ADHD สกิลที่ทำให้ AI สายโค้ดคิดหลายทางก่อนตอบ ตรวจจับกับดักได้ดีกว่าการตอบรวดเดียว 5.2 เท่า
ADHD คือสกิลโอเพนซอร์สที่ทำให้ AI สายเขียนโค้ดแยกแนวคิดออกเป็นหลายเส้นทางคู่ขนานก่อน แล้วค่อยตัดทางที่เป็นกับดักทิ้ง จุดต่างคือมันยอมบอกว่าคำตอบที่ดูดีพังตรงไหน ไม่ใช่แค่ฟันธงคำตอบแรกที่นึกออก

ลองนึกถึงโจทย์จริงข้อหนึ่ง: มี CLI ตัวหนึ่งที่เรียก LLM แล้วบางครั้งค้างไป 90 วินาที ควรวางกลยุทธ์ retry กับ timeout ยังไงให้ดี ถ้าโยนคำถามนี้ให้ AI สายเขียนโค้ดตอบรวดเดียว คำตอบที่ได้มักจะเข้าท่า: ไล่ดู pattern มาตรฐานสี่แบบ แล้วลงเอยที่สูตรผสม timeout 15 วินาทีสำหรับ token แรก · 30 วินาทีระหว่าง token · 90 วินาทีเป็นเพดานสุดท้าย · retry อัตโนมัติหนึ่งครั้ง ฟังดูเหมือนคำตอบที่วิศวกรอาวุโสให้ได้ภายใน 30 วินาที แต่สิ่งที่หายไปคือ มันไม่เคยบอกเลยว่ากับดักอยู่ตรงไหน ไม่ถามด้วยซ้ำว่าผู้ใช้อาจอยากกดยกเลิกคำขอที่ช้าเอง และไม่ตั้งคำถามกับกรอบคิด "รอแล้วก็ยิงโมเดลเดิมซ้ำ" สักนิด
นั่นคือปัญหาที่ ADHD ตั้งใจแก้ ADHD เป็น "skill" โอเพนซอร์สสำหรับ coding agent อย่าง Claude Code · Codex · Cursor และอีกหลายตัว ที่เปลี่ยนวิธีคิดของ AI จากการเดินความคิดเป็นเส้นเดียวแล้วฟันธง มาเป็นการแตกความคิดหลายเส้นขนานกันก่อน ให้คะแนน ตัดเส้นที่เป็นกับดักทิ้ง แล้วค่อยเจาะลึกเฉพาะเส้นที่รอด ตัวเลขที่น่าสนใจที่สุดอยู่ตรงนี้: ในการวัดผล ความสามารถ "ตรวจจับกับดัก" ของ ADHD สูงกว่าการตอบรวดเดียวถึง 5.2 เท่า
ทำไมคิดเป็นเส้นเดียวแล้วมักพลาด
รากของปัญหาอยู่ที่วิธีที่โมเดลภาษาคิดทีละคำ พอมันพิมพ์คำแรกออกมา คำถัด ๆ ไปก็มักต้องสอดคล้องกับสิ่งที่พูดไปแล้ว ภาษาทางเทคนิคเรียกอาการนี้ว่า premature convergence คือยึดติดกับทิศทางแรกที่นึกออกเร็วเกินไป Chain-of-Thought แบบให้ AI "คิดทีละขั้น" ก็ยังหนีอาการนี้ไม่พ้น เพราะมันก็ยังเดินอยู่บนเส้นความคิดเส้นเดิม
