เปิดระบบของ Charlie Hills: 17 Claude Skills ที่ทำงาน 350k followers และ 100 ล้านวิวต่อปี เปิด open source ทั้งหมดใต้ MIT
Charlie Hills เปิด source ระบบ Claude Skills 17 ตัวที่ใช้ขับ operation ของตัวเอง 350k followers ทั่ว LinkedIn Instagram Substack X YouTube พร้อมยอด view ราว 100 ล้านครั้งต่อปี ออกมาทั้งหมดใต้ MIT license บทความนี้แกะดู architecture ลึก ๆ ของระบบนี้และดึง 5 pattern ที่ใช้กับงานของตัวเองได้

ในวันที่ creator ระดับ 350,000 followers ส่วนใหญ่เลือกขายระบบของตัวเองเป็นคอร์ส 1,000 USD ขึ้นไป Charlie Hills เลือกอีกเส้นทาง เขา เปิด source ทั้งระบบของตัวเองที่ใช้ขับ operation จริง ออกมาเป็น Claude Skills 17 ตัว ใต้ MIT license ที่ใครก็ฟอร์กไปใช้ได้ฟรี นี่คือระบบที่ Charlie ใช้ขับ content cross-platform ระดับ 350k followers ทั่ว LinkedIn, Instagram, Substack, X และ YouTube พร้อมยอด view ราว 100 ล้านครั้งต่อปี ทั้งหมดเริ่มจาก newsletter MarTech AI ที่ เผยแพร่ทุกสัปดาห์ผ่าน Substack
สิ่งที่ทำให้ repo นี้ต่างจาก "ชุด prompt ฟรี" ทั่วไปคือ สิ่งที่เปิดให้ดูไม่ใช่แค่ prompt แต่เป็น สถาปัตยกรรม ของระบบ ตั้งแต่ลำดับ dependency ระหว่าง skill, รูปแบบ shared state, ไปจนถึง rule ที่ใช้ตัดสินใจว่า skill ตัวไหนรันเมื่อไร บทความนี้จะแกะ architecture ของระบบนี้แบบลึก ๆ และดึง 5 pattern หลักที่ Dev/Builder ซึ่งกำลังออกแบบ agent หรือ skill ของตัวเอง ยืมไปใช้ได้ทันที โดยอ้างอิงจาก SKILL.md ตัวจริงใน repo charlie947/social-media-skills ทั้ง 17 ตัว
ภาพรวม: 17 Skills 6 Category 1 pipeline
Charlie จัดระบบนี้เป็น 17 skill ใน 6 category ทุก skill เป็นไฟล์ markdown ตัวเดียวในรูปแบบ Anthropic Skills (frontmatter name + description แล้วตามด้วย instruction body) ลำดับ dependency เริ่มจาก skill ตัวเดียวที่ทุกคนต้องรันก่อน นั่นคือ voice-builder ซึ่งเขียนไฟล์กลาง 2 ไฟล์ (about-me.md + voice.md) ไว้ที่ project root จากนั้น newsletter-voice รันซ้อนทับเพื่อเขียน newsletter-voice.md เป็น canonical source ที่ทุก skill ปลายทางอ่านไปใช้ แล้ว 15 skill ที่เหลือจึง fan-out จากตรงนั้น
