Code Review Checklist 5 มิติ: Correctness, Security, Performance, Style, Test Coverage
พรอมต์สำหรับ developer ที่ต้องการ code review เชิงลึก ครอบคลุม 5 มิติหลัก พร้อมระบบ status icon และ verdict สรุป ช่วยให้ review ได้ครบถ้วนและสม่ำเสมอทุกครั้ง
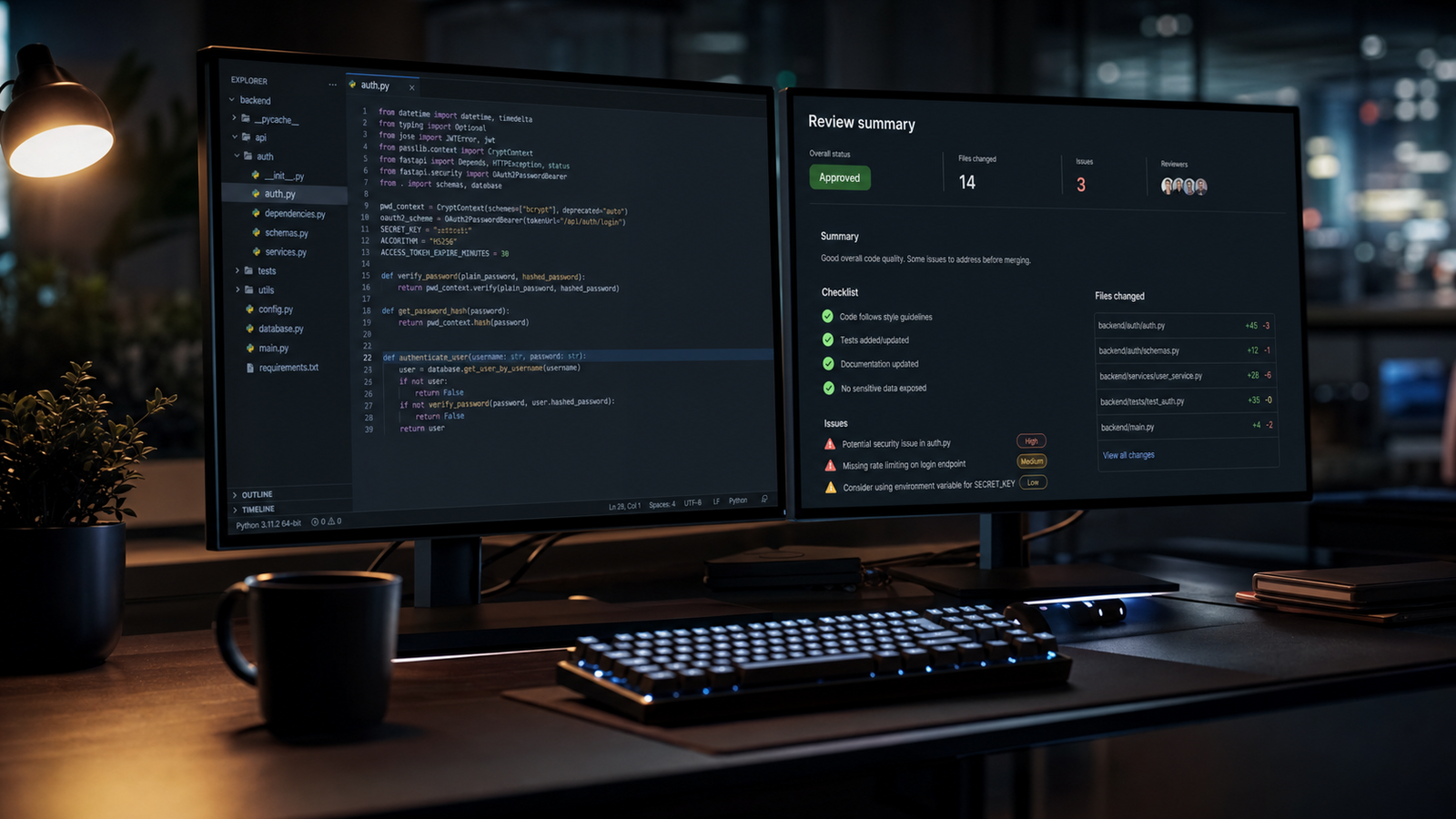
คัดลอกพรอมต์ฉบับมีตัวแปร {{...}} ไปแก้ไขในเครื่องมือของคุณเอง
ตัวอย่างผลลัพธ์ที่จะได้
ก่อนเริ่มลงมือปรับพรอมต์ ดูตัวอย่างผลลัพธ์ที่คุณจะได้จริงเพื่อให้แน่ใจว่าพรอมต์นี้ตรงกับงานที่ต้องการ
1. Correctness ⚠️
- ❌ ไม่มีการตรวจสอบว่า
resultว่างเปล่าก่อน accessresult[0]— จะเกิดIndexErrorหาก user ไม่พบใน database - ⚠️ ไม่มีการ validate ประเภทของ
user_idก่อนนำไปใช้ — หาก client ส่ง non-string มาอาจเกิด runtime error - ✅ Logic หลักของการ query ตรงกับ intent ที่ระบุใน context
2. Security ❌
- ❌ SQL Injection: ต่อ string โดยตรงด้วย
"SELECT * FROM users WHERE id = " + user_id— ต้องเปลี่ยนเป็น parameterised query เช่นdb.execute("SELECT * FROM users WHERE id = ?", (user_id,))โดยเด็ดขาด - ❌ Sensitive data leak:
print(f"Fetched user: {result[0]}")อาจ log ข้อมูล sensitive เช่น password hash หรือ PII ออก stdout/log file - ⚠️ ไม่มีการตรวจสอบ authorisation ว่า caller มีสิทธิ์ดู user คนนี้หรือไม่
3. Performance ⚠️
- ⚠️
SELECT *ดึงทุก column — ควรระบุ column ที่จำเป็น (เช่นid, name, email) เพื่อลด network payload - ✅ ไม่มี N+1 query ใน function นี้
- ✅ ไม่มี loop ที่ไม่จำเป็น
ปรับให้เข้ากับงานของคุณ
แก้ค่าตัวแปรด้านล่าง พรอมต์ฉบับสมบูรณ์จะอัปเดตอัตโนมัติ พร้อมคัดลอกไปวางใน Claude หรือ ChatGPT ได้ทันที
ภาษาโปรแกรมที่ใช้เขียนโค้ด เช่น Python, TypeScript, Go, Java
วางโค้ดที่ต้องการให้ review ทั้ง function หรือ class
อธิบายว่าโค้ดนี้ทำอะไร อยู่ใน context ไหน และ input มาจากไหน
## Code context
ฟังก์ชัน get_user() รับ user_id จาก HTTP request parameter แล้ว query ข้อมูลผู้ใช้จาก database เพื่อส่งคืนเป็น API response
