LLM Wiki ทำให้ coding agent มีคลังความรู้ถาวรของตัวเอง แทนที่จะลืมทุกอย่างเมื่อปิดแชต
LLM Wiki คือชุดคำสั่งโอเพนซอร์สที่ให้ coding agent เก็บงานวิจัยทุกครั้งไว้เป็นคลังความรู้ Markdown ถาวรในเครื่อง พอ agent ไม่ต้องไปค้นเรื่องเดิมซ้ำทุกแชต งานก็แม่นและต่อเนื่องขึ้น

ทุกครั้งที่ปิดแชต coding agent ความรู้ที่มันเพิ่งค้นมาให้ก็หายไปด้วย แชตหน้าเริ่มจากศูนย์อีกรอบ ค้นเรื่องเดิม อ่านเอกสารชุดเดิม สรุปสิ่งเดิมที่เคยสรุปไปแล้วเมื่อวาน LLM Wiki คือชุดคำสั่งโอเพนซอร์ส (สัญญาอนุญาต MIT · เว็บ llm-wiki.net) ที่แก้ตรงจุดนี้ มันเปลี่ยนงานวิจัยทุกครั้งของ agent ให้กลายเป็นคลังความรู้ถาวรในเครื่อง เก็บเป็นไฟล์ Markdown ที่เชื่อมโยงถึงกัน ค้นซ้ำได้ และเป็นของผู้ใช้เองทั้งหมด
แกนของมันเรียบง่ายแต่ใช้ได้จริง คือทำให้ coding agent ที่ใช้อยู่ทุกวันมี "สมุดบันทึก" ถาวรของตัวเอง ครั้งหน้าที่เจอเรื่องเดิม agent ก็หยิบจากคลังมาใช้ ไม่ต้องค้นใหม่ตั้งแต่ต้น แนวคิดนี้ต่อยอดมาจากไอเดีย "LLM wiki" ที่ Andrej Karpathy นักวิจัย AI คนดังผู้ร่วมก่อตั้ง OpenAI เคยพูดถึงไว้ ก่อนจะออกมาเป็นเครื่องมือที่ติดตั้งใช้ได้จริงในไม่กี่บรรทัด
ปัญหาไม่ใช่ agent ไม่เก่ง แต่มันจำอะไรไม่ได้
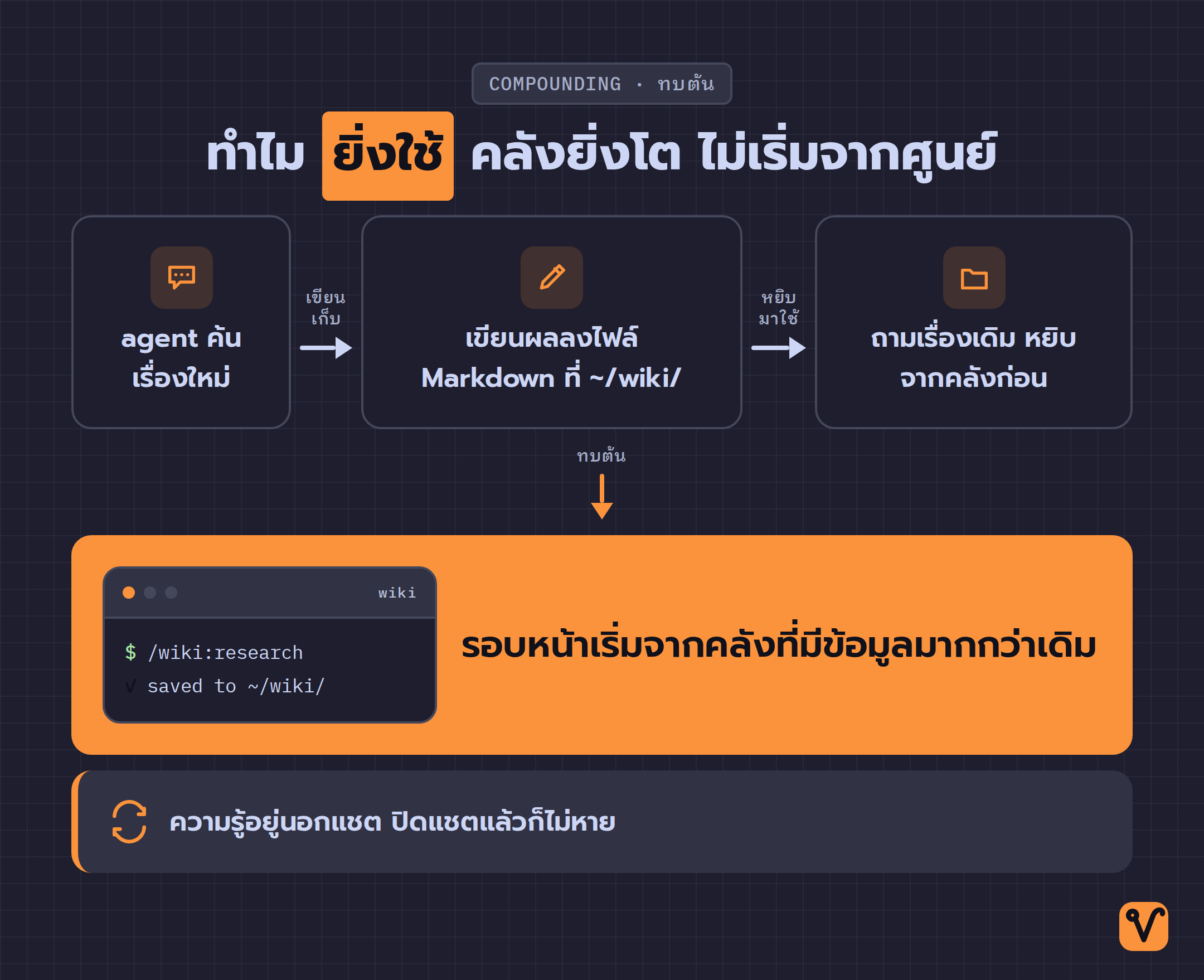
coding agent รุ่นใหม่ค้นเว็บเก่ง อ่านเอกสารเก่ง สรุปได้ดี ปัญหาไม่ได้อยู่ที่ความเก่ง แต่อยู่ที่ทุกอย่างนั้นอยู่แค่ในแชตเดียว พอแชตจบ ความรู้ก็จบตามไปด้วย
ผลที่ตามมาคืองานซ้ำซ้อนที่มองไม่เห็น สัปดาห์ที่แล้วเคยให้ agent ค้นวิธีตั้งค่า library ตัวหนึ่งจนเข้าใจดีแล้ว แต่สัปดาห์นี้พอกลับมาทำต่อ agent กลับจำไม่ได้ว่าเคยค้น จึงต้องเริ่มค้นใหม่ อ่านใหม่ กินทั้งเวลาและโทเคน ที่แย่กว่านั้นคือบางทีคำตอบรอบใหม่ไม่ตรงกับรอบเก่า เพราะไม่มีบันทึกอะไรให้ยึด
LLM Wiki แก้ปัญหานี้ด้วยการแยก "ความรู้" ออกจาก "แชต" เมื่อ agent ค้นเรื่องอะไรเสร็จ มันเขียนผลลงไฟล์ Markdown เก็บไว้ที่ ~/wiki/ บนเครื่อง ครั้งต่อไปที่ถามเรื่องเดิม agent อ่านจากคลังก่อน ไม่ต้องออกไปค้นใหม่ทั้งหมด คลังนี้อยู่นอกแชต จึงไม่หายไปไหนเมื่อปิดแชตหรือปิดเครื่อง