หลายคนเลยหันไปใช้ Tree-of-Thought ที่แตกกิ่งความคิดออกเป็นหลายทาง ฟังดูน่าจะแก้ได้ แต่ปัญหาคือกิ่งพวกนั้นยัง แชร์ context ก้อนเดียวกัน ทุกกิ่งจึงเห็นสิ่งที่กิ่งอื่นคิดไปแล้ว การยึดติดเลยไม่ได้หายไป มันแค่กระจายไปทั้งต้นไม้ สุดท้ายทุกกิ่งก็เอนไปทางคำตอบแรกอยู่ดี
จุดที่ ADHD มองต่างคือ มันถือว่านี่เป็น ปัญหาเชิงสถาปัตยกรรม ไม่ใช่ปัญหาการเขียน prompt การบอก AI ว่า "ช่วยคิดหลายๆ มุมหน่อยนะ" ในคำสั่งเดียวไม่พอ เพราะทุกมุมยังเกิดในหัวเดียวกัน ทางแก้จริงคือต้องแยกกระบวนการคิดออกจากกันตั้งแต่ระดับโครงสร้าง ไม่ใช่แค่ขอร้องในประโยคเดียว
สองจังหวะที่มีกำแพงกั้นกลาง

กลไกของ ADHD เป็นลูปสองจังหวะ โดยมีกำแพงแข็ง ๆ คั่นระหว่างสองจังหวะนั้น
จังหวะแรกคือ Diverge — เลือกกรอบคิดมา N กรอบ แล้วยิงเป็น Agent call ที่แยกขาดจากกัน N ชุดพร้อมกัน แต่ละชุดเห็นแค่ตัวโจทย์กับมุมมองของกรอบตัวเองเท่านั้น พร้อมคำสั่งระบบที่ห้ามประเมินผลใด ๆ ในขั้นนี้ หัวใจอยู่ที่ว่าแต่ละเส้น ไม่เห็นกันเลย ไม่มีเส้นไหนแชร์ context กัน การยึดติดจึงไม่มีทางเกิด เพราะไม่มีคำตอบแรกของใครให้เอนตามตั้งแต่ต้น
จังหวะที่สองคือ Focus — มี critic อีกตัวแยกออกมารับบทผู้วิจารณ์ มันให้คะแนนทุกไอเดียในสามแกน (ความแปลกใหม่ · ความเป็นไปได้จริง · ความเข้ากับโจทย์) ชี้ว่าอันไหนเป็นกับดักพร้อมเหตุผล จับกลุ่มไอเดียที่มาจากมุมเดียวกันเข้าด้วยกัน แล้วเจาะลึกเฉพาะเส้นที่ได้คะแนนดีที่สุดให้กลายเป็นแบบร่างที่มีทั้งความเสี่ยงและก้าวแรกที่ลงมือได้
จุดที่ทำให้กลไกนี้ต่างจากการเขียน prompt เฉยๆ คือการแยกบทผู้คิดกับผู้วิจารณ์ออกจากกันแบบจริงจัง
ลองย้อนกลับไปที่โจทย์ CLI ค้าง 90 วินาทีตอนต้น เมื่อรันผ่าน ADHD มันแตกออกเป็น 6 กรอบคิดที่แยกจากกัน แล้วโยนไอเดียออกมากว่า 30 อันในมิติที่กว้างกว่าเดิมมาก ไม่ใช่แค่เรื่อง timeout กับ retry แต่รวมถึงทางที่คำตอบรวดเดียวมองข้ามไป เช่น การให้ผู้ใช้กดยกเลิกเอง หรือการตั้งคำถามกับการยิงโมเดลเดิมซ้ำ
