Memory Store + Dreaming: 2 primitive ใหม่บน Claude Managed Agents ที่ทำให้ agent จดจำข้ามรอบได้จริง
Anthropic เปิดเวิร์กชอป "Agents that remember" บนช่อง Claude แสดงวิธีให้ agent บน Claude Managed Agents จดจำข้อมูลข้ามรอบได้จริงผ่าน 2 primitive ใหม่: Memory Store (file system ที่ agent อ่านเขียนข้าม session) และ Dreaming (batch process ที่จัดระเบียบ memory แบบ non-destructive ด้วยอัตรา cache hit ~95%)

ช่อง Claude ของ Anthropic เผยแพร่เวิร์กชอปชื่อ "Agents that remember" โดย Kevin วิศวกรของ Anthropic ซึ่งสาธิตวิธีให้ agent บนแพลตฟอร์ม Claude Managed Agents (CMA) จดจำข้อมูลข้าม session ได้จริง ผ่าน 2 primitive ใหม่ที่เพิ่งเปิดตัวคือ Memory Store และ Dreaming ทั้งคู่ออกแบบมาให้ทำงานร่วมกับ Session เดิม กลายเป็นสามชั้นสำหรับสร้าง agent ระดับ production ที่จำบริบทระยะยาวได้ ส่วนนี้นักพัฒนาไทยส่วนใหญ่ยังไม่คุ้น เพราะที่ผ่านมา คนทั่วไปมักรู้จัก Claude แค่ในเลเยอร์ chat อย่าง Claude.ai กับ Claude Code เท่านั้น
เวิร์กชอปยาวประมาณ 28 นาที สาธิตสดทั้งบน CLI และหน้า console ของ CMA โดยเริ่มจาก base case ที่ session ของ agent แยกขาดจนจำอะไรไม่ได้ จากนั้นต่อยอดไปยัง Memory Store ที่ทำหน้าที่เป็นความจำระยะยาว แล้วปิดท้ายด้วย Dreaming ซึ่งเป็น batch process แบบ multi-agent ที่ช่วยจัดระเบียบความจำ บทความนี้สรุปสาระสำคัญทุกประเด็นที่ Kevin อธิบายในวิดีโอเดียวกัน ดูคลิปต้นฉบับบนช่อง Claude
1. ปัญหาเดิมของ agent: session ที่ถูกตัดขาด
ในเวิร์กชอป Kevin อธิบายว่า เมื่อสร้าง agent บนแพลตฟอร์ม Claude Managed Agents วันนี้ การทำงานปกติคือสร้าง session ทีละ 1 ครั้ง และแต่ละ session แยกขาดจากกันทั้งหมด agent จึงจำข้อมูลจากรอบก่อนไม่ได้ และส่งต่อข้อมูลไปยัง session ในอนาคตไม่ได้ ข้อจำกัดนี้ลดประโยชน์การใช้งานในเวิร์กโฟลว์โลกจริงลงค่อนข้างมาก
