HALO เครื่องมือฟรีที่เปิดดูข้างใน AI agent ว่าพังตรงไหน รันบนเครื่องตัวเอง
HALO คือเครื่องมือโอเพนซอร์สที่อ่าน trace ของ AI agent แล้วชี้ว่ามันทำงานพลาดตรงไหน รันบนเครื่องตัวเองได้ ไม่ต้องส่งข้อมูลขึ้นคลาวด์ จุดเด่นคือมันหาจุดพังที่เกิดซ้ำข้ามการรันหลายครั้ง แทนที่จะแก้ทีละเคส

HALO คือเครื่องมือโอเพนซอร์สที่ทำหน้าที่เป็น debugger ให้ AI agent โดยรันบนเครื่องตัวเอง (local) ชื่อเต็มของมันคือ Hierarchical Agent Loop Optimizer งานหลักคืออ่าน "ร่องรอย" การทำงานของ agent แล้วบอกว่ามันทำงานพลาดตรงไหน
ใครที่เคยสร้าง AI agent คงเจอปัญหาเดียวกัน คือพอ agent ทำงานหลุดออกนอกทาง การไล่หาสาเหตุยากมาก เพราะมองไม่เห็นว่ามันคิดอะไรอยู่ มันเรียกเครื่องมือตัวไหน ตัดสินใจเลือกทางนั้นเพราะอะไร และจริงๆ แล้วมันพังตรงขั้นไหนกันแน่ HALO เกิดมาเพื่อตอบโจทย์นี้โดยตรง คือทำให้ "เห็นข้างใน" ของ agent เพื่อหาจุดพังได้เร็วขึ้น โดยไม่ต้องส่ง trace ขึ้นคลาวด์
trace คือสมุดบันทึกทุกก้าวของ agent
ก่อนจะเข้าใจว่า HALO ช่วยอะไร ต้องเข้าใจคำว่า trace ก่อน
AI agent ไม่ได้ตอบคำถามรวดเดียวจบเหมือน chatbot ทั่วไป มันทำงานเป็นลำดับขั้น คิด เรียกเครื่องมือ อ่านผลลัพธ์ ตัดสินใจขั้นต่อไป วนแบบนี้จนกว่างานจะเสร็จ trace ก็คือบันทึกทุกขั้นตอนเหล่านั้น ว่าในแต่ละรอบ agent คิดอะไร เรียกเครื่องมืออะไร ใส่ค่าอะไรเข้าไป แล้วได้อะไรกลับมา
พูดง่ายๆ trace คือสมุดบันทึกที่ agent เขียนทิ้งไว้ว่าตัวเองทำอะไรไปบ้างทีละก้าว เวลามันทำงานสำเร็จเราไม่ค่อยสนใจสมุดเล่มนี้ แต่พอมันพัง สมุดเล่มนี้คือหลักฐานชิ้นเดียวที่บอกได้ว่าเกิดอะไรขึ้น HALO รับ trace เข้ามาในรูปแบบไฟล์ JSONL และเก็บ trace ตามมาตรฐาน OpenTelemetry ซึ่งเป็นรูปแบบกลางที่เครื่องมือสาย observability ใช้กันอยู่แล้ว
ทำไมการดีบัก agent ถึงยากกว่าที่คิด