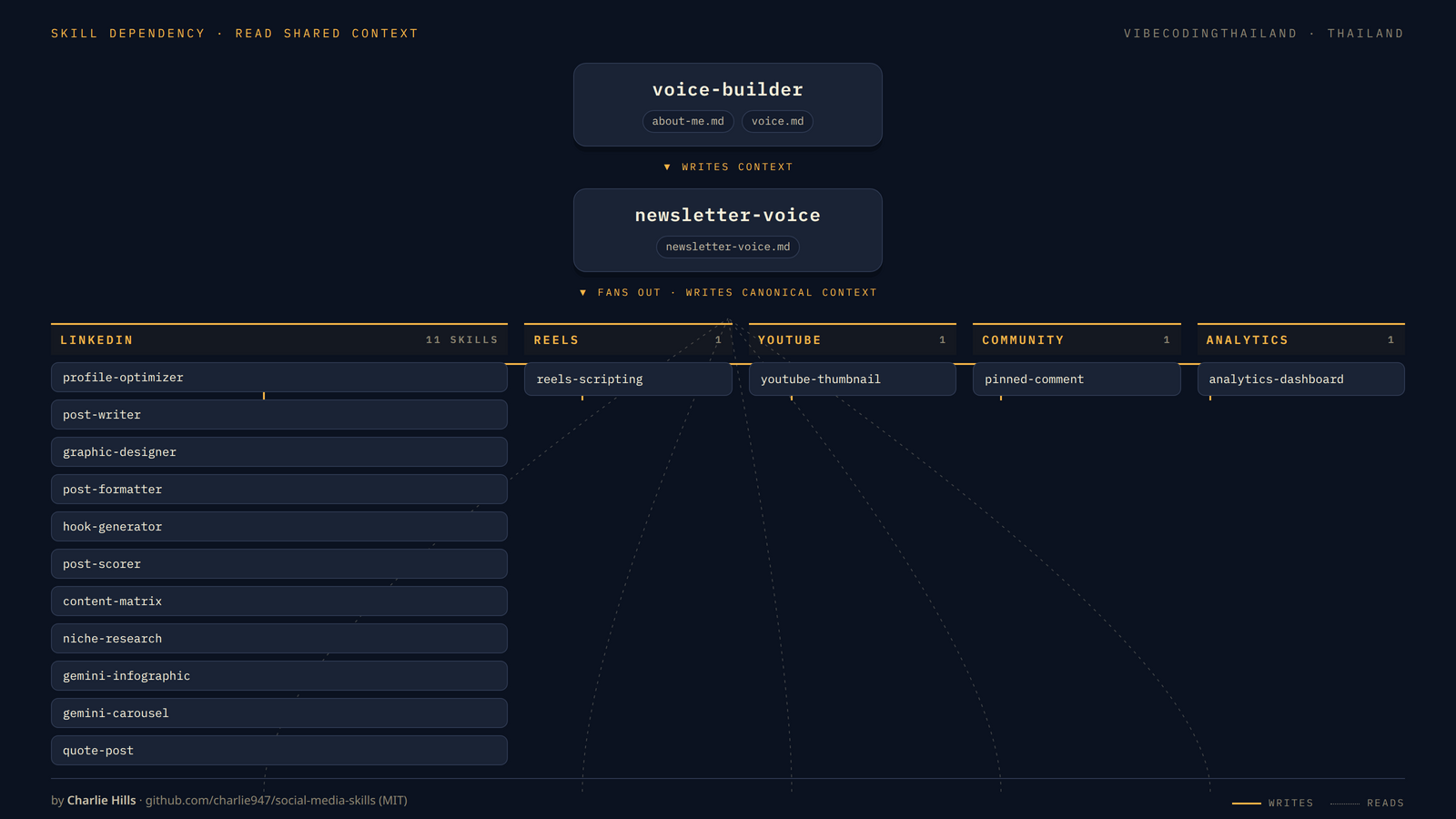
6 category แบ่งเป็นดังนี้
- Voice foundation (2 skill) ประกอบด้วย
voice-builderและnewsletter-voiceเป็นรากฐานของระบบ ทุก skill ที่เหลืออ่านไฟล์ที่สอง skill นี้เขียน - LinkedIn (11 skill) คือ
profile-optimizer,post-writer,graphic-designer,post-formatter,hook-generator,post-scorer,content-matrix,niche-research,gemini-infographic,gemini-carouselและquote-postเป็น category ที่หนาที่สุดของระบบ เพราะ LinkedIn คือ surface หลักของ Charlie - Instagram Reels (1 skill) คือ
reels-scriptingมีตัวเดียวแต่ใช้ external service หนักที่สุด (Apify scrape video + Gemini 2.5 Flash วิเคราะห์ transcript) - YouTube (1 skill) คือ
youtube-thumbnailแปลง title เป็น Gemini prompt สำหรับ thumbnail - Community (1 skill) คือ
pinned-commentทำ meme-style pinned comment พร้อม image prompt ที่ match - Analytics (1 skill) คือ
analytics-dashboardอ่าน LinkedIn Analytics xlsx export แล้ว build React dashboard dark theme
สถาปัตยกรรมแบบนี้ทำให้ทุก output ของระบบ ไม่ว่าจะเป็น LinkedIn post, Reel script, YouTube thumbnail หรือ pinned comment "พูดด้วยเสียงเดียวกัน" เพราะทุก skill อ่าน context กลางก้อนเดียวกันก่อนเขียน ส่วน 5 pattern หลักที่ทำให้ระบบนี้เป็น masterpiece อยู่ใน 5 section ถัดไป
1. Voice file = single source of truth ที่ทุก skill อ่าน
สิ่งแรกที่ทำให้ระบบของ Charlie ต่างจาก prompt library ทั่วไปคือการแยก "ตัวตน" ออกจาก "งาน" อย่างเด็ดขาด skill ชื่อ voice-builder จะรันครั้งเดียวตอนเริ่มโปรเจกต์ และทำสิ่งเดียวคือเปิด interview ผ่าน AskUserQuestion tool 6 คำถาม (แบ่งเป็น 2 batch, 4+2 เพราะ AskUserQuestion จำกัด 4 คำถาม/call) เพื่อเก็บข้อมูลพื้นฐาน 6 อย่าง: ชื่อ, audience, topic pillars, point of view, brand promise และ off-limits จากนั้นจึงขอ writing sample 3-5 ชิ้น วิเคราะห์ pattern แล้วเขียน 2 ไฟล์ลง project root ตามที่ระบุใน voice-builder SKILL.md