วิดีโอแสดงให้เห็น base case ด้วยการสาธิตจริง 2 ขั้น ขั้นแรก Kevin สร้าง session ใหม่ชื่อ write test with no memory แล้วส่งข้อความให้ agent โดยใส่คีย์เวิร์ดเฉพาะคือ multi-agent orchestration outcomes in memory พร้อมแนบ URL ตัวอย่าง agent ตอบกลับเพียงว่า "ขอบคุณสำหรับข้อมูล" จากนั้นในขั้นที่สอง Kevin สร้าง session ใหม่อีกอันด้วย agent เดียวกัน แล้วถามถึงข้อมูลที่เพิ่งเล่าให้ฟัง agent ตอบทันทีว่าไม่มีสิทธิ์เข้าถึงข้อมูลนั้น พร้อมเสนอวิธีช่วยเหลือทางอื่น พฤติกรรมนี้สะท้อนข้อจำกัดพื้นฐานว่า session ทั้งสองไม่มีช่องทางส่งต่อข้อมูลให้กัน
 ภาพจากเวิร์กชอป "Agents that remember" ของช่อง Claude
ภาพจากเวิร์กชอป "Agents that remember" ของช่อง Claude
วงการ agent รู้จักปัญหานี้กันดีมาระยะหนึ่งแล้ว ถ้าจะปลดล็อกให้ agent ทำงานในบริบทระยะยาว เช่น ทีม customer service, on-call assistant, research agent หรือ sales follow-up จึงต้องมีกลไกความจำที่ persistent ข้าม session Kevin อธิบายว่านี่คือเหตุผลที่ Anthropic เปิดตัว Memory Store ขึ้นมาเป็นทางออก
2. Memory Store: file system ที่ agent อ่านเขียนข้าม session ได้
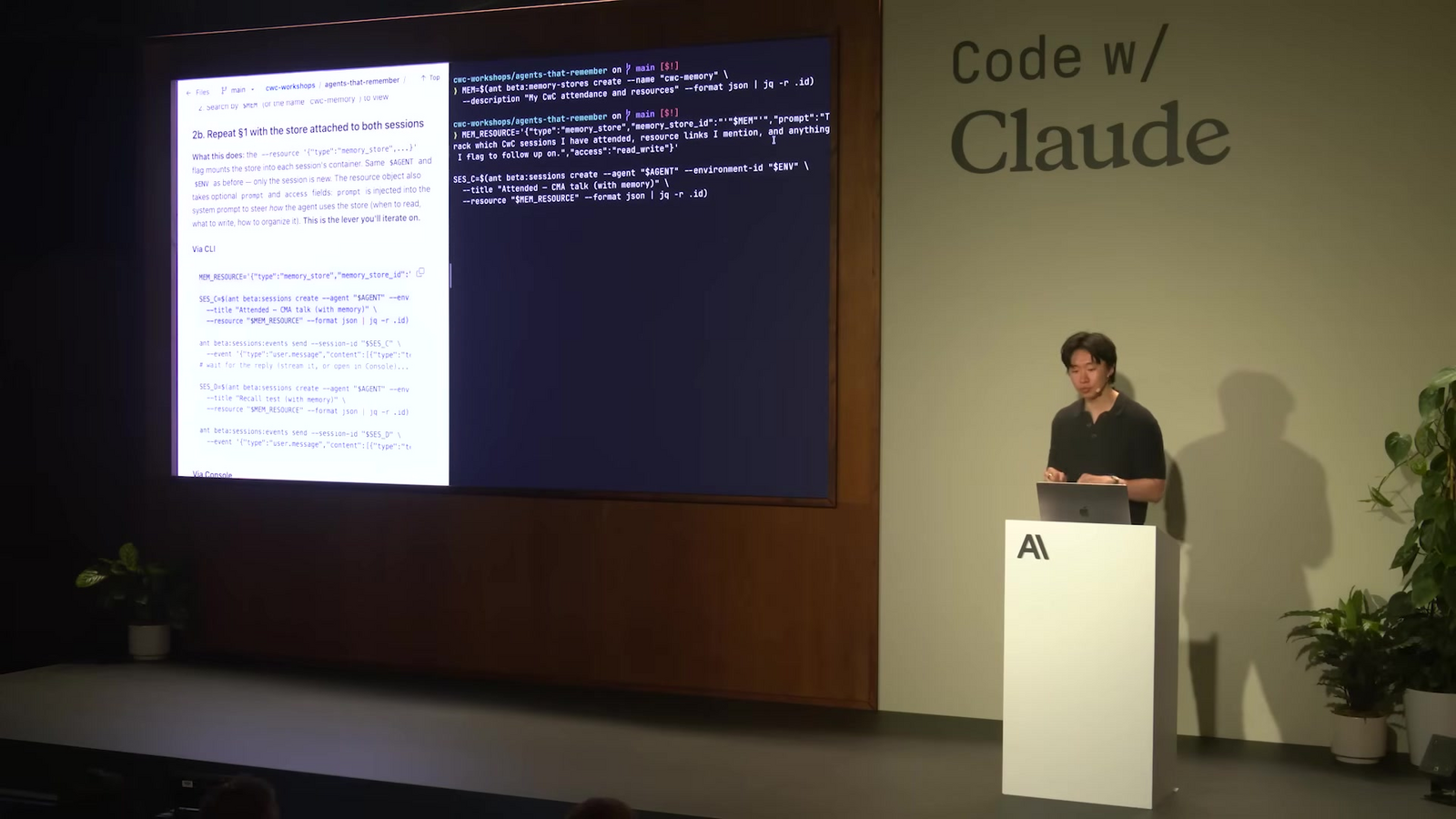
Memory Store ในแพลตฟอร์ม CMA เป็น store แบบ persistent ที่มีโครงสร้างคล้าย file system ระบบจะ mount เป็น resource เข้ากับ session ที่ผู้สร้างเลือก ทำให้ agent มีเครื่องมือสำหรับอ่านและเขียนข้อมูลในนั้นได้โดยตรง ในเวิร์กชอป Kevin อธิบายว่า Anthropic เลือกอินเทอร์เฟซแบบ file system เพราะโมเดลใช้รูปแบบนี้ได้ดีมาก agent สามารถใช้ bash สำรวจโครงสร้างไฟล์ ใช้ grep ค้นหาคีย์เวิร์ด อ่านไฟล์ และจัดการ subdirectory ได้เหมือนนักพัฒนาทำงานในเครื่องตัวเอง
