GLM 5.2 จาก Zhipu AI ทุบสถิติ benchmark แต่พอสั่งให้เขียนเกมจริง กลับเดินในเกมไม่ได้
GLM 5.2 โมเดลใหม่จาก Zhipu AI ทำคะแนน benchmark สูงจนได้ที่ 1 ด้าน reasoning และทำคะแนนเต็มครั้งแรกในประวัติศาสตร์ แต่พอเอามาสั่งเขียนเกมจริง ผลที่ได้กลับเปิดขึ้นมาแล้วเล่นไม่ได้ บทความนี้ชวนดูว่าช่องว่างนั้นบอกอะไรกับคนที่อยากใช้ AI เขียนโค้ด

GLM 5.2 โมเดลใหม่จาก Zhipu AI (ZAI) ทำคะแนนสอบทะลุเพดานในแทบทุกด้าน ได้ที่ 1 ด้าน reasoning แซงโมเดลตัวท็อปของฝั่งตะวันตก เร็วขึ้นจากรุ่นก่อนเกือบ 3 เท่า และทำคะแนนเต็ม 100% ในการวัดบางตัวเป็นครั้งแรกในประวัติศาสตร์ของ benchmark นั้น ตัวเลขสวยขนาดนี้ฟังดูเหมือนโมเดลที่เปลี่ยนเกมได้เลย
แต่พอมีคนซื้อแผนรายเดือนมาลองสั่งให้มันเขียนเกมจริงๆ เรื่องกลับไม่ได้สวยตาม เกมผีที่สั่งสร้างเปิดขึ้นมาได้ แต่หาทางออกไม่เจอแม้จะเก็บกุญแจครบ เกมแนว Minecraft ที่ได้มาก็เปิดหน้าจอได้ แต่เดินไม่ได้สักก้าว ช่องว่างระหว่าง "คะแนนสอบสวย" กับ "ของที่ใช้ได้จริง" นี่แหละคือเรื่องที่น่าสนใจที่สุดของ GLM 5.2 และเป็นบทเรียนที่ใช้ได้กับการเลือก AI มาเขียนโค้ดแทบทุกตัว
เปิดตัวในจังหวะที่ฉลาด
GLM 5.2 เปิดตัวเมื่อวันที่ 13 มิถุนายน 2026 แบบไม่มีปี่มีขลุ่ย และจังหวะที่เลือกก็ไม่ธรรมดา เพราะมันเปิดตัวในวันเดียวกับที่โมเดลใหญ่สองตัวของฝั่งตะวันตกถูกรัฐบาลสหรัฐฯ สั่งห้ามเข้าถึง ZAI หยิบช่องว่างตรงนั้นมาทำการตลาดทันที ด้วยสโลแกนทำนองว่าอนาคตของ AI ต้องเปิดกว้างและทุกคนเข้าถึงได้
ในแง่กลยุทธ์ต้องยอมรับว่าอ่านเกมขาด ช่วงที่คนกำลังกังวลว่าจะเข้าถึงโมเดลตัวเก่งไม่ได้ การโผล่มาพร้อมข้อความว่า "เปิด เข้าถึงง่าย ของทุกคน" ย่อมสะดุดหู แต่คำว่าเปิดตรงนี้ต้องอ่านให้ละเอียด เพราะ GLM 5.2 ไม่ได้เปิดให้ใช้ฟรีผ่าน chatbot หรือ API ทั่วไป