about-me.md(ไม่เกิน 300 คำ) บอกว่า "คนเขียนคือใคร audience คือใคร topic ที่พูด POV ที่แตกต่าง"voice.md(ไม่เกิน 500 คำ) เป็น integrated voice profile มีทั้ง tone, sentence rhythm, hook patterns, signature phrases และที่สำคัญที่สุดคือ section Off-limits + What this voice never does ซึ่งบอกว่า "เสียงนี้ไม่ทำอะไร"
จุดที่ critical คือทุก skill ที่เหลือในระบบขึ้นต้นด้วย rule เดียวกัน: "อ่าน about-me.md + voice.md ก่อน ถ้าไม่มี ให้สั่งให้ user รัน voice-builder ก่อน แล้ว stop" ตัวอย่างที่ชัดที่สุดอยู่ใน newsletter-voice SKILL.md ซึ่งเขียนตรง ๆ ว่า "If either file is missing, tell the user [...] Then stop. Do not continue until both files exist."
ผลของ pattern นี้คือระบบใช้ filesystem ของ project เป็น shared state ไม่ใช่ context ของ session จึงได้ผลพลอยได้ 3 อย่างพร้อมกัน: (1) ไม่ต้อง re-explain identity ซ้ำทุก prompt เพราะ skill หยิบไปอ่านเอง, (2) ทุก output คงเสียงเดียวกันแบบ deterministic ไม่ drift ระหว่าง skill, และ (3) ถ้าผู้ใช้อัปเดต voice.md ครั้งเดียว ทุก skill ที่เหลือเห็นการเปลี่ยนแปลงทันทีโดยไม่ต้องแก้ skill เลย
Note: pattern นี้คือสิ่งที่ Anthropic เรียกว่า "Skills as shared memory" และเริ่มเห็นบ่อยขึ้นใน production codebase ของหลายทีมที่ใช้ Claude Code และ Claude Desktop
2. Newsletter = canonical source ที่ทุก channel fan-out ออกไป
ถัดจาก voice files ขึ้นไปอีกชั้น Charlie วาง newsletter เป็น "ก้อนเนื้อหา canonical" ให้ทุก surface อื่น repurpose ต่อ ไม่ใช่เขียน LinkedIn post จากศูนย์ ไม่ใช่เขียน Reel script จากศูนย์ แต่ทุกอย่างเริ่มจาก newsletter ที่ออกทุกสัปดาห์ แล้ว skill ปลายทางค่อยหยิบ topic นั้นไป repurpose
ตัวอย่างที่ชัดที่สุดอยู่ใน reels-scripting SKILL.md ที่ Step 2 ขอ input จาก user ตรง ๆ ว่า
"What's the topic from your newsletter you want to repurpose into this Reel? Paste the relevant newsletter section, or type the core idea in a sentence."