ผู้สร้างกำหนดขอบเขตของ Memory Store ได้เองทั้งหมด จะใช้ store เดียวต่อทั้งองค์กร ต่อ workspace หรือต่อผู้ใช้แต่ละคนก็ได้ ในเวิร์กชอป Kevin สร้าง memory store ชื่อ CWC memory ผ่าน CLI โดยระบุชื่อกับ description สั้น ๆ จากนั้นแสดงใน console ภายใต้เมนู manage agents > memory stores ว่า store ใหม่อยู่ในสถานะ active พร้อมมี viewer แบบ file system สำหรับดูไฟล์ที่อยู่ในนั้น
 ภาพจากเวิร์กชอป "Agents that remember" ของช่อง Claude
ภาพจากเวิร์กชอป "Agents that remember" ของช่อง Claude
เมื่อต้องการใช้ memory store กับ session ผู้สร้างเพียงส่ง memory_store_id เข้าไปใน API request ของ session พร้อม parameter เพิ่มเติม 2 ตัวคือ prompt กับ access โดย prompt เป็นข้อความ steering ที่บอก agent ให้โฟกัสว่าควรอ่านหรือเขียนข้อมูลด้านไหนเป็นพิเศษ ส่วน access ระบุสิทธิ์ของ session ต่อ store ตัวนั้น ค่าเริ่มต้นคือ read_write หมายถึงอ่านและเขียนได้ และเปลี่ยนเป็น read_only ได้ เพื่อให้ session บางตัวอ่านได้แต่แก้ไขไม่ได้ วิธีออกแบบแบบนี้ทำให้ผู้สร้างควบคุมได้ละเอียดว่าจะให้ agent กลุ่มไหนแก้ไขความจำ และกลุ่มไหนเอาไปใช้อย่างเดียว
วิดีโอแสดงการทดลองขั้นแรกซ้ำอีกครั้ง แต่คราวนี้แนบ memory store ไปด้วย เมื่อ Kevin ส่งข้อความเดิมที่มีคีย์เวิร์ด CMA และ multi-agent orchestration agent กลับมีพฤติกรรมต่างออกไปทันที agent เริ่มจากเปิด memory store เพื่อตรวจสอบว่ามีข้อมูลที่เกี่ยวข้องอยู่ก่อนหรือไม่ เมื่อเห็นว่ายังว่างเปล่า ก็บันทึกข้อมูลใหม่ลงไฟล์ชื่อ sessions.md ทันที ต่อมาเมื่อสร้าง session ใหม่อีกอันด้วย memory store เดียวกันและถามถึงข้อมูลที่เพิ่งเล่าให้ฟัง agent ใช้ grep ค้นหาคีย์เวิร์ด CMA ใน memory store แล้วตอบคำถามได้ครบถ้วน นี่คือพฤติกรรมที่ก่อนหน้านี้ทำได้ยาก เพราะไม่มีเลเยอร์ persistent ที่ติดมากับตัว agent โดยตรง
