Uber เผางบ AI ทั้งปีหมดใน 4 เดือน จนต้องตั้งเพดาน $1,500 ต่อคน · บทเรียนคุมต้นทุน AI ที่ทีมไทยเอาไปใช้ได้เลย
ปลายปี 2025 Uber แจกเครื่องมือ AI เขียนโค้ดให้วิศวกรราว 5,000 คน บอกให้ "ใช้ให้เยอะที่สุด" แล้วทำกระดานจัดอันดับการใช้งาน ผลคือเผางบ AI ทั้งปีหมดภายใน 4 เดือน จนต้องตั้งเพดาน $1,500 ต่อคนต่อเครื่องมือต่อเดือน บทเรียนจริงเรื่องนี้ไม่ใช่ "Uber จ่ายไม่ไหว" แต่เป็นเรื่องพฤติกรรมต้นทุนของ AI agent ที่ธุรกิจไทยทุกขนาดเอาไปวางการ์ดได้ทันที

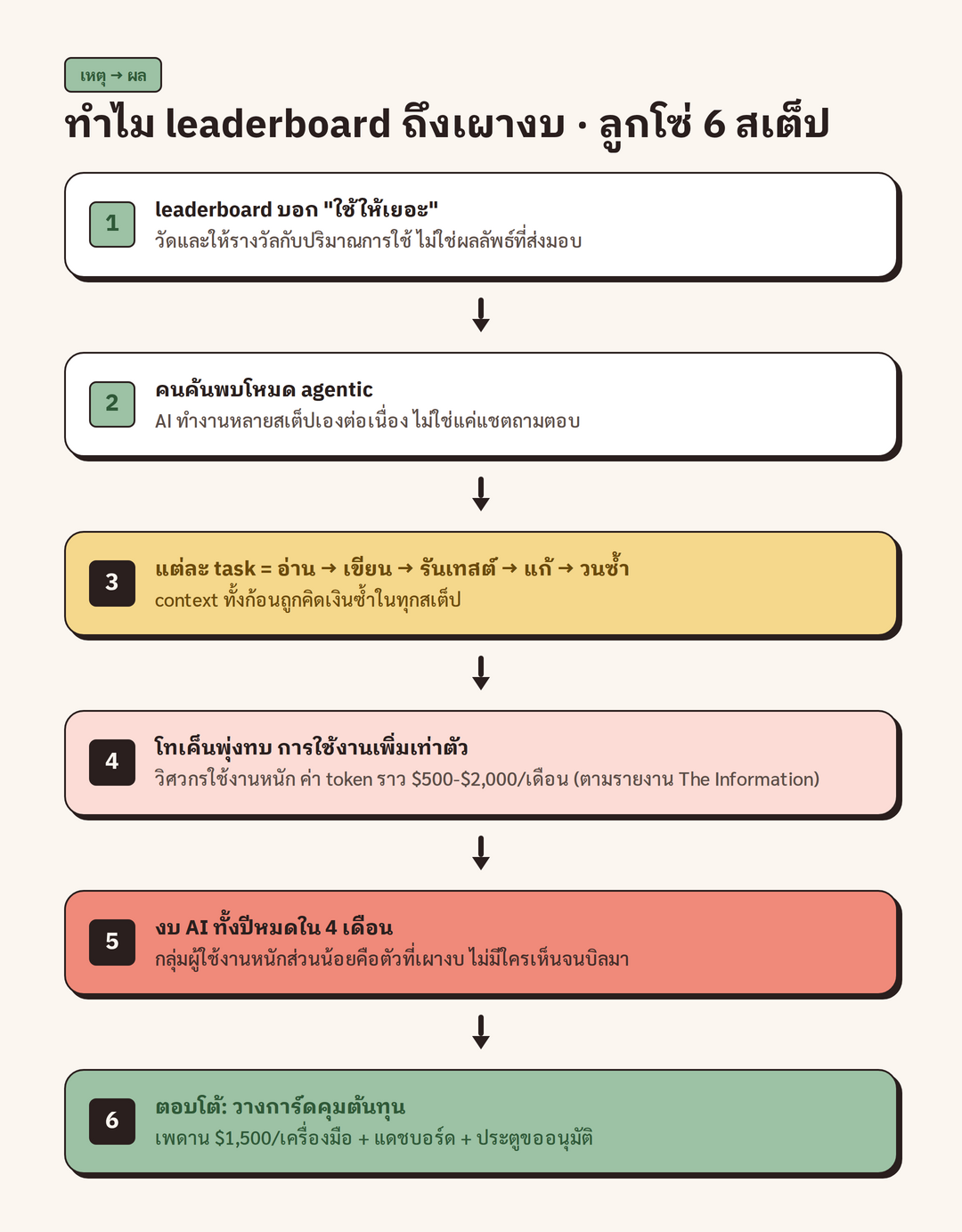
ปลายปี 2025 Uber แจกเครื่องมือ AI เขียนโค้ดอย่าง Claude Code และ Cursor ให้ทีมวิศวกรราว 5,000 คน พร้อมกระตุ้นให้พนักงาน "ใช้ให้เยอะที่สุด" และทำกระดานจัดอันดับ (leaderboard) ว่าทีมไหนใช้งาน AI มากที่สุด ผลที่ตามมาคือพอวิศวกรค้นพบความสามารถแบบ agentic (โหมดที่ AI ทำงานหลายขั้นตอนเองต่อเนื่อง) การใช้งานก็พุ่งขึ้นเท่าตัว และเผางบ AI ทั้งปีหมดภายในเวลาเพียง 4 เดือน ตามรายงานของ TechCrunch ล่าสุดต้นเดือนมิถุนายน 2026 Uber จึงออกกฎตั้งเพดานค่าใช้จ่าย AI ที่ $1,500 ต่อคนต่อเครื่องมือต่อเดือน พร้อมแดชบอร์ดติดตามและระบบขออนุมัติถ้าจะใช้เกิน
เรื่องนี้น่าสนใจสำหรับคนไทยไม่ใช่เพราะเป็นข่าวบริษัทใหญ่ในต่างประเทศ แต่เพราะมันเป็น "ภาพจริง" ของพฤติกรรมค่าใช้จ่าย AI ในองค์กรที่กำลังจะเกิดกับทุกธุรกิจที่เริ่มเอา AI agent มาใช้ และบทเรียนที่ได้คือเรื่อง cost governance (การวางระบบคุมต้นทุน) ที่ทีมไทยทุกขนาดเอาไปใช้ได้ตรงๆ ประเด็นสำคัญที่ต้องตั้งให้ถูกตั้งแต่ต้นคือ นี่ไม่ใช่เรื่อง "Uber จ่ายไม่ไหว" แต่เป็นเรื่อง "คุมไม่อยู่" ซึ่งเป็นคนละปัญหากัน
1. เกิดอะไรขึ้นที่ Uber ในเวลา 4 เดือน
ไทม์ไลน์ของเรื่องนี้ชัดเจนและเป็นเหตุเป็นผลต่อกัน ตามรายงานของ The Information ที่ถูกอ้างต่อในหลายสำนัก Uber เริ่มแจก Claude Code และ Cursor ให้วิศวกรราว 5,000 คนเมื่อเดือนธันวาคม 2025 จากนั้นพอถึงเดือนกุมภาพันธ์ 2026 การใช้งานก็เพิ่มขึ้นราวเท่าตัว เพราะวิศวกรเริ่มค้นพบว่าเครื่องมือเหล่านี้ทำงานแบบ agentic ได้ ไม่ใช่แค่ถาม-ตอบแบบแชต และพอถึงเดือนเมษายน 2026 บิลก็กินงบ AI ทั้งปีหมดเกลี้ยง