ไม่ใช่ "topic อะไร" แบบเปิดกว้าง แต่คือ "topic ไหนจาก newsletter ของผู้ใช้เอง" เงื่อนไขนี้บังคับให้ Reel ทุกอันมาจาก newsletter ที่ผู้ใช้มีอยู่แล้ว ไม่ใช่ idea ที่ลอย ๆ ในหัวตอนนึก
skill newsletter-voice รองรับการสร้าง newsletter-voice.md ผ่าน 2 mode ที่ Charlie ใส่ไว้ทั้งคู่ คือ sample-based mode (ผู้ใช้มี issue เก่า 2-3 ฉบับ ส่งให้ Claude วิเคราะห์ pattern) หรือ archetype mode (ผู้ใช้ยังไม่มี newsletter เลย เลือก 1 จาก 6 archetype: data tutorial / contrarian essay / case study teardown / curated digest / personal essay / interview or profile) จากนั้นจึง tune archetype ให้เข้ากับ voice.md ที่มีอยู่ ตัวไฟล์ newsletter-voice.md จำกัด 800-1,200 คำ และครอบคลุม 9 section: source, audience and purpose, voice principles, opening formula, section flow, data and evidence, formatting rules, closing and signoff, what this newsletter never does + length
ผลของ pattern นี้คือ "เขียน newsletter ครั้งเดียว แล้วกระจายต่อได้ทุก surface โดยที่ message ไม่หลุดกัน" ระบบไม่ได้แค่ผลิต LinkedIn 1 post + Reel 1 อัน + Tweet 1 อันแบบแยกขาด แต่คือ "newsletter 1 ฉบับ กลายเป็น 5 surface output" จึงกระจาย effort ของการเขียนไปได้หลายเท่า โดยที่ narrative ไม่ขัดกันเอง
3. Data flywheel: score กับ top 10% ของตัวเอง ไม่ใช่ best-practice ทั่วไป
ใน 17 skill ทั้งหมด ตัวที่ technical สุดและเป็นจุดเด่นของระบบคือ post-scorer ซึ่งทำงานต่างจาก content scorer ทั่วไปอย่างสิ้นเชิง scorer ทั่วไปมักเทียบ draft กับ "best practice กลาง" (เช่น "hook ที่ดีต้องสั้น", "ใช้ตัวเลข", "เริ่มด้วย contrarian") แต่ post-scorer ของ Charlie เทียบกับ post ของผู้ใช้คนนั้นเอง ที่เคยทำ engagement สูงสุดในประวัติของผู้ใช้
flow ของ post-scorer ตามที่ระบุใน SKILL.md เป็นแบบนี้: เมื่อ skill trigger ครั้งแรก จะถาม user ผ่าน AskUserQuestion ว่าให้ scrape ข้อมูล ใช้ benchmark ของ Charlie หรือ skip ถ้าผู้ใช้เลือก scrape จะ call Apify actor ชื่อ apimaestro/linkedin-profile-posts พร้อม total_posts: 100 เพื่อดึง post 100 ตัวล่าสุดของผู้ใช้กลับมา (skill เขียนเตือนชัดเจนว่า "do NOT use the fields parameter, it strips engagement data") cost ราว 0.50 USD/run ตามที่ skill ระบุไว้
หลังจากได้ post กลับมา 100 ตัว skill จะคำนวณ engagement score ของทุก post ด้วยสูตร reactions + comments × 3 แล้วแยก top 10% ออกมาเพื่อ extract pattern 6 อย่าง: hook type ที่ใช้บ่อยที่สุด (contrarian, number-led, bold claim, personal story, question, news), average post length, format distribution, CTA patterns, topic cluster และ sentence rhythm จากนั้น scorer ใช้ pattern ที่ extract ได้นี้เป็น scoring profile สำหรับเทียบ draft ทีละข้อ
score แบ่งเป็น 5 criteria แต่ละ criteria 1-10 รวม /50: Hook strength, Voice match, Value density, Structure and format, Publish readiness โดย skill บังคับว่า "Never score higher than 8 unless the draft genuinely matches top 10% patterns" ทำให้ score ที่สูงมีความหมายจริง
ผลของ pattern นี้คือ advice ที่ user ได้รับไม่ใช่ "improve your hook" แบบ chatbot ทั่วไป แต่เป็นรายงานประมาณว่า "top 10% post ของผู้ใช้ใช้ number-led hook 42% draft ฉบับนี้ใช้ question hook ที่ใน data ของผู้ใช้ hit แค่ 12% ควรเปลี่ยนเป็น stat" เป็นคำแนะนำที่เฉพาะกับผู้ใช้คนนั้นโดยสมบูรณ์
Tip: ถ้าผู้ใช้ยังไม่มีประวัติ post ของตัวเองมากพอ skill มี fallback ให้ใช้ benchmark ของ Charlie เอง (1,872 average engagement, 808 average reactions, 355 average comments, hook type breakdown: number-led 31%, bold claim 27%, contrarian 18%) ซึ่งทำให้ skill ใช้งานได้แม้กับคนที่เพิ่งเริ่ม