นอกจากใช้กับ session แล้ว Memory Store ยังมี endpoint สำหรับตรวจสอบ store โดยตรง ผู้สร้างใช้ CLI เรียกดูรายการ memory file ทั้งหมดในนั้น ดู version history ของแต่ละไฟล์ที่ระบบสร้างอัตโนมัติเมื่อมีการแก้ไข หรือเข้า console UI เพื่อเปิดดูโครงสร้าง directory ที่ Claude สร้างขึ้นเองได้ รวมถึงแก้ไขเนื้อหาในไฟล์ด้วยมือ ถ้า Claude เขียนข้อมูลผิดหรือผู้สร้างต้องการเพิ่มข้อมูลเอง
3. Dreaming: เมื่อ agent ฝัน เพื่อจัดระเบียบความจำของตัวเอง
เมื่อ agent อ่านและเขียน memory store ต่อเนื่องไปนาน ๆ Kevin อธิบายว่าทีม Anthropic สังเกตเห็นปัญหาใหม่ คือ agent มักจะ dump ข้อมูลเข้าไปเรื่อย ๆ บันทึกทุกงานที่ได้รับมอบหมาย ทำให้ memory store โตขึ้นไม่หยุด แต่ยังไม่มีกระบวนการคอยจัดระเบียบ ตรวจสอบว่าข้อมูลส่วนไหน stale แล้ว หรือรวบข้อมูลที่ซ้ำซ้อนเข้าด้วยกัน นี่คือจุดที่ Dreaming เข้ามาแก้ปัญหา
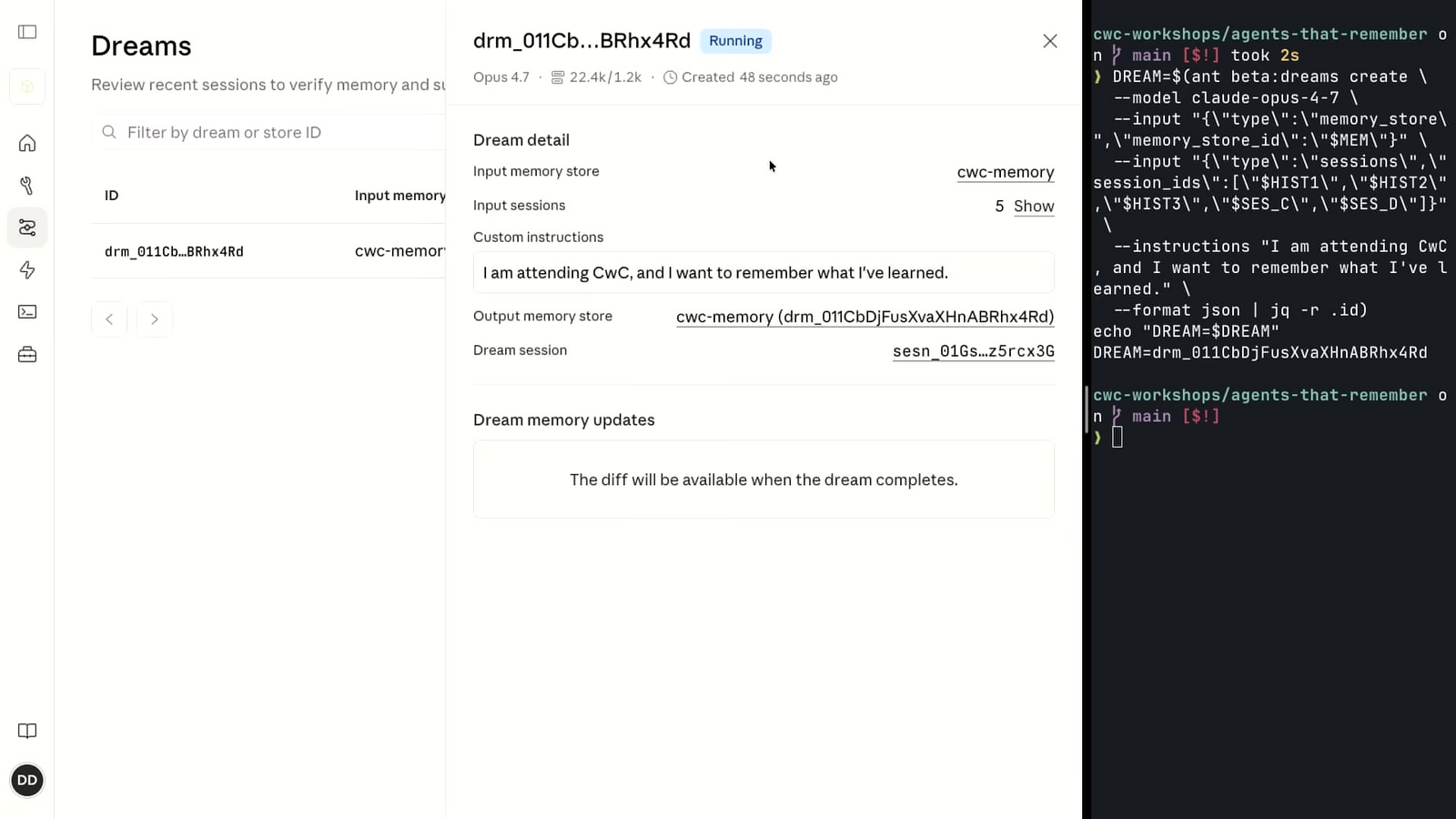
Dreaming เป็น batch process แบบ asynchronous ที่ผู้สร้างเรียกผ่าน API หรือสั่งจาก console ก็ได้ เมื่อเริ่มทำงาน ระบบจะรัน harness แบบ multi-agent ขึ้นมาอ่าน input ทั้งหมดที่กำหนดไว้ ได้แก่ memory store ต้นทาง 1 อัน และรายการ session id ของ session ในอดีตที่อยากใช้เป็นวัตถุดิบ harness จะทำหน้าที่ 4 อย่างคือ fact-checking ข้อมูลในความจำ, enrich ด้วยรายละเอียดที่ขาดหาย เช่น วันเวลา หรือ identifier เฉพาะ, ตรวจหาและรวมข้อมูลที่ซ้ำซ้อน รวมถึงจัดระเบียบไฟล์เข้า directory ใหม่ ผลลัพธ์คือ memory store ใหม่ที่ผู้สร้างเลือกนำไปใช้กับ session ในอนาคตได้ Kevin ระบุว่าสิ่งนี้ช่วยทั้งเรื่องประสิทธิภาพในการค้นข้อมูล และเพิ่มความฉลาดโดยรวมของ agent