ตัวเลขที่บอกว่าต่างจริงตรงไหน
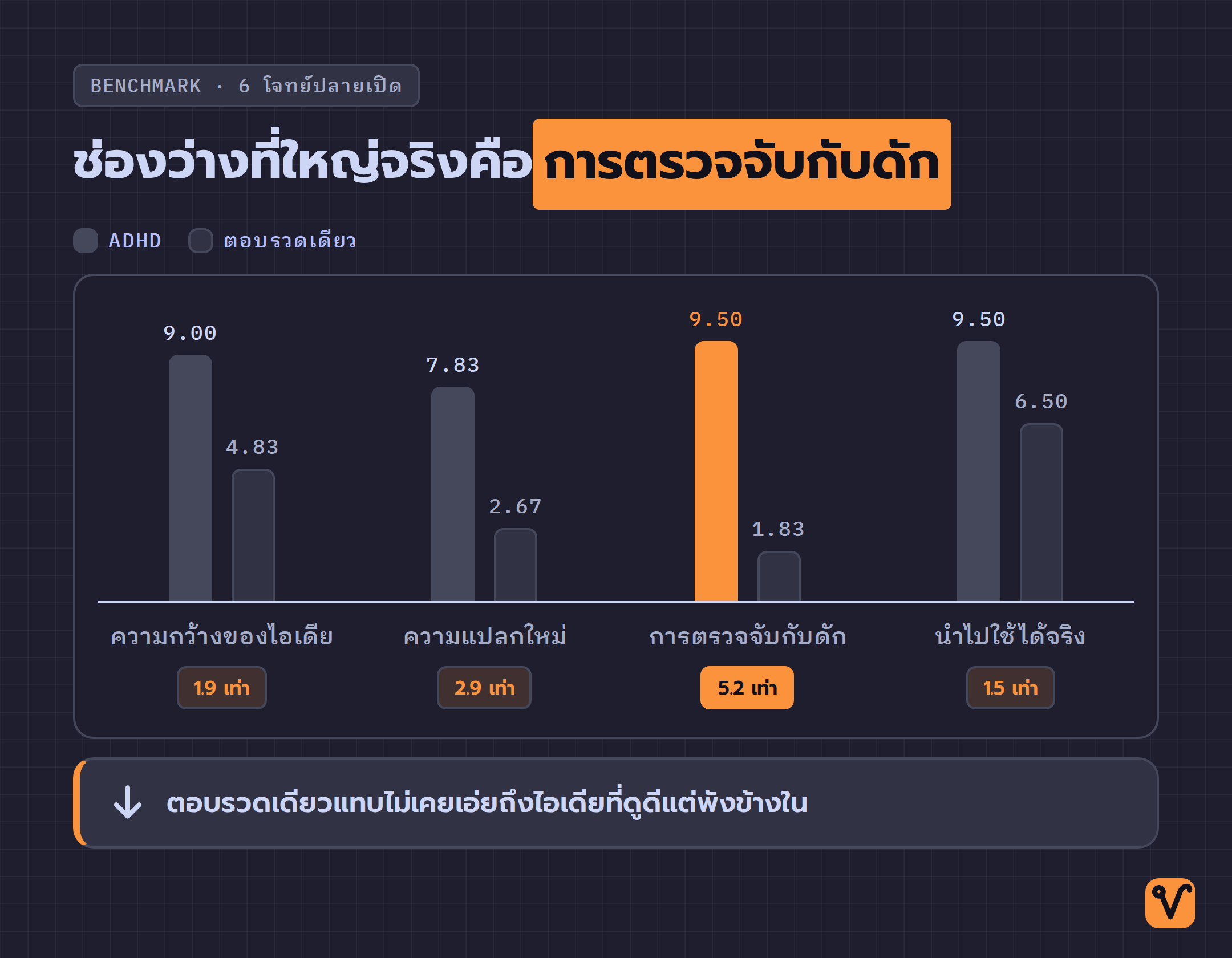
ทีมผู้สร้างวัดผลด้วยโจทย์วิศวกรรมปลายเปิด 6 ข้อ ใช้โมเดลตัวเดียวกันทั้งสองฝั่ง ให้ LLM อีกตัวเป็นกรรมการตัดสินด้วยมุมมองวิศวกรอาวุโสที่ขี้สงสัย และสุ่มสลับลำดับ A/B เพื่อกันอคติ ผลคือ ADHD ชนะ 5 จาก 6 ข้อ และนี่คือคะแนนเฉลี่ยเทียบกับการตอบรวดเดียว
| มิติที่วัด | ADHD | ตอบรวดเดียว | ต่างกัน |
|---|---|---|---|
| ความกว้างของไอเดีย | 9.00 | 4.83 | 1.9 เท่า |
| ความแปลกใหม่ | 7.83 | 2.67 | 2.9 เท่า |
| การตรวจจับกับดัก | 9.50 | 1.83 | 5.2 เท่า |
| ความนำไปทำได้จริง | 9.50 | 6.50 | 1.5 เท่า |
ช่องว่างที่ใหญ่ที่สุดคือการตรวจจับกับดัก ซึ่งสูงถึง 5.2 เท่า เหตุผลตรงไปตรงมา: การตอบรวดเดียวแทบไม่เคยเอ่ยถึงไอเดียที่ "ดูดีแต่พังข้างใน" เลย มันมักหยิบคำตอบที่ฟังเข้าท่าที่สุดมาเสนอ โดยไม่บอกว่าอันไหนเป็นหลุมพราง ส่วนความกว้างและความแปลกใหม่ที่ทิ้งห่างหลายเท่า ก็มาจากการปล่อยให้แต่ละเส้นคิดโดยไม่เห็นกันโดยตรง
คุณค่าที่แท้จริงไม่ใช่ AI ตอบเร็วขึ้น แต่คือมันยอมบอกว่าคำตอบที่ดูดีที่สุดนั้นพังตรงไหน
เริ่มใช้กับ agent ของตัวเองวันนี้
ข้อดีคือการลองใช้จริงไม่ได้ยุ่งยากเลย ติดตั้งด้วยคำสั่งเดียวที่ตรวจหา agent ให้อัตโนมัติ รองรับทั้ง Claude Code · Cursor · Codex · Cline · Gemini CLI · Windsurf และอีกราว 50 ตัว โดยตัวสกิลและเอกสารทั้งหมดอยู่ที่ repository ของ ADHD บน GitHub
เริ่มต้นสั้น ๆ ได้สามขั้น:
- ติดตั้งสกิลด้วยคำสั่ง
npx skills add UditAkhourii/adhd - เรียกใช้ตรงๆ ตอนเจอโจทย์ที่อยากให้คิดหลายทาง ด้วย
/adhd "โจทย์ของคุณ"หรือปล่อยให้มันเด้งขึ้นมาเองเมื่อจับได้ว่ากำลังหาไอเดีย - ถ้าอยากปรับจำนวนเส้น ใช้ผ่าน CLI ได้ เช่น