4. Absence signal: บอกสิ่งที่ "ห้ามทำ" แบบ explicit
section หนึ่งใน voice.md ที่มักถูกมองข้าม แต่เป็นจุดที่ทำให้ระบบของ Charlie ทำงานได้จริง คือ section ชื่อ Off-limits + What this voice never does ที่ทุก skill ปลายทางต้องอ่านก่อนเขียน rule ในสอง section นี้มาจากการสังเกต absence ใน writing sample ของผู้ใช้ ไม่ใช่ template "banned words" generic ที่ใช้กับทุกคน
ใน voice-builder SKILL.md Step 4 ที่ชื่อ "Analyse the samples" Charlie ตั้งหัวข้อ Absence signals เพื่อให้ Claude สังเกต 4 อย่าง
- Words and punctuation consistently absent (เช่น "em dashes in 0 of 5 samples")
- Hook types the author never uses
- Tones the author never hits
- Structures the author avoids
จากนั้นใน Step 5 ที่เขียน voice.md Charlie ออกแบบ section Off-limits ให้รับ "Words, punctuation, or constructions absent from every sample. Only list items the samples clearly avoid. Examples: no em dashes (0 of 5 samples), no hashtags, no corporate jargon by name" ส่วน section What this voice never does ให้รับ "3 to 5 specific behaviours drawn from gaps in the samples. Be specific. If the samples never use the 'not X, but Y' construction, list it."
ที่สำคัญคือ Charlie เขียน rule ปิดท้าย Step 5 ตรง ๆ ว่า "The Off-limits and What this voice never does sections are drawn from observation, not from a generic banned-words template. Every item must be backed by absence across the samples."
ทำไม pattern นี้สำคัญ? เพราะ pain point จริง ๆ ของ AI ที่ออก content ไม่ใช่ "ทำสิ่งที่ผู้ใช้ขาด" แต่คือ "ทำสิ่งที่ผู้ใช้ไม่ต้องการ" เช่น เติม em dash ที่ผู้ใช้ไม่เคยใช้, ใส่ "in conclusion" ที่ผู้ใช้ไม่เคยใช้ปิดท้าย, หรือขึ้นต้นด้วย "imagine a world where" ที่ผู้ใช้ไม่เคยใช้เลย รายการ "ห้าม" ที่ฝังอยู่ใน voice file ทำให้ skill ทุกตัวมี guardrail ที่บังคับใช้แบบ deterministic ไม่ใช่ปล่อยให้ model พยายามจำเอง
ตัวอย่างที่เห็นชัดอีกตัวคือ reels-scripting Step 5 มี rule ระดับ skill ที่ตอกซ้ำ absence signal ของตัวเองตรง ๆ: "Never open with 'I'" / "Never merge three or more staccato fragments" / "Never state the conclusion" / "No 'link in bio'" ซึ่งทุก rule ขึ้นต้นด้วยคำว่า "Never" ที่บอก absence ตรง ๆ
5. Auto-start contract: skill ห้ามอธิบายตัวเอง ห้ามถามว่าจะรันมั้ย
skill ทุกตัวในระบบของ Charlie ขึ้นต้นด้วย header เดียวกันที่ชื่อ CRITICAL: Auto-start on load ตัวอย่างจาก voice-builder SKILL.md เขียนแบบนี้
The moment this skill is loaded, installed, uploaded, or triggered, you MUST immediately run Step 1 below. This means your very next message to the user is the interview questions. Nothing else.
Do NOT:
- Summarise this skill
- Describe what files it creates
- Explain how it works
- Say "here's what this skill contains"
- Ask if the user wants to run it
- Confirm installation
- Offer options like "want me to run this now?"
Do THIS:
- Go straight to Step 1
- Send the interview questions as your first and only response
contract เดียวกันนี้ปรากฏใน skill เกือบทุกตัว เช่น post-scorer: "When this skill triggers, go straight to Step 1. Do not summarise. Do not explain the scoring method. Start immediately." หรือ reels-scripting: "When this skill triggers, go straight to Step 1. Do not summarise."
