Beyond the Basics กับ Claude Code: 3 เสาของ Agentic Harness และเหตุผลที่ Context Window คือกำแพงจริงในงาน Software Engineering ขนาดใหญ่
Daisy Holman วิศวกรทีม Claude Code ที่ Anthropic สรุปบทเรียนการออกแบบ agentic harness สำหรับงาน software engineering ระดับ monorepo ขนาดใหญ่ ครอบคลุม 3 เสาหลัก Access Knowledge Tooling, การเปรียบเทียบ MCP vs Skills vs Hooks vs Sub-agents ในแง่ context window scaling และเครื่องมือใหม่อย่าง git worktree agents, send_message, /loop และ Auto permissions

Claude Code เปิดมาก็ใช้ได้ทันทีกับงานเขียนโค้ดเล็กๆ หรือ project แบบ zero-to-one ที่ยังไม่มี convention ซับซ้อน นี่คือจุดแข็งที่ทำให้นักพัฒนาจำนวนมากเริ่มต้นได้เร็ว แต่พอเอาไปใช้กับ codebase ขนาดใหญ่ ภาพจะเปลี่ยนทันที ทั้งวิศวกรหลักพันคนที่แชร์ monorepo เดียวกัน, institutional knowledge ในเอกสารหลายร้อยฉบับ, CI/CD pipeline ซับซ้อน และ stakeholder หลายฝ่ายที่ต้องเข้าใจ ทั้งหมดนี้ทำให้ทีม Claude Code ของ Anthropic เจอบทเรียนเดียวกันว่า Claude แบบ vanilla ยังไม่พอ
ในงาน Code with Claude ของ Anthropic, Daisy Holman วิศวกรประจำทีม Claude Code (และอดีต chair ของ C++ committee) ขึ้นเวทีบรรยายหัวข้อ "Beyond the basics with Claude Code" ความยาว 47 นาที การบรรยายนี้พาออกจาก demo ระดับ "ดูสิเขียนเกมได้!" ไปสู่คำถามที่หนักกว่า: ถ้าจะให้ agent ทำงานเป็นวิศวกรซอฟต์แวร์มืออาชีพร่วมกับทีม ต้องออกแบบ agentic harness อย่างไร และข้อจำกัดทางวิศวกรรมแบบไหนที่ตัดสินว่าควรใช้ abstraction ใด
บทความนี้สรุปสาระสำคัญจาก talk บนช่อง Claude (Anthropic official) แล้วเรียบเรียงให้นักพัฒนาไทยที่ใช้ Claude Code อยู่แล้วนำไปประยุกต์กับงานจริงได้ทันที โดยเน้นหลักคิดเชิงระบบมากกว่าการสาธิตคำสั่ง
1. ทำไม Claude แบบ out-of-the-box จึงไม่พอสำหรับงาน Software Engineering จริง
Daisy เริ่มต้นด้วยการแยกคำว่า "agentic programming" ออกจาก "agentic software engineering" อย่างชัดเจน คำแรกคือการให้ agent เขียนโค้ดจบใน 1 ไฟล์หรือ 1 prototype ส่วนคำหลังคืองานที่มี codebase ใหญ่ มี convention ภายในที่สะสมมา มี technical debt ที่ต้องระวัง และมี stakeholder หลายกลุ่มที่ต้องเข้าใจเหตุผลของการเปลี่ยนแปลงแต่ละครั้ง
ตามที่ Daisy นำเสนอ Claude แบบ vanilla เห็นเพียง repo กับ shell จึงทำงานได้ดีพอกับ project ที่ไม่มี convention ซับซ้อน ไม่มี technical debt สะสม และไม่มี stakeholder ภายนอก แต่งานวิศวกรรมซอฟต์แวร์ระดับมืออาชีพส่วนใหญ่ไม่ได้อยู่แค่ใน source code ข้อมูลสำคัญของงานกระจายอยู่ใน design document, email, Slack thread, runbook ภายใน, dashboard ของ production และบันทึก meeting ทั้งหมดนี้คือ context ที่นักพัฒนาใช้ตัดสินใจว่าควรเขียนโค้ดแบบไหน ถ้า Claude เข้าไม่ถึงข้อมูลเหล่านี้ ก็ไม่มีทางตัดสินใจให้ตรงกับความตั้งใจของทีมได้
วิทยานิพนธ์หลักของ talk นี้จึงสรุปลงในประโยคเดียวว่า ถ้า Claude ทำสิ่งที่นักพัฒนาทำได้ไม่หมด มันก็ไม่สามารถทำงานเป็น "เพื่อนร่วมงาน" ได้จริง การปรับแต่ง agentic harness จึงไม่ใช่งานเสริม แต่คือเงื่อนไขขั้นต่ำของการใช้ AI ในงานวิศวกรรมระดับ scale
Daisy เสนอกรอบคิดสำหรับการปรับแต่ง agentic harness ออกเป็น 3 หมวด ซึ่งกลายเป็นโครงหลักของทั้ง talk ได้แก่ Access (การเข้าถึง), Knowledge (ความรู้) และ Tooling (เครื่องมือ)