## Code to review
```Python
def get_user(user_id):
query = "SELECT * FROM users WHERE id = " + user_id
result = db.execute(query)
print(f"Fetched user: {result[0]}")
return result[0]
```
## Review dimensions
### 1. Correctness
- Does the logic match the intended behaviour?
- Are edge cases handled (null, empty, overflow, off-by-one)?
- Are all error conditions caught and handled?
### 2. Security
- Is user input validated and sanitised before use?
- Are there injection risks (SQL, XSS, shell command)?
- Are secrets or sensitive data exposed in logs or responses?
- Are authentication and authorisation checks present where needed?
### 3. Performance
- Are there unnecessary loops, N+1 queries, or redundant computation?
- Is memory allocation proportionate to the task?
- Are expensive operations cached or deferred where appropriate?
### 4. Style & Readability
- Do names follow project conventions and clearly express intent?
- Are functions/classes small, single-purpose, and well-named?
- Is non-obvious logic accompanied by a brief comment?
### 5. Test Coverage
- Are unit tests present for the new or changed logic?
- Do tests cover both happy paths and edge/error cases?
- Are assertions specific and mocks meaningful?
## Output format
Return a Markdown report structured as:
- One H2 heading per dimension with an overall status icon
- Bullet-point findings (with ✅ / ⚠️ / ❌ prefix per item)
- A final **Verdict** section: `Approve` | `Request Changes` | `Reject` with a one-sentence rationale
เข้าใจเทคนิคที่ซ่อนอยู่
คลิกที่ส่วนไฮไลต์ในพรอมต์เพื่อกระโดดไปดูคำอธิบายเทคนิคแต่ละจุด ใช้ความเข้าใจนี้เพื่อปรับพรอมต์อื่นของคุณเองในภายหลัง
## Code context
{{context}}6
## Code to review
```{{language}}
{{code}}
```
## Review dimensions
### 1. Correctness
- Does the logic match the intended behaviour?