เก็บเป็น Markdown ที่เราเป็นเจ้าของ ไม่ต้องมี server
จุดที่ทำให้ LLM Wiki ต่างจากบริการจำบริบทแบบอื่นคือมันไม่มี server ไม่มีฐานข้อมูล และไม่ต้องลงโปรแกรมอะไรเพิ่ม มันใช้แค่ความสามารถพื้นฐานที่ตัว coding agent มีอยู่แล้ว คืออ่านเขียนไฟล์ ค้นเว็บ และดึงหน้าเว็บมาอ่าน
คลังความรู้ทั้งหมดเป็นไฟล์ Markdown ธรรมดาบนดิสก์ของเรา เปิดอ่านด้วยโปรแกรมแก้ข้อความตัวไหนก็ได้ ย้ายไป iCloud Drive หรือกำหนด path เองก็ได้ และเพราะเป็นไฟล์ในเครื่อง เราเป็นเจ้าของข้อมูลเต็มตัว ไม่ได้ฝากไว้กับบริการของใคร
โครงสร้างข้างในแบ่งชั้นชัดเจน ข้อมูลดิบที่ดึงเข้ามาครั้งแรกจะล็อกไว้เป็นต้นฉบับ ไม่แก้ย้อนหลัง ส่วนบทความที่เรียบเรียงขึ้นใหม่จะแยกไว้อีกชั้น การแยกแบบนี้ทำให้ย้อนกลับไปดูได้เสมอว่าข้อสรุปแต่ละอันมาจากแหล่งไหน ความรู้ในคลังจึงตรวจสอบที่มาได้ ไม่ใช่กล่องดำ
แต่ละหัวข้อในคลังยังมาพร้อมการตั้งค่าให้เปิดใน Obsidian ได้ทันที ใครชอบจัดโน้ตแบบโยงกันเป็นกราฟก็เปิดคลังเดียวกันนี้ใน Obsidian อ่านต่อได้เลย โดยไฟล์ยังเป็น Markdown มาตรฐานที่เปิดที่อื่นได้เหมือนเดิม
ติดตั้งเป็นปลั๊กอินใน coding agent ที่ใช้อยู่
LLM Wiki ไม่ใช่แอปแยกที่ต้องเปิดต่างหาก แต่ติดตั้งเข้าไปใน coding agent ที่ใช้อยู่แล้ว ทางที่ตรงที่สุดคือติดตั้งเป็นปลั๊กอินใน Claude Code ด้วยคำสั่งเดียว
claude plugin install wiki@llm-wikiถ้าใช้ agent ตัวอื่น ก็มีวิธีติดตั้งเหมือนกัน OpenAI Codex ติดผ่านปลั๊กอินใน marketplace ส่วน OpenCode กับ Pi ใช้ไฟล์คำสั่ง (Pi เหมาะกับการรันโมเดลในเครื่อง) ถ้าเป็น agent ที่อ่านไฟล์ AGENTS.md ได้ ก็มีเวอร์ชันพกพาให้หย่อนไฟล์เดียวลงไปแล้วใช้ได้ทันที
เบื้องหลัง ตรรกะการทำงานทั้งหมดเขียนไว้ที่เดียว แล้วค่อยแปลงออกมาเป็นแพ็กเกจของแต่ละ agent ไม่ได้แยกไปเขียนใหม่ทีละตัว ทุก agent จึงได้พฤติกรรมชุดเดียวกัน ต่างกันแค่ขนาดของคำสั่งที่ฝังเข้าไป ตั้งแต่ราว 22K โทเคนบน Claude Code ลงไปจนถึงราว 1K โทเคนบน Pi สำหรับเครื่องที่ทรัพยากรจำกัด