 ภาพจากเวิร์กชอป "Agents that remember" ของช่อง Claude
ภาพจากเวิร์กชอป "Agents that remember" ของช่อง Claude
การเรียก dream job ผ่าน CLI ใช้ parameter หลัก 4 ตัว ตัวแรกคือ model ที่จะใช้ใน harness โดยเลือกได้ระหว่าง Claude Opus 4.7 หรือ Sonnet 4.6 ตามระดับคุณภาพและงบ token ที่ต้องการ ตัวที่สองคือ memory store id ของ store ต้นทาง ตัวที่สามคือรายการ session id ที่จะให้ harness อ่าน ปกติเริ่มที่ประมาณ 10-20 sessions ต่อ 1 dream แต่ระบบรองรับได้ถึง 100 และกำลังจะขยายเพิ่ม ตัวสุดท้ายคือ instruction เสริม ผู้สร้างใส่ steering prompt เพิ่มเองได้ เช่น สั่งให้เน้น back-fill รายละเอียดเฉพาะโดเมน หรือกำหนดโครงสร้าง directory ที่ต้องการให้ memory store ใช้
เมื่อสั่งงานผ่าน console ระบบจะแสดง dream job ภายใต้เมนู manage agents > dreams โดยเริ่มจากสถานะ pending แล้วเปลี่ยนเป็น running พร้อมแสดง input memory store และ token count ที่อัปเดตเรื่อย ๆ ตามที่ harness ทำงาน ระยะเวลาอาจอยู่ตั้งแต่ไม่กี่นาทีจนถึงหลายชั่วโมง ขึ้นกับขนาดและจำนวน transcript ที่ป้อนเข้าไป เหตุผลที่ออกแบบเป็น batch แบบ asynchronous คือ งานลักษณะนี้ไม่เหมาะกับการรันสด ๆ ขณะ agent ทำงานปกติ ผู้สร้างที่ใช้ผ่าน API จะใช้ endpoint สำหรับ poll สถานะ dream แทนการนั่งดูใน console
4. ทำไม Dreaming ถูกออกแบบเป็น multi-agent non-destructive ด้วย cache hit 95%
