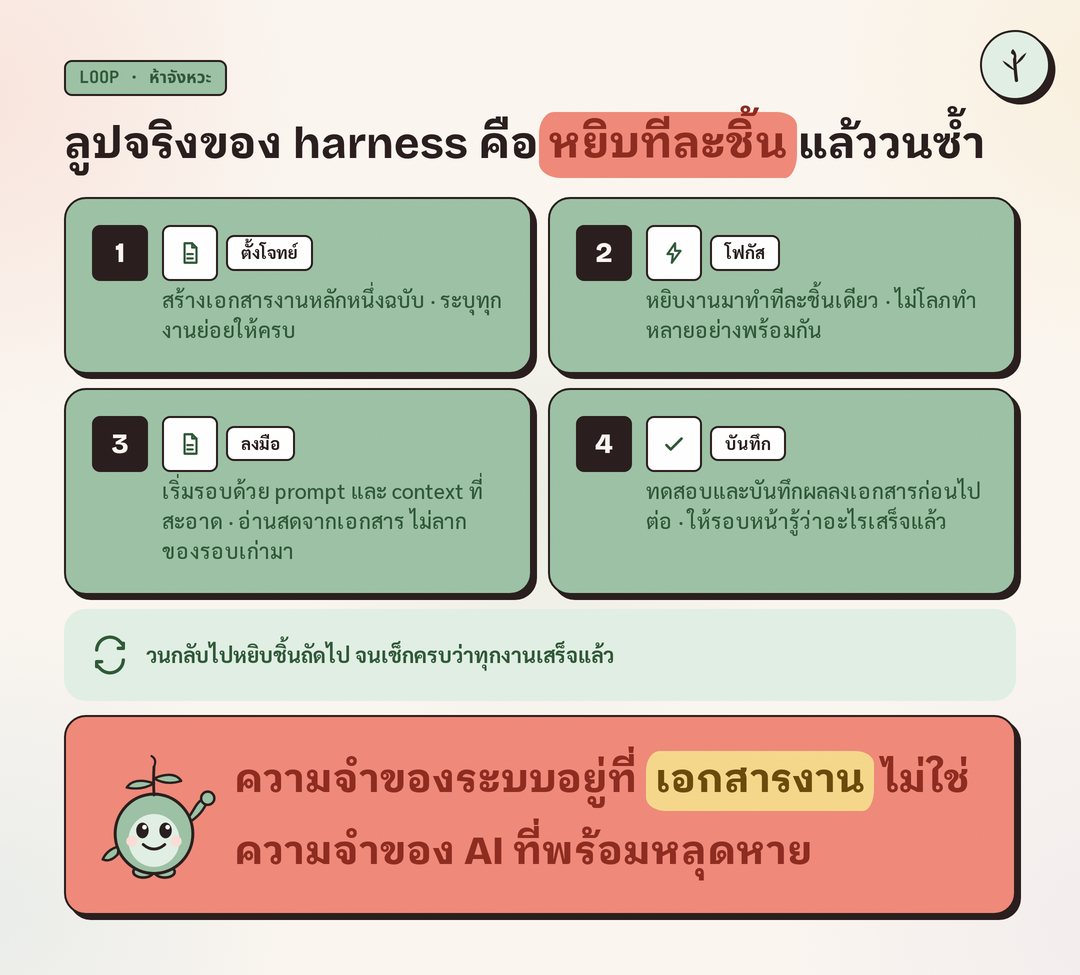
ขั้นตอนที่ทำให้ harness ทำงานได้จริงอธิบายได้เป็นห้าจังหวะ และตัวอย่างที่เห็นภาพชัดที่สุดคือ harness ตัวเล็ก ๆ ที่ชื่อ ROLF ซึ่ง repo เล็กและสถาปัตยกรรมเรียบง่ายมาก แต่ได้ผลดีเกินตัว
- สร้างเอกสารงานก้อนใหญ่หนึ่งชิ้น ระบุทุกงานย่อยที่ต้องทำลงไปให้ครบ ในตัวอย่างของ ROLF จะเริ่มจาก PRD หรือเอกสารกำหนดความต้องการ แล้วแตกออกมาเป็นโครงงานในรูปแบบ JSON ที่ไล่งานได้เป็นชิ้น ๆ
- เริ่มลูป โดยแต่ละรอบหยิบงานมาทำทีละชิ้นเดียว ไม่โลภทำหลายอย่างพร้อมกัน เลือกหนึ่งงานจากเอกสารมาโฟกัส
- เริ่มทุกรอบด้วย prompt และ context ที่สะอาด ไม่ลากของจากรอบก่อนมาด้วย ข้อมูลที่ AI ต้องรู้มาจากเอกสารงานที่เปิดอ่านสด ไม่ใช่จากความจำที่สะสมไว้
- ทดสอบและบันทึกผลของแต่ละชิ้นก่อนไปต่อ เสร็จงานหนึ่งชิ้นแล้วตรวจให้แน่ว่าใช้ได้จริง พร้อมจดสิ่งที่ทำไว้ในเอกสาร เพื่อให้รอบถัดไปรู้ว่าอะไรเสร็จแล้ว
- วนกลับไปข้อสองซ้ำ หยิบงานชิ้นถัดไป ทำแบบเดิม จนกว่าทุกงานในเอกสารจะถูกเช็กว่าเสร็จครบ
เห็นได้ว่าความจำของระบบไม่ได้อยู่ในหัว AI อีกต่อไป แต่ย้ายออกมาอยู่ในเอกสารงานที่เปิดอ่านและเขียนได้ตลอด AI แต่ละรอบแค่มารับงานชิ้นเดียวไปทำให้เสร็จ ส่วนเอกสารจะเก็บภาพรวมว่าเดินทางมาถึงไหนแล้ว ไม่ใช่ปล่อยไว้ใน context ที่เลือนได้
prompt ที่ดียังจำเป็น แค่ไม่ใช่ทั้งหมด
จุดที่ทำให้คนเข้าใจ harness ผิดบ่อย คือคิดว่ามันมาลบล้างทุกอย่างที่เคยเรียนมา ความจริงตรงกันข้าม coding agent แบบ open source อย่าง Cline ก็ยังพึ่ง system prompt ที่เขียนมาดีอยู่ การเขียนคำสั่งที่ชัดยังมีผลต่อคุณภาพงาน เพียงแต่มันเป็นแค่ฟันเฟืองตัวหนึ่งในเครื่องจักรทั้งระบบ ไม่ใช่ทั้งเครื่องอีกต่อไป
นี่คือเหตุผลที่ทั้งสามยุคต่อกันเป็นเส้นเดียว ไม่ใช่สามค่ายที่แข่งกัน prompt engineering สอนให้สั่งงานครั้งเดียวให้ดี ส่วน context engineering สอนให้ป้อนข้อมูลรอบงานให้ครบ ขณะที่ harness engineering เป็นชั้นที่อยู่เหนือทั้งสองอย่าง คอยจัดว่าจะเรียกใช้สองอย่างนั้นในรอบไหน ด้วยข้อมูลชุดไหน และเมื่อไรถึงนับว่างานหนึ่งจบเพื่อขึ้นรอบใหม่