adhd "ตั้งชื่อฟังก์ชันนี้" --frames 3 --ideas 8 --top 2คือแตก 3 กรอบ · เสนอ 8 ไอเดีย · เก็บ 2 อันที่ดีที่สุด
ถ้าใช้ Codex แล้วคำสั่งทั่วไปด้านบนลงทะเบียนสกิลไม่สำเร็จ (Codex บางรุ่นหาสกิลจาก path เฉพาะ) ให้ระบุเป้าหมายเป็น Codex โดยตรงด้วย npx skills add UditAkhourii/adhd -a codex -g แทน เท่านี้ก็เรียก /adhd ได้ตามปกติ
ไม่ใช่ทุกงานที่ควรใช้
ของแบบนี้มีต้นทุนเสมอ และ ADHD ก็ตรงไปตรงมาเรื่องนี้ มันไม่ได้ออกแบบมาให้ใช้กับทุกโจทย์ ถ้างานนั้นมีคำตอบที่ถูกต้องชัดเจนอยู่แล้ว เช่น แก้ syntax error หรือทำตามสเปกที่นิ่งแล้ว การแตกความคิดหลายเส้นก็เปลืองเปล่า เพราะมันต้องยิง LLM หลายชุดแทนที่จะยิงชุดเดียว ทั้งช้ากว่าและกินทรัพยากรมากกว่าการตอบรวดเดียวโดยธรรมชาติ
คุณค่าของมันจึงโผล่มาเฉพาะตอนที่ "การมองข้ามทางเลือกที่ดีกว่า" แพงกว่า "การคิดหลายเส้น" เท่านั้น ตอนออกแบบสถาปัตยกรรมที่เลือกผิดแล้วต้องรื้อใหม่ ตอนไล่บั๊กที่เดาต้นตอผิดแล้วเสียเวลาทั้งวัน นั่นคือจังหวะที่การยอมจ่ายเพิ่มอีกหลายชุดความคิดคุ้มที่สุด เครื่องมือนี้สร้างโดย UditAkhourii ผู้เขียน preprint และดูแลโปรเจกต์ ภายใต้สัญญาอนุญาต MIT ที่เปิดให้นำไปต่อยอดได้เต็มที่
ถ้าจะสรุปด้วยประโยคเดียว ADHD ไม่ได้ทำให้ AI ฉลาดขึ้น แต่บังคับให้มัน ไม่เห็นความคิดของตัวเองก่อน เพราะพอแต่ละเส้นไม่รู้ว่าเส้นอื่นคิดอะไร มันถึงกล้าเดินไปทางที่คำตอบแรกไม่มีวันพาไป
ที่มา: ADHD: a skill for coding agents โดย UditAkhourii
ชอบเรื่องแนวนี้ มีอีบุ๊คฟรีให้อ่านต่อ
สร้าง Claude Skill แบบไม่ต้องรู้โค้ด คู่มือสร้าง Claude Skill ของคุณเองด้วยการคุยกับ Claude Code เป็นภาษาไทย
กดสมัครแล้วเราจะส่งเทคนิค AI และของแจกใหม่ๆ ให้ทางอีเมล เลิกรับได้ตลอด
Claude Cowork · The Business Playbook

ฉบับภาษาไทย 15 บท เรียนรู้ผ่านโปรเจกต์จำลองต่อเนื่องทั้งเล่ม ตั้งแต่ตั้งค่า Workspace จัดการไฟล์ เชื่อมแอป ตั้งระบบอัตโนมัติ จนถึงสร้าง Plugin