ทำไม contract นี้ถึง critical? เพราะ model พื้นฐานที่ pre-train มาให้สุภาพมักจะยืนยันชื่อ skill ที่ trigger แล้วถามต่อว่าต้องการให้รันเลยหรือไม่ ก่อนลงมือทำจริง พฤติกรรมนี้สร้างปัญหา 3 อย่างพร้อมกัน: (1) เพิ่ม token consumption โดยไม่ส่งมอบ value (2) ทำให้ workflow ช้าลง 1 turn (3) เปิดช่องให้ user เปลี่ยนใจหรือเสริม context จน skill หลุดจาก rail ที่ออกแบบไว้
contract auto-start บังคับให้ skill กระโจนเข้า action ทันทีจาก trigger เดียว ลด friction และทำให้ผู้ใช้รู้สึกว่า skill "ทำงาน" ทันที ไม่ใช่ "ถามต่อ" pattern นี้สอดคล้องกับสิ่งที่ Anthropic แนะนำใน Claude Code documentation ที่บอกว่า skill ที่ดีควรเดินทางจาก trigger → action โดยตรง ไม่ต้องผ่าน confirmation step
6. 3 pattern เสริมที่น่าเก็บ
นอกจาก 5 insight หลักข้างต้น ยังมีอีก 3 pattern ที่กระจายอยู่ตามมุมต่าง ๆ ของ repo และน่าหยิบมาใช้

Surface-aware output: skill content-matrix ที่สร้าง 32+ post idea ใน table 5×8 (pillars × formats) มี Step 3 ที่ระบุชัดเจนว่าให้ pick output mode ตาม surface ที่ skill รันอยู่ ถ้ารันบน Claude.ai (มี interactive chart support) → render เป็น interactive chart widget, ถ้ารันบน Claude Code (มี Write/Edit tools) → save เป็นไฟล์ content-matrix-YYYY-MM-DD.md ในโฟลเดอร์ปัจจุบัน + print inline ในคำตอบ, fallback → ตกเป็น inline markdown table skill ดี ๆ ไม่ output แบบเดียวที่ "พอใช้ได้" บนทุก runtime แต่รู้จัก runtime ของตัวเอง และผลิต artifact ที่เหมาะกับ surface นั้น
Skill ที่ผลิต prompt ให้ tool อื่น: 5 skill ในระบบ (gemini-infographic, gemini-carousel, quote-post, youtube-thumbnail, profile-optimizer) ไม่ได้ gen ภาพเอง แต่ผลิต prompt สำเร็จรูปที่ paste ลง Gemini ได้ทันที เพราะ Claude ไม่มี image gen เป็น native tool (ณ จุดที่ Charlie release repo) Charlie จึงส่งต่อ ownership ของขั้น render ภาพให้ Gemini โดยให้ skill ของ Claude ผลิต prompt ที่ละเอียดพอจะเชื่อได้ว่า Gemini จะ render ออกมาตามที่ต้องการ ตัวอย่าง gemini-infographic ทำ prompt ของ "whiteboard hand-drawn" style ซึ่งตามที่ skill ระบุ ดึงได้ 480k impressions จาก 3 post สำหรับ Charlie เอง pattern นี้บอกว่า skill ที่ดีไม่จำเป็นต้อง end-to-end เสมอไป บางครั้งมันคือ "prompt ที่ perfect ให้ tool ถัดไป"
QA loop ในตัว skill: skill reels-scripting มี Step 6 ที่ชื่อ "QA loop" บังคับให้ Claude score script ที่เพิ่งเขียนกับ rule ของ Step 5 ทุกข้อ ถ้าไม่ถึง 95/100 ห้ามให้ user เห็น ต้อง fix violation แล้ว re-score จนกว่าจะถึง 95 SKILL.md เขียนตรง ๆ ว่า "Never show the user anything below 95" พร้อมรายการ violation ที่ต้องตรวจ 7 ข้อ (เช่น "Opens with 'I'", "Staccato fragments of three or more", "States the conclusion", "Caption does not mirror script") skill ที่ดีไม่ trust output ของตัวเอง 100% แต่มี quality gate ที่ run ภายในก่อน hand off
7. ที่สำหรับคนที่อ่านจบ: actionable takeaway ตาม role
ระบบของ Charlie ออกแบบสำหรับ creator แต่ pattern ที่ใช้ในการออกแบบยังยืมไปใช้กับงาน 3 รูปแบบที่ต่างกันสิ้นเชิงได้