ถ้า trace คือหลักฐาน ทำไมยังไล่หาจุดพังยากอยู่ดี คำตอบมีสองข้อ
ข้อแรก trace ของ agent ยาวมาก งานเดียวอาจมีหลายสิบก้าว แต่ละก้าวมีทั้งความคิด คำสั่ง และผลลัพธ์ปนกัน อ่านด้วยตาเปล่าทั้งไฟล์แทบเป็นไปไม่ได้
ข้อสอง และข้อนี้สำคัญกว่า คือปัญหาจริงมักไม่ได้อยู่ที่ trace ชุดเดียว แต่อยู่ที่ harness ซึ่งก็คือโครงสร้างคำสั่งและตรรกะที่ครอบ agent ไว้อีกที จุดพังตัวจริงคือรูปแบบความผิดพลาดที่ "เกิดซ้ำ" ข้ามการรันหลายครั้ง เช่น agent ชอบเรียกเครื่องมือที่ไม่มีอยู่จริง หรือวนเป็นลูปปฏิเสธงานซ้ำๆ การจะเห็นรูปแบบแบบนี้ ต้องมองภาพรวมจาก trace หลายชุดพร้อมกัน ไม่ใช่จ้องชุดเดียว
ทีมผู้สร้าง HALO ยังตั้งข้อสังเกตที่น่าสนใจไว้ด้วย คือการเอา general-purpose harness อย่าง Claude Code มาวิเคราะห์ trace มักไม่ได้ผล ไม่ใช่เพราะโมเดลไม่ฉลาดพอ แต่เพราะ trace ยาวเกินไป และการจับพฤติกรรมเชิงระบบของ agent ต้องใช้ชุดเครื่องมือเฉพาะทาง เครื่องมือทั่วไปมักจะไปแก้ error ในเคสเดียวที่เห็นตรงหน้า แทนที่จะเห็นปัญหาที่ระดับ harness
HALO หาจุดพังที่เกิดซ้ำ แล้วเขียน report ให้ไปแก้ต่อ

หัวใจของ HALO คือเทคนิคที่เรียกว่า RLM หรือ Recursive Language Model พูดให้เห็นภาพคือมันใช้โมเดลภาษาทำงานแบบเรียกตัวเองซ้อนกันเป็นชั้นๆ เพื่อย่อย trace ที่ยาวมากให้ไหว แล้วไล่หารูปแบบความผิดพลาดที่โผล่ซ้ำข้ามการรันหลายครั้ง HALO engine เป็น RLM รูปแบบเฉพาะที่ปรับมาเพื่องานนี้โดยตรง
สิ่งที่ได้ออกมาไม่ใช่แค่รายการ error แต่เป็น report ที่ชี้ว่าปัญหาเชิงระบบอยู่ตรงไหน ในการทดสอบกับ benchmark ชื่อ AppWorld ซึ่งวัดความสามารถของ agent ในการใช้บริการหลายแอปพร้อมกัน อย่าง Spotify, Venmo, ระบบไฟล์, รายชื่อในโทรศัพท์ HALO เจอจุดพังชัดๆ หลายแบบ ตั้งแต่การเรียกเครื่องมือที่ agent มโนขึ้นมาเอง การใส่ค่าซ้ำซ้อนเข้าเครื่องมือ การวนลูปปฏิเสธงาน ไปจนถึงปัญหาความถูกต้องเชิงความหมาย และแต่ละจุดโยงไปถึง prompt ที่ควรแก้ได้ชัดเจน