จุดออกแบบที่น่าสนใจที่สุดของ Dreaming คือการใช้สถาปัตยกรรม multi-agent ภายใน harness โดยมี orchestrator 1 ตัวทำหน้าที่ spawn sub-agent ขึ้นมา 1 ตัวต่อ input session 1 อัน เหตุผลคือทีม Anthropic ตั้งใจให้ Dreaming เป็นแบบ exhaustive by design Kevin ระบุว่าถ้าให้ harness เพียงส่วนเดียวอ่าน session 100 อัน Claude อาจมองข้ามรายละเอียดบางจุด การแบ่งงานเป็น 1 sub-agent ต่อ session ช่วยให้แต่ละ sub-agent ตรวจสอบ session ของตัวเองได้ละเอียดและครบทุกประเด็น โดย orchestrator ทำหน้าที่จัดคิวการรัน sub-agent ให้เป็นระบบ

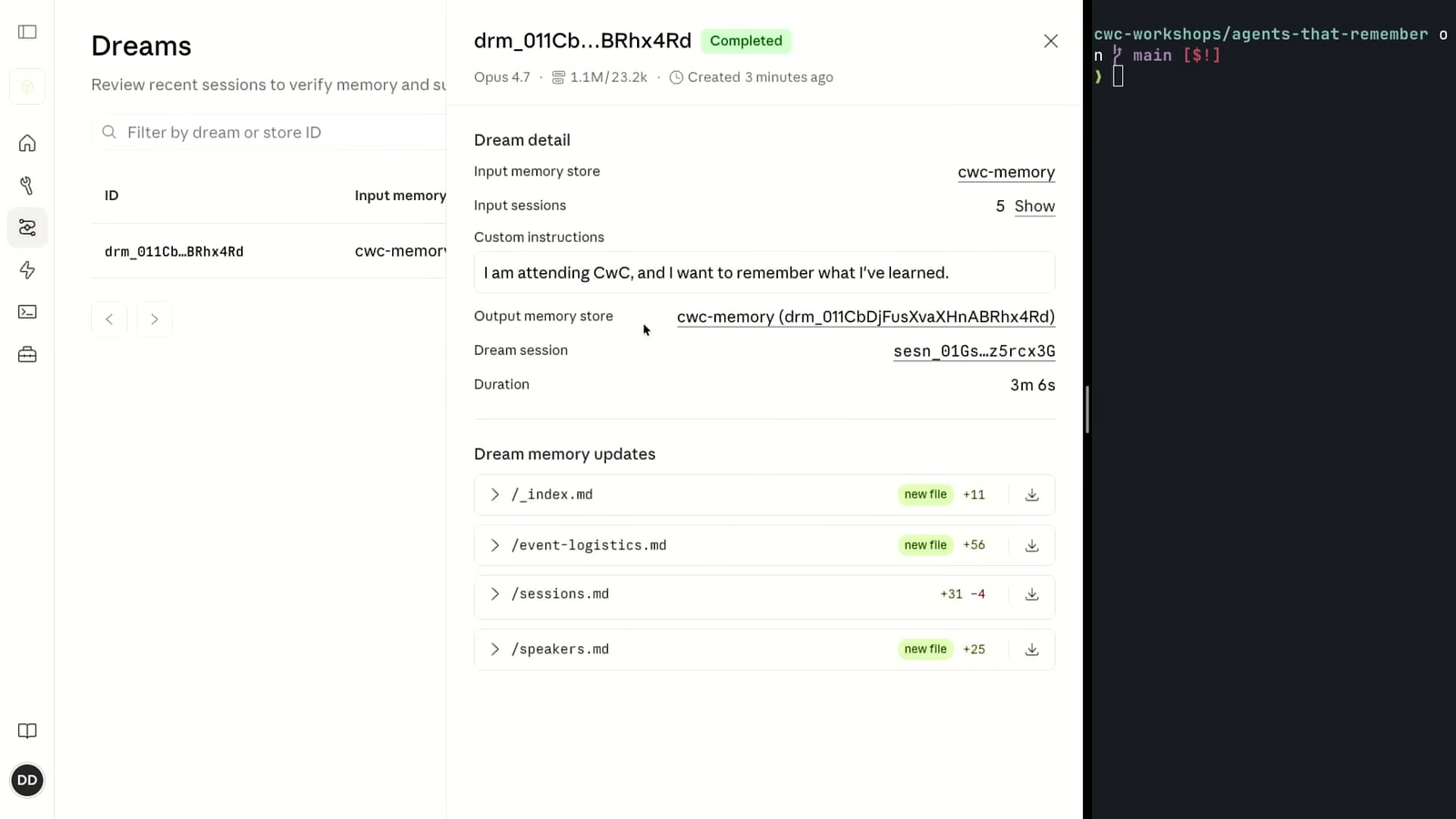
อีกคุณสมบัติที่ Kevin ย้ำในเวิร์กชอปคือ Dreaming เป็นแบบ non-destructive ระบบจะไม่แตะ memory store ต้นทางที่ผู้สร้างป้อนเข้าไปเลย แต่จะ clone ออกมาเป็น output memory store ใหม่ การแก้ไขทั้งหมดของ dream job จะเกิดในตัว clone นี้เท่านั้น เมื่อ dream job ทำงานเสร็จ console จะแสดงผลเป็น diff ของไฟล์ที่สร้างขึ้น แก้ไข หรือจัดกลุ่มใหม่ การออกแบบนี้เปิดทางให้มี human-in-the-loop เข้ามาตรวจสอบและตัดสินใจว่าจะนำ output memory store ไปใช้แทนของเดิมหรือไม่ ก่อนที่ session ในอนาคตจะ mount เข้ามาใช้
 ภาพจากเวิร์กชอป "Agents that remember" ของช่อง Claude
ภาพจากเวิร์กชอป "Agents that remember" ของช่อง Claude
ในการสาธิตจริง dream job ที่ Kevin รันให้ output ที่น่าสนใจ 3 ประเภท ประเภทแรกคือไฟล์ INDEX ที่ harness สร้างขึ้นใหม่ บรรจุ slug ของไฟล์ความจำต่าง ๆ เพื่อให้ session ในอนาคตอ้างอิงได้รวดเร็วโดยไม่ต้องเสียเวลา grep ทั้ง store ประเภทที่สองคือไฟล์ใหม่ที่ enrich ข้อมูลเพิ่ม เช่น event logistics ที่บรรจุตารางเต็มของงาน Code with Claude พร้อมรายชื่อและกำหนดการของวันที่ 2 ซึ่งไม่ปรากฏใน session แรก ๆ ที่เป็น input ประเภทที่สามคือไฟล์เดิมที่จัดรูปแบบใหม่ เพิ่ม slug เพิ่ม description เพิ่ม metadata ทำให้ไฟล์เดิมที่เคยสั้น ๆ มีโครงสร้างพร้อมต่อยอด