Praveen Neppalli Naga ซึ่งเป็น CTO ของ Uber ยอมรับกับ The Information ว่าบริษัท "เผางบ AI ทั้งปีหมดภายในเวลา 4 เดือน" และต้อง "กลับไปตั้งหลักใหม่" ตามรายงานของ Yahoo Finance ที่อ้างอิงต่อจาก The Information ส่วนตัวเลขค่าใช้จ่ายรายคนนั้น ตามรายงานของ The Information ระบุว่าวิศวกรที่ใช้งานหนักมีค่าโทเค็นราว $500 ถึง $2,000 ต่อเดือน ขณะที่ค่าเฉลี่ยทั้งองค์กรอยู่ราว $150 ถึง $250 ต่อคน นั่นหมายความว่ากลุ่มผู้ใช้งานหนักส่วนน้อยคือตัวที่เผางบจริง
จุดที่ต้องระวังไม่ให้เข้าใจผิดคือสัดส่วนของเงินก้อนนี้ ตามรายงานผลประกอบการไตรมาส 1 ปี 2026 ของ Uber บริษัทมีรายได้ $13.2 พันล้าน และใช้งบวิจัยและพัฒนา (R&D) ไตรมาสเดียวถึง $951 ล้าน เพิ่มขึ้น 17% จากปีก่อน ส่วนงบ R&D ทั้งปี 2025 อยู่ที่ $3.4 พันล้าน งบค่าเครื่องมือ AI เขียนโค้ดที่บานปลายจึงเป็นเพียงส่วนเล็กๆ ในงบ R&D ก้อนใหญ่ และ Uber ไม่เคยเปิดเผยตัวเลขรวมของงบนี้ออกมา ดังนั้นบทเรียนของเรื่องนี้จึงไม่ใช่ว่า Uber จ่ายไม่ไหว แต่เป็นว่าแม้แต่บริษัทที่เงินหนาขนาดนี้ก็ยัง "คุมไม่อยู่" เมื่อไม่ได้วางการ์ดไว้ตั้งแต่ต้น
2. ทำไม AI agent คิดเงินไม่เหมือนค่า Netflix รายเดือน
กับดักที่อันตรายที่สุดของคนที่เพิ่งเริ่มใช้ AI คือการตั้งงบ AI เหมือน "ค่า subscription รายเดือนคงที่" แบบ Netflix หรือ Office 365 ที่จ่ายต่อที่นั่ง (seat license) ความหมายของโมเดลนี้คือจ่ายต่อหัวเป็นราคาตายตัว ใช้มากหรือใช้น้อยก็จ่ายเท่ากัน ทำให้ตั้งงบล่วงหน้าได้แม่นยำ แต่เครื่องมือ AI agent ส่วนใหญ่ไม่ได้คิดเงินแบบนั้น มันคิดแบบ usage-based คือจ่ายตาม token (หน่วยข้อมูลที่โมเดลประมวลผล) ที่ใช้จริง ยิ่งใช้มากก็ยิ่งจ่ายมาก โดยไม่มีเพดานในตัวเอง