จะแตะตัวโมเดลได้ ต้องเป็นสมาชิกแผน GLM coding plan เท่านั้น และราคาแผนนี้ตอนนี้อยู่ที่ 65 ดอลลาร์ต่อเดือน ซึ่งเพิ่งขึ้นมาจาก 35 ดอลลาร์เมื่อไม่กี่เดือนก่อน เท่ากับขึ้นราคาเป็นเท่าตัว คำว่า "ของทุกคน" จึงมีค่าเข้าชมติดอยู่
ตัวเลขที่ทำให้คนอยากลอง
ก่อนจะไปถึงงานจริง ลองดูตัวเลขที่ทำให้โมเดลนี้เป็นที่พูดถึงก่อน เพราะมันสวยจริง
ด้านความเร็ว GLM 5.2 ทำได้ 296 tokens ต่อวินาที ขณะที่รุ่นก่อนหน้าอย่าง GLM 5.1 อยู่ที่ราว 84 tokens ต่อวินาที เท่ากับเร็วขึ้นเกือบ 3 เท่าในรุ่นเดียว ส่วนด้านการให้เหตุผล มันขึ้นไปอยู่อันดับ 1 แซงโมเดลตัวท็อปของฝั่งตะวันตกแบบเฉือนกันไม่มาก และยังติดอันดับต้นๆ ทั้งเรื่องการแก้โครงสร้างโค้ดและการไม่มั่ว
ที่เป็นข่าวที่สุดคือการวัดตัวหนึ่งที่ GLM 5.2 ทำคะแนนได้เต็ม 100% เป็นครั้งแรกในประวัติศาสตร์ของ benchmark นั้น ทั้งที่รุ่นก่อนหน้าทำได้แค่ราว 26% กระโดดขนาดนี้ในรุ่นเดียวถือว่าน่าตกใจ
แถมราคาต่อการใช้งานก็ถูก อยู่ที่ราว 1 ดอลลาร์ต่อหนึ่งล้าน token ฝั่ง input ถ้าดูแค่ตารางคะแนนกับป้ายราคา นี่คือโมเดลที่น่าซื้อมาก คำถามเดียวที่เหลือคือพอเอามาทำงานจริงแล้วมันจะรักษาความเก่งนั้นไว้ได้ไหม
พอให้เขียนเกมจริง เรื่องก็เปลี่ยน
ตรงนี้คือหัวใจของเรื่อง เพราะการทดสอบไม่ได้หยุดอยู่แค่ตารางคะแนน แต่ลงไปสั่งให้โมเดลสร้างงานจริงหลายชิ้น แล้วเปิดดูว่ามันเล่นได้จริงหรือเปล่า
เกมบ้านผีที่สั่งสร้างออกมาดูดีในแวบแรก มีกุญแจ 3 ดอก มีเสียงบรรยากาศครบ แต่พอเล่นจริงกลับไม่มีตัวผีออกมาไล่ตามที่ควรจะเป็น และที่หนักกว่านั้นคือเก็บกุญแจครบทั้ง 3 ดอกแล้วก็ยังเปิดประตูออกจากบ้านไม่ได้ เกมที่จบไม่ได้ก็คือเกมที่เล่นไม่ได้
เกมลอบเร้นในสามมิติที่สั่งต่อเจอปัญหาคนละแบบแต่ผลเหมือนกัน คือฉากมืดเกินไปจนมองไม่เห็นอะไรเลย ส่วนเกมแนว Minecraft ที่ขอให้ทำ เปิดหน้าจอขึ้นมาได้สวยดี แต่กดเดินไม่ไป ควบคุมตัวละครไม่ได้สักนิด