Kevin ระบุว่าหลักการคือ ยิ่งเขียนรายละเอียดลงไว้มาก session ในอนาคตยิ่งหยิบใช้ได้ตรง เพราะตอน agent กำลังทำงานอยู่ เป็นเรื่องยากที่จะคาดเดาว่ารายละเอียดไหนจะจำเป็นในอนาคต ส่วนข้อมูลที่ไม่จำเป็นแล้ว Dreaming ในรอบถัดไปจะลบทิ้งเองได้
ในเชิงต้นทุน Dreaming เป็นฟีเจอร์ที่ใช้ token ค่อนข้างมาก เพราะออกแบบมาให้ exhaustive แต่จุดที่ทำให้ใช้งานระดับ production ได้จริงคืออัตรา cache hit ที่สูงประมาณ 95% เพราะกระบวนการส่วนใหญ่เป็นงาน agentic ที่อ่าน context ซ้ำกันได้ Kevin ระบุว่า Anthropic กำลังพิจารณาแนวทางลดต้นทุนเพิ่มเติม ทั้งการเสนอ Dreaming แบบ batch ที่มีส่วนลด 50% คล้าย batch API ที่มีอยู่แล้ว การให้ผู้สร้างเลือกโมเดลและ token budget ได้ละเอียดขึ้น รวมถึงเปิดให้ steer prompt ของ dream harness ได้ตามต้องการ
อีกประเด็นที่ Kevin เน้นคือ dream job เองก็สร้างจาก primitive ของ CMA หมายความว่า dream job คือ session ปกติ 1 อัน ผู้สร้างจึงคลิกเข้าไปดูได้ทั้ง system prompt ที่ harness ใช้ ลำดับการเรียก sub-agent และทุกขั้นตอนภายใน ทำให้มี observability สำหรับ diagnose ปัญหาได้เต็มที่ ต่างจาก agent infrastructure หลายตัวที่ปิดเป็นกล่องดำให้ผู้สร้างใช้งานอย่างเดียว
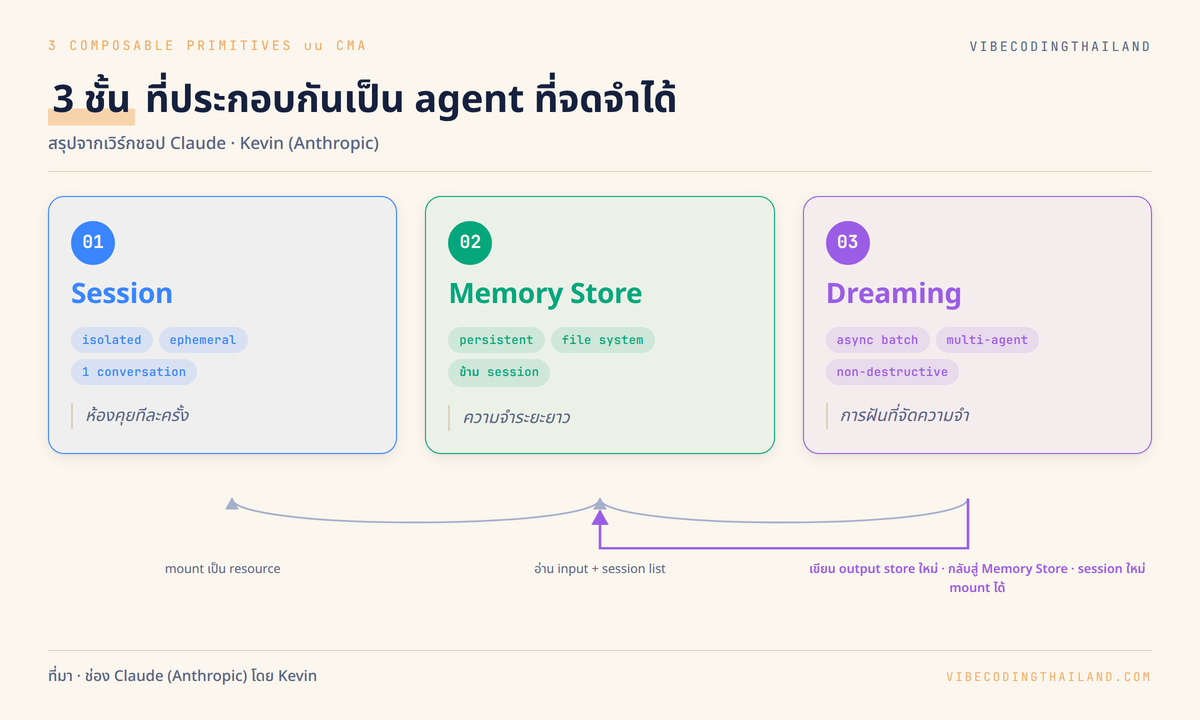
5. Session + Memory Store + Dreaming: 3 ชั้นที่ประกอบกันเป็น agent ที่จำได้จริง
Kevin สรุปภาพรวมของฟีเจอร์ใหม่ทั้งหมดด้วยมุมมอง 3 ชั้นที่ประกอบเข้าด้วยกัน ชั้นแรกคือ Session ซึ่งเป็น isolated instance ของ agent ที่รัน 1 conversation ปกติและยัง ephemeral ตามเดิม ชั้นที่สองคือ Memory Store ซึ่ง augment ให้ session แต่ละอันต่อข้อมูลถึงกันได้ข้ามรอบ และชั้นที่สามคือ Dreaming ซึ่งจัดระเบียบและ enrich memory store ให้สดใหม่ ไม่บวมจนรับมือไม่ไหวเมื่อจำนวน session กับปริมาณข้อมูลขยายตัวขึ้น