คำถามต่อมาคือทำไมโหมด agentic ถึงกินเงินมากกว่าการแชตถามตอบหลายเท่า คำตอบอยู่ที่วิธีทำงานของมัน เวลาแชตถามคำถามเดียว โมเดลรับข้อความเข้าไปไม่กี่พันโทเค็นแล้วตอบกลับ จบในรอบเดียว แต่งานแบบ agentic หนึ่งงานคือ AI อ่านไฟล์ทั้งโปรเจกต์ เขียนโค้ด รันเทสต์ เห็น error แก้ แล้ววนกลับไปทำใหม่หลายรอบจนเสร็จ ทุกรอบของลูปนี้กินโทเค็น และที่สำคัญกว่านั้นคือ context (บริบทที่ส่งให้โมเดล) ทั้งก้อนถูกคิดเงินซ้ำในทุกขั้นตอน
เอกสารราคาอย่างเป็นทางการของ Anthropic อธิบายกลไกนี้ไว้ชัด การอ่านไฟล์หนึ่งหน้าเว็บขนาดกลางดึงข้อมูลเข้ามาราว 2,500 โทเค็น ส่วนเอกสารขนาดใหญ่หนึ่งหน้าอาจถึง 25,000 โทเค็น เมื่อ AI agent อ่านไฟล์ทั้งหมดนี้เข้ามา ทุกอย่างกลายเป็น context ที่ต้องจ่ายเงิน และโมเดลรุ่นใหม่ที่รองรับ context window ขนาดใหญ่ถึง 1 ล้านโทเค็นยิ่งทำให้ agent ที่ทำงานยาวต้องจ่ายค่า context เดิมซ้ำในทุกสเต็ป สรุปสั้นๆ คือ ต้นทุนไม่ได้ขึ้นกับว่า "คนถามกี่คำถาม" แต่ขึ้นกับว่า "agent อ่านและวนซ้ำมากแค่ไหน"
นี่คือเหตุผลเชิงกลไกว่าทำไมการใช้งานของ Uber "เพิ่มเท่าตัว" ขณะที่จำนวนวิศวกรเท่าเดิม และคำว่า "เงียบ" ก็อยู่ตรงนี้ คือระหว่างทางไม่มีใบแจ้งเตือนว่าใช้ไปเท่าไรแล้ว เห็นบิลอีกทีตอนสิ้นเดือน เหมือนเปิดก๊อกน้ำทิ้งไว้แล้วมาเห็นค่าน้ำตอนบิลมา ซึ่งนี่เองเป็นเหตุผลที่ Uber ตัดสินใจทำแดชบอร์ดและตั้งเพดานในเวลาต่อมา
3. ปัญหาไม่ได้อยู่ที่ AI แต่อยู่ที่การวัดผิดตัวแปร
ถ้ามองให้ลึกกว่าตัวเลข จุดพลาดจริงของ Uber ไม่ได้อยู่ที่เครื่องมือ AI แต่อยู่ที่ระบบแรงจูงใจ (incentive) ที่บริษัทวางไว้ ตามรายงานของ Fortune Uber กระตุ้นให้พนักงานใช้ AI "ให้เยอะที่สุด" และทำกระดานจัดอันดับทีมตามปริมาณการใช้งาน AI รวม วิธีนี้เร่ง adoption (อัตราการนำไปใช้) ได้จริง แต่มันไป optimize ผิดตัวแปร เพราะสิ่งที่ถูกวัดและให้รางวัลคือ "ปริมาณการใช้" ไม่ใช่ "คุณค่าที่ส่งมอบ"
เมื่อสิ่งที่ถูกวัดคือปริมาณการใช้ คนก็จะ maximize การใช้ตามธรรมชาติ เพราะนั่นคือสิ่งที่กระดานจัดอันดับให้รางวัล หลักการเบื้องหลังเรื่องนี้เรียบง่ายแต่สำคัญ การวัด adoption นั้นง่าย เพราะนับได้ว่ามีกี่คนใช้และใช้ไปกี่โทเค็น แต่การวัด value นั้นยาก เพราะต้องตอบให้ได้ว่างานที่ AI ช่วยทำนั้นสร้างผลลัพธ์เพิ่มขึ้นจริงแค่ไหน เมื่อวัดอย่างง่ายแล้วผูกรางวัลไว้กับมัน ผลที่ได้จึงเป็นการแข่งกัน "ใช้เยอะ" โดยไม่มีใครรับผิดชอบว่า "ใช้แล้วได้อะไรกลับมา"