เริ่มใช้จริงใน 3 คำสั่งแรก

หลังติดตั้งแล้ว เริ่มได้ด้วยสามขั้นตอนนี้ ทดลองตามได้ในไม่กี่นาที
- สร้างคลังของหัวข้อที่สนใจ พิมพ์
/wiki init <ชื่อหัวข้อ>ระบบจะสร้าง hub ที่~/wiki/และโฟลเดอร์ของหัวข้อนั้นที่~/wiki/topics/<ชื่อหัวข้อ>/ - สั่งให้วิจัยเรื่องที่อยากรู้ พิมพ์
/wiki:research "หัวข้อที่อยากรู้" --new-topicระบบจะส่ง agent หลายตัวออกไปค้นข้อมูลพร้อมกัน แล้วเรียบเรียงผลกลับมาเป็นบทความในคลัง - ถามคลังที่เพิ่งสร้าง พิมพ์
/wiki:query "คำถามของเรา"คราวนี้คำตอบจะมาจากบทความที่เรียบเรียงเก็บไว้แล้ว พร้อมอ้างอิงว่าดึงมาจากแหล่งไหน
ตัวอย่างเช่น ถ้าอยากให้ agent แม่นเรื่องการตั้งค่า deploy ของโปรเจกต์ตัวเอง ก็พิมพ์ /wiki init deploy-notes แล้ว /wiki:research "วิธี deploy โปรเจกต์ Next.js บน VPS" --new-topic หนึ่งครั้ง จากนั้นทุกแชตที่คุยเรื่อง deploy ก็ใช้ /wiki:query ถามคลังเดิมได้เลย ไม่ต้องเล่าบริบทใหม่ทุกครั้ง
วิจัยพร้อมกันหลายตัว แล้วให้คะแนนความน่าเชื่อถือ
ขั้นวิจัยคือหัวใจที่ทำให้คลังมีคุณภาพ เวลาสั่ง /wiki:research ระบบไม่ได้ค้นแบบรอบเดียวจบ แต่ส่ง agent หลายตัวออกไปค้นพร้อมกัน แต่ละตัวมองหัวข้อจากคนละมุม ทั้งมุมวิชาการ มุมเทคนิค มุมการใช้งานจริง มุมข่าวล่าสุด และมุมที่ตั้งใจค้าน เพื่อกันไม่ให้เชื่อข้อมูลด้านเดียว
โหมดมาตรฐานใช้ agent 5 ตัว ถ้าอยากค้นลึกขึ้นก็เพิ่มเป็น 8 หรือ 10 ตัวได้ ในแต่ละรอบ agent แต่ละตัวจะค้นเว็บ 2-3 ครั้ง ดึงเนื้อหาเต็มมาอ่าน แล้วให้คะแนนคุณภาพแหล่งข้อมูลตั้งแต่ 1 ถึง 5 ก่อนเอาเข้าคลัง ผลที่ได้จึงไม่ใช่การเหมารวมทุกหน้าที่เจอ แต่เป็นข้อมูลที่ผ่านการคัดมาแล้วระดับหนึ่ง
ความน่าเชื่อถือยังตรวจซ้ำได้ด้วยคำสั่ง /wiki:audit ที่ไล่ตรวจเส้นทางอ้างอิงจากข้อสรุปย้อนกลับไปถึงแหล่งต้นทาง ถ้าข้อไหนอ้างลอยไม่มีที่มา ก็เห็นได้ตรงนั้น คลังจึงโตขึ้นเรื่อยๆ โดยที่ยังตามรอยที่มาได้
จำบริบทข้ามแชตได้ แม้แชตถูกบีบหรือปิดไป