วิดีโอแสดงให้เห็นพลังของชั้นที่สามด้วยการสาธิตปิดท้าย Kevin สร้าง session ใหม่โดย mount output memory store ที่ได้จาก dream job จากนั้นถามคำถามรวบรัด 3 ข้อคือ session ไหนที่เคยเข้า resource ไหนบ้างที่มีลิงก์ และ follow-up อะไรที่เคย flag ไว้ agent เริ่มอ่าน memory โดยอิงไฟล์ INDEX ก่อนเพื่อให้รู้ว่าควรไปไฟล์ไหน แล้วอ่าน sessions.md กับ event logistics ตามที่ index บอก ผลลัพธ์ที่ตอบกลับมามีรายละเอียดมากกว่ารอบที่ยังไม่ได้ dream อย่างเห็นได้ชัด ทั้งรีแคปของทุก session ที่เคยเข้า timestamp ของ session วันที่ 2 และลิงก์ resource ครบทุกตัว Kevin สรุปว่านี่แสดงให้เห็นว่า Dreaming ช่วย enrich ข้อมูลที่ส่งต่อระหว่าง session ได้จริงในระดับใช้งานได้
สำหรับนักพัฒนาและผู้สร้าง agent ในไทย Claude Managed Agents ยังเป็นเลเยอร์ที่หลายคนไม่คุ้น เพราะที่ผ่านมาส่วนใหญ่รู้จัก Claude แค่ในรูปแบบ chat อย่าง Claude.ai กับ Claude Code เท่านั้น แต่ Memory Store กับ Dreaming คือ primitive ที่ปลดล็อกให้สร้าง agent ระดับ production ที่จำบริบทระยะยาวได้ ครอบคลุมเคสที่ระบบเดิมยังทำได้ยาก เช่น agent ดูแลลูกค้าที่จำประวัติการสนทนาของผู้ใช้แต่ละราย, on-call assistant ที่จำ context ของ incident ก่อนหน้า, research agent ที่สะสมความรู้เฉพาะโดเมน หรือ sales follow-up ที่จำเงื่อนไขของลูกค้าได้ครบ การประกอบ session ที่แยกขาดเข้ากับ memory ที่ต่อข้อมูล และ Dreaming ที่คอยจัดบ้านให้เป็นระเบียบ คือกลไกที่เปลี่ยน agent จากของเล่น chat ทั่วไป ให้กลายเป็นซอฟต์แวร์ที่ใช้ทำงานจริงในระยะยาวได้
ที่มา: Agents that remember โดยช่อง Claude (Anthropic) YouTube workshop