บทเรียนข้อนี้ใช้ได้กับทุกองค์กรที่กำลังผลักดัน AI ตัวเลข adoption ที่สวยงาม เช่น "พนักงาน 90% ใช้ AI แล้ว" ฟังดูดีแต่ไม่ได้บอกว่าธุรกิจได้ผลลัพธ์เพิ่มขึ้นจริงหรือไม่ การหลงดีใจกับตัวเลข adoption โดยไม่ดูผลลัพธ์ปลายทางคือกับดักเดียวกับที่ Uber เจอ
4. ROI ที่ลากเส้นยังไม่ติด มุมมองที่ผู้บริหารพูดตรงผิดปกติ
สิ่งที่ทำให้เคสนี้น่าเชื่อถือคือคำพูดของผู้บริหารระดับสูงที่ตรงไปตรงมาผิดปกติ Andrew Macdonald ซึ่งเป็น President และ COO ของ Uber พูดในพอดแคสต์ Rapid Response ถึงความเชื่อมโยงระหว่างยอดใช้ AI กับฟีเจอร์ที่ลูกค้าได้รับจริงว่า "That link is not there yet" หรือ "เส้นเชื่อมตรงนั้นยังลากไม่ติด" ตามรายงานของ Fortune
เขาขยายความต่อว่า อาจจะมีงานที่ถูกส่งมอบเพิ่มขึ้นโดยปริยายอยู่บ้าง แต่มันยากมากที่จะลากเส้นจากตัวเลขการใช้ AI ไปยังข้อสรุปว่า "ตอนนี้เราผลิตฟีเจอร์ที่เป็นประโยชน์ต่อผู้ใช้เพิ่มขึ้น 25%" ตรงนี้ต้องเข้าใจให้ถูกว่าตัวเลข 25% เป็นเพียงตัวอย่างเชิงวาทศิลป์ที่ COO ยกขึ้นมาเพื่ออธิบายช่องว่างของการวัดผล ไม่ใช่ตัวเลขจริงที่ Uber วัดได้ และเขาสรุปว่า ถ้าลากเส้นตรงไปยังฟีเจอร์ที่ส่งถึงผู้ใช้จริงไม่ได้ การแลกค่าใช้จ่ายก้อนนี้ก็ justify ได้ยากขึ้น
สิ่งที่ Uber เจอไม่ใช่เรื่องเฉพาะตัว แต่สะท้อนปัญหาทั้งวงการ รายงาน "The GenAI Divide" ของ MIT NANDA ที่เผยแพร่ในปี 2025 พบว่าราว 95% ของโครงการนำร่อง (pilot) ด้าน generative AI ในองค์กรไม่เห็นผลต่อ P&L ที่วัดได้ ตามรายงานของ Fortune จุดสำคัญที่ต้องเข้าใจให้ถูกคือ ตัวเลข 95% นี้สะท้อนปัญหาเรื่อง "การวัดผลและการนำไป integrate เข้ากับงานจริง" ไม่ใช่ว่า "โมเดล AI ห่วยหรือใช้ไม่ได้" รายงานชี้ว่ารากของปัญหาคือ learning gap คือเครื่องมือทั่วไปทำงานให้ปัจเจกได้ แต่ไม่ได้เรียนรู้หรือปรับตัวเข้ากับ workflow ขององค์กร และพบว่าการซื้อจาก vendor เฉพาะทางสำเร็จราว 67% ขณะที่การสร้างเองสำเร็จเพียงหนึ่งในสามของนั้น