แม้แต่งานที่ไม่ใช่เกมก็ยังสะดุดที่รายละเอียด อย่างวิดีโอโปรโมตที่สั่งให้สร้าง มันลอกหน้าตา UI ของแอปออกมาได้เหมือน แต่พอถึงตัวข้อความและการไล่สี ผลที่ได้กลับจืดและขาดความคิดสร้างสรรค์ งานเกือบทุกชิ้นมีรูปแบบเดียวกันคือ "โครงมาแต่รายละเอียดไม่มา"
เก่งตอนสอบ ไม่เท่ากับใช้ทำงานได้

ทำไมโมเดลที่ทำคะแนนสอบสวยขนาดนั้นถึงสร้างเกมที่เล่นไม่ได้ คำตอบอยู่ที่ความต่างระหว่างสองอย่างนี้
การวัดคะแนนคือการตอบโจทย์ก้อนเล็กที่มีคำตอบชัดเจน ส่วนการเขียนเกมหรือแอปจริงต้องประกอบชิ้นส่วนหลายสิบอย่างให้ทำงานสอดคล้องกันตั้งแต่ต้นจนจบ กุญแจครบแล้วต้องเปิดประตูได้ กดปุ่มเดินแล้วตัวละครต้องขยับ ปรับไฟแล้วต้องมองเห็น สิ่งที่ขาดไปไม่ใช่ความฉลาด แต่เป็นความใส่ใจในรายละเอียดและความน่าเชื่อถือของผลลัพธ์
นี่คือบทเรียนที่ใช้ได้กับการเลือก AI มาเขียนโค้ดทุกตัว ไม่ใช่แค่ GLM 5.2 ตารางคะแนนบอกได้แค่ว่าโมเดลตอบโจทย์สั้นๆ เก่งแค่ไหน แต่บอกไม่ได้ว่ามันจะส่งงานที่พร้อมใช้จริงให้เราได้หรือเปล่า ยุคที่ทุกโมเดลเร็วขึ้นและฉลาดขึ้นพร้อมกัน สิ่งที่หาได้ยากขึ้นกลับเป็นความใส่ใจรายละเอียดและความสม่ำเสมอของผลงาน
ยังมีกำแพง rate limit รออยู่
นอกจากเรื่องคุณภาพงานแล้ว ยังมีกำแพงอีกชั้นที่คนคิดจะใช้จริงควรรู้ไว้ คือเรื่องโควตาการใช้งาน
จากการทดสอบ ใช้งานติดต่อกันแค่ราว 1 ชั่วโมงก็กินโควตาไปถึง 70% ของรอบ 5 ชั่วโมง และ 14% ของโควตารายสัปดาห์ คิดเป็นการใช้ token ไปราว 37 ล้าน token ยิ่งถ้าสั่งให้รันหลายงานขนานกัน โอกาสโดนจำกัดการใช้งานก็ยิ่งสูง
นี่ไม่ได้แปลว่าโมเดลแย่ แต่แปลว่าการเอามาใช้จริงต้องคิดเผื่อเรื่องนี้ตั้งแต่แรก ไม่ใช่ดูแค่ป้ายราคาต่อ token แล้วคิดว่าจะใช้ได้ไม่จำกัด
แล้วควรหยิบไปใช้ตอนไหน
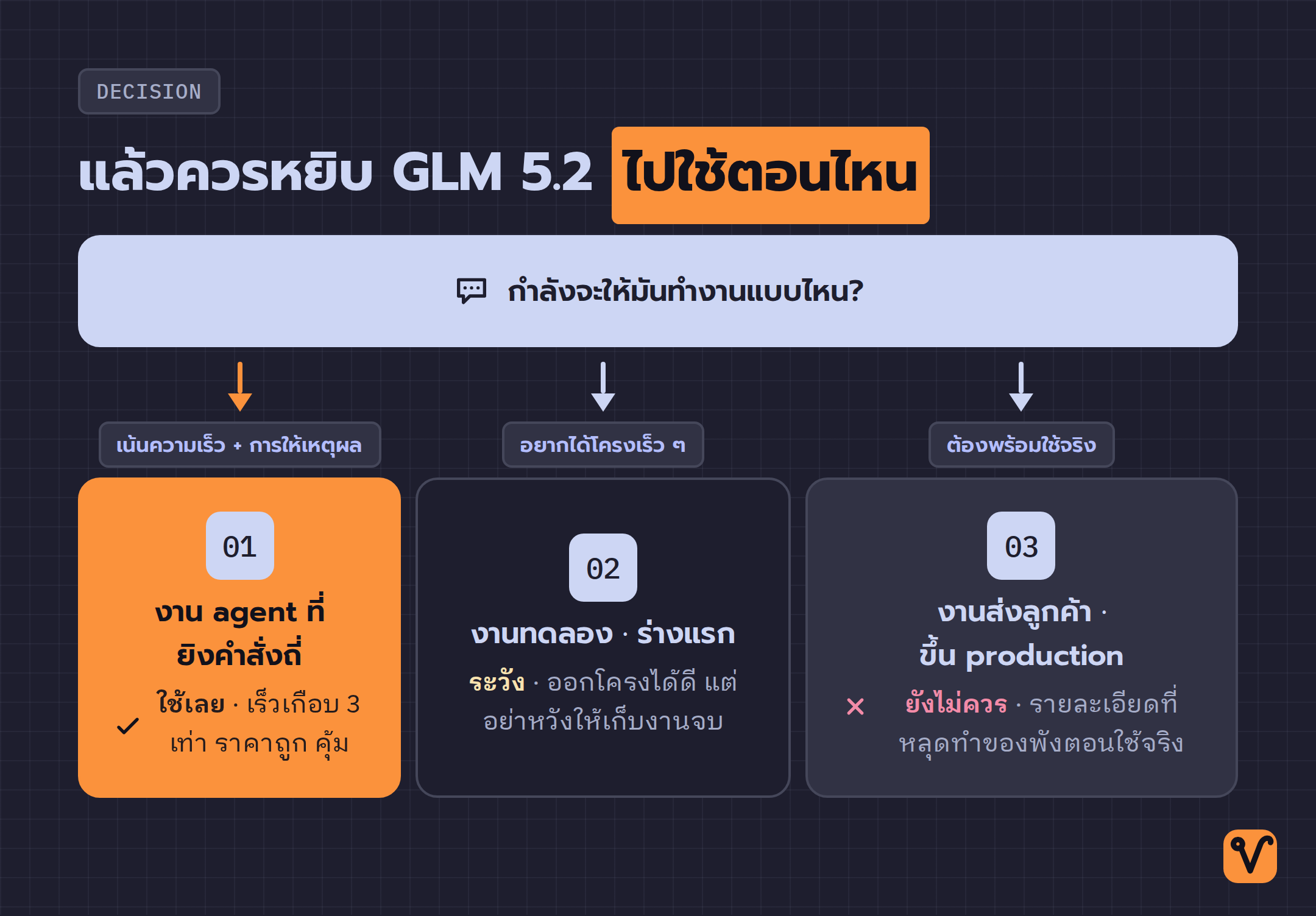