นอกจากคลังความรู้ถาวรแล้ว ยังมีระบบความจำของแต่ละเซสชันทำงานควบคู่ไปด้วย และเปิดไว้เป็นค่าเริ่มต้น ระบบจะเก็บเป็นบันทึกย่อที่ตัดข้อมูลอ่อนไหวออก ไม่ได้เก็บบทสนทนาเต็ม พอแชตถูกบีบให้สั้นลงหรือปิด terminal ไป เปิดกลับมาก็ดึงบริบทเดิมมาทำต่อได้ ไม่ต้องเล่าใหม่ตั้งแต่ต้น
มีอีกชั้นหนึ่งที่คอยเก็บสิ่งที่เราแก้หรือบอกความชอบไว้ แต่ไม่ได้ยัดเข้าคลังทันที มันเก็บเป็น "ตัวเลือก" ให้เราอนุมัติเองว่าจะให้เข้าไปเป็นความรู้ถาวรไหม คำตอบทั่วไปอย่าง "โอเค" หรือ "ขอบคุณ" ระบบจะข้ามให้อัตโนมัติ คลังจึงไม่รกไปด้วยข้อมูลที่ไม่ใช่ความรู้จริง
ของใครเหมาะ ของใครยังไม่ใช่
LLM Wiki ไม่ใช่แอปสำเร็จรูปสำหรับคนทั่วไป มันเป็นเครื่องมือสำหรับคนที่ใช้ coding agent อยู่แล้ว ไม่ว่าจะเป็น Claude Code, Codex, Cursor หรือ Gemini ถ้ายังไม่เคยแตะ agent พวกนี้ ตัวมันเองก็ยังไม่มีประโยชน์ เพราะมันทำงานบนความสามารถที่ agent มีให้ ไม่ได้ทำงานเดี่ยวๆ
แต่สำหรับคนที่ใช้ agent ทำงานจริงทุกวัน หรือมือใหม่สาย vibe coding ที่อยากให้ AI จำบริบทโปรเจกต์ของตัวเองได้ นี่คือจุดที่มันคุ้ม เพราะยิ่งใช้นาน คลังยิ่งโต agent ยิ่งหยิบของเดิมมาใช้ได้มากขึ้น แทนที่จะเริ่มจากศูนย์ทุกแชต เมื่อคลังใหญ่ขึ้นจริงจัง ก็ต่อ search engine ในเครื่องอย่าง qmd เข้ามาช่วยค้นได้
ส่วนผู้สร้างเองอ้างว่าวิธีนี้ช่วยให้ agent ทำงานได้เร็วขึ้นหลายเท่า ตรงนี้เป็นคำกล่าวอ้างของผู้สร้าง ไม่ใช่ตัวเลขจากการวัดที่เป็นกลาง สิ่งที่จับต้องได้จริงกว่าตัวเลขความเร็วคือ agent ไม่ต้องค้นเรื่องเดิมซ้ำ และคำตอบรอบใหม่อิงคลังเดิม จึงนิ่งและสอดคล้องกันมากกว่าการค้นสดทุกครั้ง
ถ้าอยากเข้าใจที่มาของแนวคิดก่อนลงมือ ไฟล์ไอเดียต้นทางของ Karpathy เขียนสั้นๆ ว่าทำไม coding agent ถึงควรมี wiki ของตัวเอง ส่วน LLM Wiki คือนำไอเดียนั้นมาทำเป็นเครื่องมือที่ติดตั้งใช้ได้จริงในคำสั่งเดียว
ความจำที่หายไปทุกครั้งที่ปิดแชต ไม่ใช่ข้อจำกัดของตัว agent แต่อยู่ที่ว่าเราเก็บความรู้ไว้ที่ไหน พอย้ายมันออกมาไว้ในคลังที่เราเป็นเจ้าของ agent ก็ไม่ได้แค่ตอบเก่งขึ้นในแชตเดียว แต่ค่อยๆ สะสมเป็นความรู้ที่อยู่กับเราไปเรื่อยๆ