จากตรงนี้ HALO ออกแบบมาให้ทำงานเป็นวงจร report ที่ได้สามารถส่งต่อให้ coding agent อย่าง Cursor หรือ Claude Code นำไป generate และแก้ harness ให้อัตโนมัติ จากนั้น deploy harness ตัวใหม่ เก็บ trace รอบใหม่ แล้ววนซ้ำ กลายเป็นลูปที่ harness ค่อยๆ ปรับปรุงตัวเองไปเรื่อยๆ
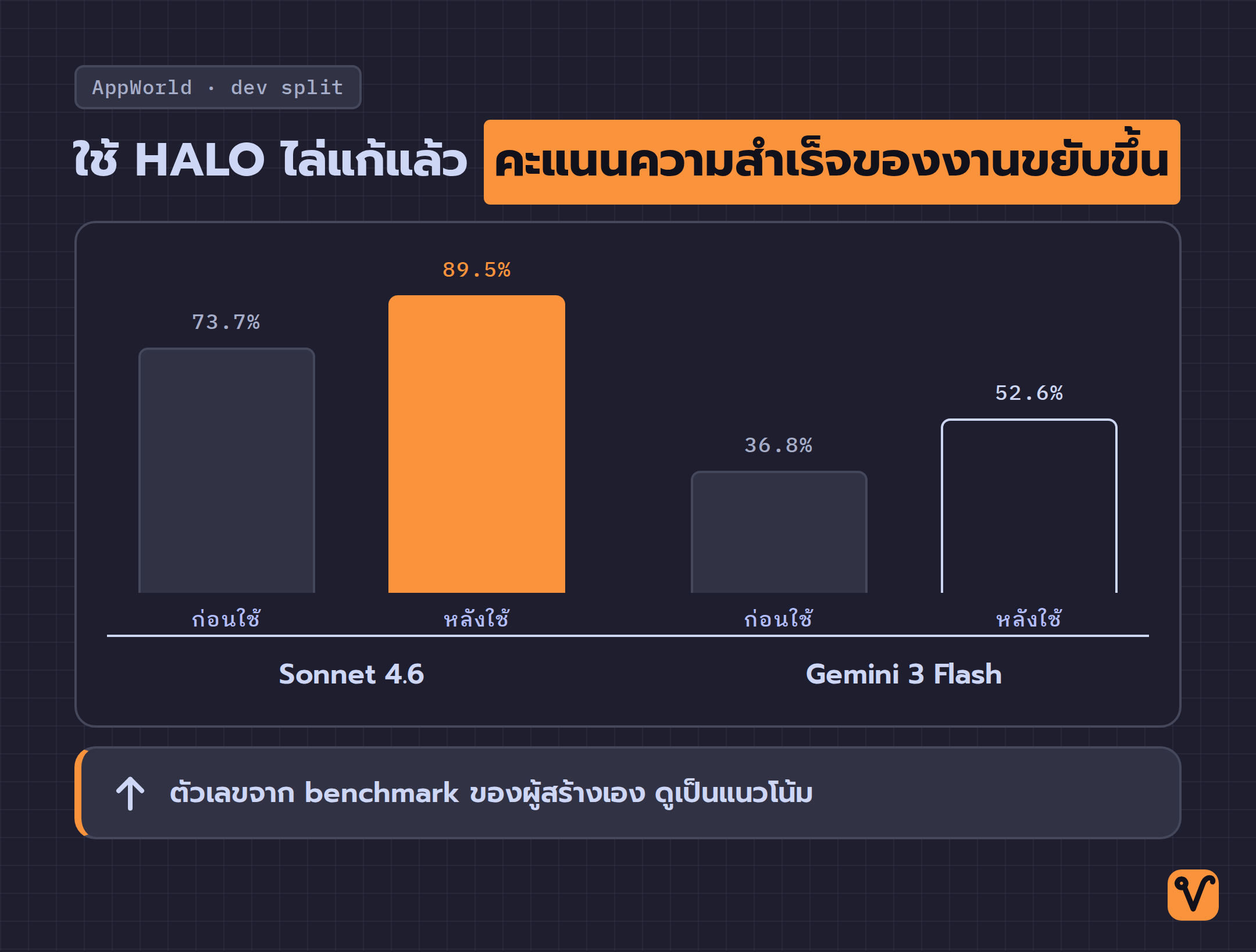
ตัวเลขจาก AppWorld ช่วยให้เห็นภาพชัดขึ้น กับโมเดล Sonnet 4.6 คะแนนความสำเร็จของงานบน dev split ขยับจาก 73.7% เป็น 89.5% และฝั่ง Gemini 3 Flash ขยับจาก 36.8% เป็น 52.6% โดยทีมแยกใช้ dev split สำหรับไล่ปรับ และใช้ test_normal split ตรวจว่าไม่ได้แก้จนเข้าทางข้อสอบ ตัวเลขเหล่านี้มาจาก benchmark ของผู้สร้างเอง อ่านไว้เป็นทิศทาง ไม่ใช่การการันตีว่า agent ของเราจะดีขึ้นเท่านี้
เริ่มใช้จริงด้วยคำสั่งเดียว
ถ้าจะเริ่มใช้จริง HALO ใช้งานได้สองทาง เลือกตามว่าเราอยากได้แบบไหน
HALO Desktop App สำหรับคนที่อยากได้หน้าจอที่กดดูได้ง่ายๆ รันบนเครื่องตัวเอง ติดตั้งด้วยคำสั่งเดียว และฝั่ง macOS เป็น DMG ที่เซ็นและ notarized มาเรียบร้อย
curl -fsSL https://inference.net/halo/install.sh | sh
halo-engine สำหรับสายที่อยากเรียกผ่านบรรทัดคำสั่งหรือฝังในสคริปต์ ติดตั้งเป็น Python package ผ่าน pip
pip install halo-engine
พอติดตั้งเสร็จ ก้าวแรกที่ทำได้เลยคือชี้ HALO ไปที่ไฟล์ trace ของเรา แล้วบอกมันว่าให้ช่วยดูอะไร
halo path_to_your_traces.jsonl -p "Diagnose errors you find and suggest fixes"
แค่นี้ engine ก็จะไล่อ่าน trace แล้วคืน report ที่สรุปจุดพังกลับมาให้ ลำดับการใช้งานจริงคือ เก็บ trace จาก agent ออกมาเป็น JSONL ก่อน แล้วป้อนเข้า HALO ด้วยคำสั่งด้านบน จากนั้นเอา report ที่ได้ไปแก้ harness ต่อ