สรุปแบบตรงไปตรงมา GLM 5.2 ยังไม่ใช่โมเดลที่จะไว้ใจให้ส่งงานพร้อมใช้แบบ production แต่ก็ไม่ได้แปลว่ามันไม่มีที่ทาง ถ้าต้องเลือกว่าเมื่อไรควรหยิบมันมาใช้ ลองคิดเป็นสามโจทย์นี้
- งานที่ต้องการความเร็วและการให้เหตุผลเป็นหลัก เช่นงานในระบบ agent ที่ยิงคำสั่งถี่ๆ ตรงนี้ความเร็วที่เกือบ 3 เท่า บวกกับราคาที่ถูกของมันถือว่าคุ้มค่า
- งานทดลองหรือร่างแรก ที่ต้องการโครงเร็วๆ แล้วค่อยมาเก็บรายละเอียดเอง โมเดลออกโครงให้ได้ดี แค่อย่าคาดหวังว่ามันจะเก็บงานให้จบ
- งานส่งลูกค้าหรือขึ้นใช้งานจริง ตรงนี้คือจุดที่ยังไม่ควรไว้ใจมันคนเดียว เพราะรายละเอียดที่หลุดไปคือสิ่งที่ทำให้ของพังตอนใช้จริง
วิธีเริ่มที่ปลอดภัยที่สุดคืออย่าเพิ่งผูกงานหลักไว้กับมัน วันแรกให้ลองด้วยโจทย์เล็กที่ตรวจผลได้ในรอบเดียว เช่นสั่งให้สร้างเกมง่ายๆ สักตัว แล้วลองเล่นจนจบว่ามันทำงานครบจริงไหม ถ้าผ่านโจทย์เล็กแบบนั้นแล้วค่อยขยับไปงานที่ใหญ่ขึ้นทีละขั้น
บทเรียนจากการลองใช้จริงรอบนี้ (ที่ช่อง BridgeMind สรุปไว้หลังซื้อแผนมาทดสอบเอง) จึงไม่ได้อยู่ที่ว่า GLM 5.2 เก่งหรือไม่เก่ง แต่อยู่ที่ว่าตัวเลขบนตารางคะแนนกับของที่ส่งถึงมือเราเป็นคนละเรื่องกัน ยิ่ง AI ทุกตัวเร็วขึ้นพร้อมกันเท่าไร คนที่ตรวจรายละเอียดเป็นก็ยิ่งได้เปรียบมากขึ้นเท่านั้น
ที่มา: คลิป Vibe Coding With GLM 5.2 จากช่อง BridgeMind
ชอบเรื่องแนวนี้ มีอีบุ๊คฟรีให้อ่านต่อ
Local LLM ฉบับเข้าใจง่าย รัน AI ไว้ในเครื่องตัวเอง ติดตั้ง อัปเดต จัดการ ลบ ครบวงจรด้วย Ollama
กดสมัครแล้วเราจะส่งเทคนิค AI และของแจกใหม่ๆ ให้ทางอีเมล เลิกรับได้ตลอด
Claude Cowork · The Business Playbook

ฉบับภาษาไทย 15 บท เรียนรู้ผ่านโปรเจกต์จำลองต่อเนื่องทั้งเล่ม ตั้งแต่ตั้งค่า Workspace จัดการไฟล์ เชื่อมแอป ตั้งระบบอัตโนมัติ จนถึงสร้าง Plugin