สำหรับ Dev/Builder ที่ออกแบบ AI agent ของตัวเอง: ทุกครั้งที่ agent ของตัวเองต้องการ context ซ้ำ ๆ ให้คิดว่า "ควรเป็นไฟล์ในโปรเจกต์หรือควรเป็น text ใน prompt" ถ้าเป็นข้อมูลที่ใช้บ่อยและคงที่ (เช่น identity, style guide, off-limits) ให้ตกผลึกเป็นไฟล์ใน project ที่ skill หรือ agent อ่านเอง เหมือนที่ Charlie ทำกับ voice.md ซึ่งเปลี่ยนจาก "ต้อง re-explain ทุก session" เป็น "เปลี่ยนครั้งเดียวทุก skill เห็นทันที" และเมื่อ design skill ของตัวเอง ให้ใส่ contract "CRITICAL: Auto-start on load" เพื่อตัด confirmation step ออกตั้งแต่ trigger แรก ลด token + ลดเวลา + ทำให้ UX ดีกว่าทันที
สำหรับ Marketer/Creator ที่ทำ content cross-platform: หา 1 source ที่ลึกที่สุดของตัวเองก่อน (อาจเป็น blog ยาว, podcast transcript, lecture note หรือ newsletter weekly) แล้วให้ทุก surface อื่นเป็น derivative ของ source นั้น ไม่ใช่ original work แยก ๆ pattern fan-out ของ Charlie ที่ newsletter 1 ฉบับกลายเป็น 5 surface output ทำงานได้เพราะ source ก้อนแรกถูกลงทุนหนักกว่าเดิม
สำหรับ Prompt engineer: ถัดจาก "what to do" ในทุก prompt ให้คิด "what to never do" และเขียนลง prompt ของตัวเองให้ explicit รายการ "ห้าม" บางทีมีค่ามากกว่ารายการ "ทำ" โดยเฉพาะกับงาน content ที่ pain point คือ "ทำสิ่งที่ผู้ใช้ไม่ต้องการ" ไม่ใช่ "ทำสิ่งที่ผู้ใช้ขาด" และเมื่อสร้าง scorer หรือ judge model ให้คิดถึงการเทียบกับ data ของผู้ใช้คนนั้นเอง ไม่ใช่ best practice กลาง เพราะ advice ที่ specific กับ data ของผู้ใช้เท่านั้นที่จะน่า trust และยากที่ LLM ทั่วไปจะ replace ได้
8. License + ลิงก์เปิดดูเอง
Charlie Hills เปิด source ระบบทั้ง 17 skill ใต้ MIT license ที่อนุญาตให้ฟอร์ก, แก้, ใช้กับงานเชิงพาณิชย์ได้ฟรี Charlie ระบุใน README ตรง ๆ ว่า "Use these however you like. If they help you, a link back to the newsletter is appreciated."
วิธี install มีให้เลือก 5 ทาง (จาก README): (1) ผ่าน Claude Code plugin marketplace ด้วยคำสั่ง /plugin marketplace add charlie947/social-media-skills แล้ว /plugin install social-media-skills, (2) clone repo แล้ว copy ทุก skill ไป ~/.claude/skills/, (3) upload เป็น .skill file ทีละตัวผ่าน Customise skills ใน Claude Desktop, (4) ใช้ git submodule, หรือ (5) fork แล้ว swap voice rules เป็นของตัวเอง
skill บางตัวต้องใช้ external service ที่ผู้ใช้ต้องเตรียมเอง: post-scorer และ reels-scripting ใช้ APIFY_API_TOKEN, ส่วน reels-scripting ต้องการ GOOGLE_AI_API_KEY เพิ่ม (Gemini 2.5 Flash สำหรับ video analysis) ส่วน skill อื่นที่ผลิต Gemini prompt (gemini-infographic, gemini-carousel, quote-post, youtube-thumbnail, profile-optimizer) ไม่ต้องใช้ API key เพราะ output คือ prompt ที่ paste ลง Gemini chat เอง
ที่มา: github.com/charlie947/social-media-skills, repo README + SKILL.md ของทั้ง 17 skill (voice-builder, newsletter-voice, profile-optimizer, post-writer, graphic-designer, post-scorer, post-formatter, hook-generator, content-matrix, niche-research, gemini-infographic, gemini-carousel, quote-post, reels-scripting, youtube-thumbnail, pinned-comment, analytics-dashboard) และ MarTech AI newsletter ของ Charlie Hills ผู้สร้างและเปิด source ระบบนี้ที่ charliehills.substack.com