ที่น่าสนใจคือแนวคิดนี้ไม่ได้อยู่แค่ในโปรเจกต์ทดลองเล็ก ๆ แม้แต่ Anthropic เองก็มีตัวอย่างการทำ harness แบบเรียบง่ายอยู่ใน repo ของตัวเอง เป็น environment ที่เบาและตรงไปตรงมา และ coding agent หลายตัวที่ใช้กันอยู่ทุกวันนี้ก็ฝังชั้น harness ไว้ในตัวแอปเรียบร้อยแล้ว แม้แต่ละเจ้าจะลงรายละเอียดคนละแบบก็ตาม
ของแถมที่ต้องแลกมา
เครื่องมือทุกอย่างมีต้นทุน harness ก็เช่นกัน การเริ่มทุกรอบด้วย context สะอาดช่วยกันไม่ให้ context สะสมจนเลือนก็จริง แต่ก็แปลว่าความเชื่อมโยงข้ามรอบที่บางทีมีประโยชน์จะหายไปด้วย ทุกอย่างที่รอบถัดไปต้องรู้จึงต้องเขียนลงเอกสารงานให้ครบจริง ๆ ถ้าเอกสารที่ระบุงานไว้ตอนต้นไม่ละเอียดพอ หรือซอยงานเป็นชิ้นผิดขนาด ลูปก็เดินวนไปผิดทางได้ทั้งระบบ
พูดอีกแบบคือ harness ย้ายงานหนักจากการพยายามจำทุกอย่าง ไปไว้ที่การออกแบบเอกสารงานและกติกาว่าจะเริ่มและจบงานอย่างไรให้ดีตั้งแต่ต้น มันไม่ได้ทำให้งานง่ายลงเฉย ๆ แต่เปลี่ยนจุดที่เราต้องใส่ใจ จากเดิมที่ต้องคอยลุ้นว่า context จะล้นเมื่อไร มาเป็นการคิดให้ชัดตั้งแต่แรกว่างานทั้งหมดมีกี่ชิ้น และแต่ละชิ้นจบเมื่อไร
ใครที่อยากลองจับทางตั้งแต่วันนี้ ไม่ต้องรอเครื่องมือใหญ่โต เริ่มจากงานที่เคยสั่ง AI ทีเดียวแล้วมันทำไม่ครบ ลองแตกออกเป็นรายการงานย่อยที่เช็กได้เป็นชิ้น ๆ แล้วสั่งให้ทำทีละชิ้น เมื่อจบชิ้นหนึ่งให้บันทึกผลก่อนค่อยขึ้นชิ้นใหม่ แค่นี้ก็ได้สัมผัสหัวใจของ harness แล้ว ว่ามันคือการซอยการเดินทางไกลให้สั้นลง
ยิ่งงานยาวเท่าไร การเดินทีละช่วงด้วยหัวที่โล่ง ก็ยิ่งพาไปได้ไกลกว่าการพยายามแบกทั้งเส้นทางไว้ในความจำเดียว
ชอบเรื่องแนวนี้ มีอีบุ๊คฟรีให้อ่านต่อ
NotebookLM ฉบับเข้าใจง่าย โยนเอกสารให้ AI อ่าน แล้วได้สรุป พอดแคสต์ และคลังความรู้ส่วนตัว
กดสมัครแล้วเราจะส่งเทคนิค AI และของแจกใหม่ๆ ให้ทางอีเมล เลิกรับได้ตลอด
Claude Cowork · The Business Playbook

ฉบับภาษาไทย 15 บท เรียนรู้ผ่านโปรเจกต์จำลองต่อเนื่องทั้งเล่ม ตั้งแต่ตั้งค่า Workspace จัดการไฟล์ เชื่อมแอป ตั้งระบบอัตโนมัติ จนถึงสร้าง Plugin