อย่างไรก็ตาม เรื่องนี้ไม่ใช่ "AI ไม่เวิร์ก" และ Uber เองก็ยัง bullish กับ AI อยู่ Dara Khosrowshahi ซึ่งเป็น CEO ระบุว่าราว 10% ของโค้ดที่ commit แล้วสร้างโดย autonomous agent ตามรายงานของ Fortune ขณะที่ฝั่ง CTO ระบุว่าราว 11% ของการอัปเดตโค้ดฝั่ง backend เขียนโดย AI agent ตามรายงานของ Yahoo Finance สรุปคือ AI ทำงานได้จริง เพียงแต่ ROI ยังวัดยากและต้นทุนต้องคุมให้อยู่ ทั้งสองเรื่องนี้แยกกันคนละประเด็น
5. การ์ดคุมต้นทุนที่ทีมไทยก็อปไปวางได้ทันที
สิ่งที่ Uber ทำหลังเจอปัญหาน่าสนใจตรงที่บริษัทไม่ได้แบน AI แต่เลือกวางการ์ด 3 ชั้น ตามรายงานของ Bloomberg ที่ถูกอ้างต่อโดย TechCrunch และ PYMNTS คือ ตั้งเพดาน $1,500 ต่อคนต่อเครื่องมือต่อเดือน โดยแยกเพดานต่อเครื่องมือ (ใช้ tool หนึ่งหมดแล้วไม่ดึงโควตามาจากอีก tool) ทำแดชบอร์ดที่พนักงานทุกคนเห็นยอดการใช้ของตัวเองได้ และเปิดให้ขออนุมัติถ้าจำเป็นต้องใช้เกินเพดาน
โฆษกของ Uber วางกรอบการตั้งเพดานนี้ว่าเป็น "วิธีที่ตรงไปตรงมาในการส่งเสริมการนำ agentic AI มาใช้และทดลองในระดับองค์กรอย่างมีความรับผิดชอบ" ตามรายงานของ PYMNTS นั่นหมายความว่ากรอบคิดของ Uber คือการตั้งเพดานเพื่อให้ทดลองต่อได้อย่างยั่งยืน ไม่ใช่การถอยหลังออกจาก AI
จากสิ่งที่ Uber ทำ บวกกับกลไกที่มีในเอกสารทางการของ Anthropic สามารถสรุปออกมาเป็นคันโยกคุมต้นทุน AI 5 ข้อที่ทีมไทยทุกขนาดเอาไปวางได้เลย
- ตั้งเพดานต่อคนหรือต่อเครื่องมือ กำหนดตัวเลขสูงสุดต่อเดือนที่ชัดเจน แบบที่ Uber ตั้งไว้ที่ $1,500 ต่อเครื่องมือ แทนที่จะปล่อยให้ค่าใช้จ่ายไหลไปเรื่อยๆ โดยไม่มีกำแพง
- เลือกโมเดลให้พอดีกับงาน เอกสารของ Anthropic ระบุว่า output token แพงกว่า input token ราว 5 เท่าในทุกโมเดล และรุ่นแรงสุดอย่าง Opus มีราคาแพงกว่ารุ่นประหยัดอย่าง Haiku ราว 5 เท่า การเลือกโมเดลให้พอดีงาน (งานง่ายใช้ Haiku, งานทั่วไปใช้ Sonnet, เก็บ Opus ไว้งานที่ยากจริงๆ) จึงเป็นคันโยกที่สร้างผลต่างมากที่สุด