ฟรีจริง แต่มีต้นทุนซ่อนอยู่
HALO เป็นโอเพนซอร์สบน GitHub และเปิดรับ contribution จริง โค้ดอยู่ใน repo context-labs/halo ตัวโปรแกรมเองดาวน์โหลดมาใช้ได้ไม่มีค่าใช้จ่าย แต่ก่อนจะกดใช้ มีเงื่อนไขที่ควรรู้ไว้ก่อน
ข้อดีคือ HALO ไม่ได้ล็อกเราไว้กับ OpenAI ถ้าตั้งค่า OPENAI_BASE_URL จะใช้ provider อื่นที่เข้ากันได้กับ OpenAI API อย่าง OpenRouter แทนได้ และถ้าใครไม่อยากตั้งระบบเอง ผู้สร้างมี hosted version แบบ plug-and-play ให้ที่ inference.net เป็นทางเลือก ไม่ใช่ของบังคับ
เรื่องความเป็นส่วนตัวก็คิดมาให้แล้ว telemetry ของ HALO ปิดอยู่ตั้งแต่แรก HALO จะเขียน trace เป็นไฟล์ JSONL บนเครื่องตัวเอง และจะส่งขึ้นคลาวด์ก็ต่อเมื่อเราเปิด --telemetry เองเท่านั้น ใครทำงานกับข้อมูลอ่อนไหวจึงสบายใจได้ระดับหนึ่ง
สำหรับสายที่อยากลงลึก HALO มีพารามิเตอร์ให้ปรับการวิเคราะห์ ค่า default คือ --max-depth 2 สำหรับชั้นการเรียกซ้อนของ subagent, --max-turns 20 ต่อ agent หนึ่งตัว และ --max-parallel 10 สำหรับจำนวน subagent ที่รันพร้อมกัน ส่วนใครอยากพัฒนา HALO ต่อเอง repo ใช้ uv จัดการ dependency
ยิ่ง agent ทำงานจริงเยอะ ยิ่งเห็นจุดพังชัด
จุดที่น่าคิดของ HALO คือมันทำงานได้ดีที่สุดกับ agent ที่ deploy ใช้งานจริงและมีทราฟฟิกสูง เพราะยิ่งมีการรันเยอะ ความหลากหลายของจุดพังก็ยิ่งโผล่ออกมาให้เห็น
นั่นแปลว่าวิธีคิดเรื่องดีบัก agent กำลังเปลี่ยนไป จากเดิมที่เรามองความพังเป็นบั๊กรายเคสที่ต้องไล่แก้ทีละจุด กลายเป็นการมองหารูปแบบความผิดพลาดที่ซ่อนอยู่ในพฤติกรรมภาพรวมของ agent ทั้งระบบ ยิ่ง agent ฉลาดและทำงานซับซ้อนขึ้นเท่าไร การมองเห็นว่ามันคิดอะไรอยู่ ก็ยิ่งสำคัญกว่าการมองแค่ว่ามันตอบถูกหรือผิด
ที่มา: context-labs/HALO: Hierarchal Agent Loop Optimizer จาก context-labs/halo บน GitHub