- Are edge cases handled (null, empty, overflow, off-by-one)?
- Are all error conditions caught and handled?
### 2. Security
- Is user input validated and sanitised before use?
- Are there injection risks (SQL, XSS, shell command)?
- Are secrets or sensitive data exposed in logs or responses?
- Are authentication and authorisation checks present where needed?3
### 3. Performance
- Are there unnecessary loops, N+1 queries, or redundant computation?
- Is memory allocation proportionate to the task?
- Are expensive operations cached or deferred where appropriate?
### 4. Style & Readability
- Do names follow project conventions and clearly express intent?
- Are functions/classes small, single-purpose, and well-named?
- Is non-obvious logic accompanied by a brief comment?
### 5. Test Coverage
- Are unit tests present for the new or changed logic?
- Do tests cover both happy paths and edge/error cases?
- Are assertions specific and mocks meaningful?
## Output format
Return a Markdown report structured as:
- One H2 heading per dimension with an overall status icon
- Bullet-point findings (with ✅ / ⚠️ / ❌ prefix per item)
- A final **Verdict** section: `Approve` | `Request Changes` | `Reject` with a one-sentence rationale5
แตะส่วนที่ไฮไลต์เพื่อดูคำอธิบายเทคนิคแต่ละจุด · {{ }} คือตัวแปรที่ปรับได้
"You are a senior software engineer conducting a thorough code review."
การกำหนด role เป็น senior engineer ทำให้โมเดลเลือกใช้มาตรฐานระดับสูงในการประเมิน แทนที่จะ review แบบผิวเผินในฐานะผู้อ่านทั่วไป
"evaluate it across exactly five dimensions"
การระบุจำนวนมิติแน่นอน (exactly five) บังคับให้โมเดลครอบคลุมทุกมิติโดยไม่ข้ามหรือรวมมิติเข้าด้วยกัน ทำให้ผลลัพธ์สม่ำเสมอทุกครั้ง
"- Is user input validated and sanitised before use? - Are there injection risks (SQL, XSS, shell command)? - Are secrets or sensitive data exposed in logs or responses? - Are authentication and authorisation checks present where needed?"
การแตก dimension แต่ละมิติเป็น sub-question เฉพาะเจาะจง ป้องกันไม่ให้โมเดลตอบแบบกว้างเกินไป และบังคับให้ตรวจสอบประเด็นที่สำคัญแต่มักถูกมองข้าม
"status icons (✅ pass · ⚠️ warning · ❌ issue)"
ระบบ icon 3 ระดับบังคับให้โมเดลแยกแยะความรุนแรงของปัญหา ทำให้ reviewer สามารถ prioritize สิ่งที่ต้องแก้ไขก่อนได้ทันที
"Return a Markdown report structured as: - One H2 heading per dimension with an overall status icon - Bullet-point findings (with ✅ / ⚠️ / ❌ prefix per item) - A final **Verdict** section: `Approve` | `Request Changes` | `Reject` with a one-sentence rationale"
การกำหนด output format อย่างละเอียดทำให้ผลลัพธ์นำไปใช้ใน PR comment หรือ documentation ได้ทันที โดยไม่ต้องจัดรูปแบบเพิ่มเติม
"## Code context {{context}}"
การให้ context แยกออกมาจากโค้ด ช่วยให้โมเดลเข้าใจ intent ของโค้ดก่อน review จึงสามารถตรวจจับ logic ที่ผิดจาก requirement ได้แม่นยำกว่าการดูโค้ดอย่างเดียว
เห็นความต่างระหว่างพรอมต์ทั่วไปกับพรอมต์ที่ใช้เทคนิค
คนส่วนใหญ่เริ่มต้นด้วยคำสั่งสั้น ๆ แบบพรอมต์ที่ใช้กันทั่วไป แต่ผลลัพธ์มักไม่ตรงใจและต้องถามซ้ำหลายรอบ พรอมต์แบบที่ใช้เทคนิคข้างต้นช่วยแก้ปัญหานี้
ช่วย review โค้ดนี้ให้หน่อย
กำหนด role เป็น senior engineer, แบ่ง 5 มิติชัดเจนพร้อม sub-question, ใช้ status icon 3 ระดับ, กำหนด output format แบบ Markdown, จบด้วย Verdict พร้อม rationale