- เปิด prompt caching สำหรับงานที่ใช้ context เดิมซ้ำ เช่นทำงานบนโค้ดเบสเดิมต่อเนื่อง การอ่านจาก cache มีต้นทุนเพียง 10% ของราคา input ปกติ หรือประหยัดได้ราว 90% สำหรับโทเค็นที่ใช้ซ้ำ
- ใช้ batch กับงานที่ไม่เร่ง งานที่ไม่ต้องการคำตอบทันทีสามารถส่งผ่าน Batch API ซึ่งลดราคาทั้ง input และ output ลง 50%
- ทำแดชบอร์ดติดตามและประตูขออนุมัติ ให้ทุกคนเห็นยอดการใช้ของตัวเองแบบ real-time พร้อมระบบขออนุมัติเมื่อจะใช้เกินเพดาน เพราะการเห็นตัวเลขเฉยๆ ไม่พอ ต้องมีกลไกที่กั้นก่อนจ่ายจริงด้วย
ข้อสุดท้ายนี้สำคัญกว่าที่คิด เพราะหัวใจของบทเรียน Uber คือ visibility ไม่เท่ากับ control การเห็นบิลหรือแดชบอร์ดเป็นแค่การมองเห็น แต่สิ่งที่หยุดงบไม่ให้บานปลายคือ enforcement คือเพดานและประตูขออนุมัติที่กั้นไว้ก่อนค่าใช้จ่ายจะเกิดจริง
6. หลักคิดเดียวที่อยากให้จำ
ถ้าจะสรุปเรื่อง Uber ให้เหลือสิ่งเดียวที่เอาไปใช้ได้ ก็คือเรื่องของการวางแรงจูงใจให้ถูกตัวแปร อย่าผูกรางวัลหรือ KPI ไว้กับ "ปริมาณการใช้ AI" เพราะนั่นคือสิ่งที่ทำให้คนแข่งกันเผางบโดยไม่มีใครดูผลลัพธ์ ให้ผูกไว้กับ "ผลลัพธ์หรือฟีเจอร์ที่ส่งมอบจริง" แทน แล้ว AI จะกลายเป็นเครื่องมือที่สร้างมูลค่า ไม่ใช่หลุมที่ดูดงบ
และถ้าแม้แต่ Uber ที่มีงบ R&D ระดับพันล้านดอลลาร์ต่อไตรมาสยังคุมไม่อยู่จนต้องตั้งเพดาน ธุรกิจไทยที่มีงบจำกัดก็ยิ่งต้องวางการ์ดเหล่านี้ตั้งแต่วันแรกที่เริ่มเอา AI agent เข้ามาใช้ ไม่ใช่รอให้บิลมาก่อนแล้วค่อยตั้งหลัก
ที่มา: TechCrunch, Bloomberg, PYMNTS, Fortune (COO), Yahoo Finance / The Information, Fortune (MIT 95%), Uber Q1 2026 earnings (SEC), Anthropic pricing docs
ชอบเรื่องแนวนี้ มีอีบุ๊คฟรีให้อ่านต่อ
ChatGPT Work ฉบับเข้าใจง่าย มอบงานให้ AI ทำจนจบ ตั้งแต่งานแรกจนถึงงานอัตโนมัติ พร้อม workflow ใช้ได้จริง 8 แบบ
กดสมัครแล้วเราจะส่งเทคนิค AI และของแจกใหม่ๆ ให้ทางอีเมล เลิกรับได้ตลอด