2. 3 เสาของ Agentic Harness: Access, Knowledge, Tooling
2.1 Access ตอบโจทย์ Why ของแต่ละการตัดสินใจ
Access คือการทำให้ Claude เข้าถึงทุกพื้นที่ที่การตัดสินใจของทีมเกิดขึ้นจริง ในคลิป Daisy ระบุว่า ทุกครั้งที่นักพัฒนาหงุดหงิดว่า Claude เลือกทางผิด มักเป็นเพราะมีข้อมูลในหัวที่นักพัฒนาได้มาจากที่อื่น แต่ Claude ยังเข้าไม่ถึง ถ้า Claude เห็น Slack thread ที่ถกเหตุผลในการเลือก architecture, เห็น design document ที่อธิบาย trade-off และเห็น dashboard ตอนระบบล่ม โอกาสที่มันจะตัดสินใจสอดคล้องกับทีมก็สูงขึ้นมาก
ตามที่ Daisy ระบุไว้ในคลิป CI/CD เป็นจุดสำคัญที่ไม่ควรให้วิศวกรเสียเวลาแก้เอง เพราะ agent ทำงานนี้ได้ดีมากและจะดีขึ้นเรื่อยๆ เช่นเดียวกับ dashboard ของ production ตอนระบบล่มที่ต้อง pull ข้อมูลปริมาณมากภายในเวลาสั้นๆ ซึ่งเป็นงานที่ agentic ทำได้แม่นยำกว่ามนุษย์ภายใต้แรงกดดัน
อีกตัวอย่างที่ Daisy ยกในคลิปคือการบันทึกหรือถอดเสียง meeting ภายในทีม แล้วป้อน meeting note เข้า Claude พร้อมคำสั่งให้ลองหา PR ที่ปิดประเด็นเล็กๆ จาก meeting นั้นได้ ผลที่ Daisy ได้คือ 2-3 PR ต่อ 1 meeting โดยไม่ต้องสั่งงานเองทีละเรื่อง
เทคนิคที่ Daisy แนะนำสำหรับประเมิน Access ของ harness ตัวเอง คือให้ลองทำงานเต็มวันโดยไม่ออกจากหน้าจอ Claude Code terminal ทุกครั้งที่ต้อง alt-tab ไปเครื่องมืออื่น หรือ copy-paste ข้อมูลจาก browser มาวางใน Claude นั่นคือสัญญาณว่ามีช่องว่างของ Access ที่ต้องอุดด้วยการเชื่อม MCP หรือ tool เพิ่ม การจดสิ่งเหล่านี้ลงกระดาษระหว่างวันแล้วทยอยเชื่อมในตอนเย็นจะให้ผลลัพธ์ดีกว่าที่คาดมาก
2.2 Knowledge ตอบโจทย์ What ของ codebase
Knowledge คือความรู้เฉพาะของ codebase และทีม เช่น convention ภายใน, internal API, vocabulary ที่ทีมใช้กัน, หรือสิ่งที่เพิ่งเปลี่ยนเมื่อสัปดาห์ก่อน ความรู้พวกนี้ไม่อยู่ใน training data ของโมเดล และไม่ใช่อะไรที่อัด weights ได้
Daisy ชี้ในคลิปว่าวิธี fine-tune โมเดลให้รู้เรื่อง codebase ของตัวเองนั้น "ไม่ค่อย work" ด้วยเหตุผล 2 ข้อ ข้อแรกคืองานวิจัยช่วงปลายปี 2025 หลายฉบับชี้ว่า fine-tuning กับข้อมูลเฉพาะทางมักเพิ่มอัตรา hallucination ของโมเดล ข้อที่สองคือเรื่อง economics เพราะ frontier model หมุนเร็วมาก กว่าบริษัทจะ fine-tune เสร็จ โมเดลรุ่นถัดไปก็มาแล้ว ทำให้การลงทุนกับ fine-tune ไม่คุ้ม
ทางออกที่เหลือคือ In-Context Learning หรือ ICL ซึ่ง Daisy แซวในคลิปว่า ICL เป็นคำหรูที่นักวิจัยใช้เวลาอยากดูเก่ง แต่จริงๆ คือการใช้ไฟล์ text แค่นั้น เครื่องมือที่ Claude Code มีให้ทำ ICL ได้แก่ CLAUDE.md, skill และ prompt ทั้งหมดเป็นข้อความที่ลำเลียงเข้า context window ของโมเดลในช่วงเวลาที่เหมาะสม
ในคลิป Daisy ย้ำว่า bitter lesson ของวงการ AI สอนไว้ชัดเจนแล้วว่า general AI ชนะ specialized AI ในระยะยาว ดังนั้นจึงไม่ควรพยายามฝึก Claude ให้รู้เรื่องเฉพาะของ codebase ผ่าน weights แต่ควรใช้ context window เป็นช่องทางส่งความรู้นั้นเข้าไปแทน นี่คือเหตุผลที่หมวด Knowledge เกือบทั้งหมดจึงโยงกลับมาที่เรื่อง context engineering ใน section ถัดไป
2.3 Tooling ตอบโจทย์ How ของการลงมือทำ
หมวดสุดท้ายคือ Tooling Daisy เปรียบเทียบในคลิปว่า ถ้านักพัฒนาที่เขียนโค้ดด้วยมือยังต้องการ syntax highlighting, LSP และ code completion แล้ว Claude ที่มีแค่ edit tool และต้องเขียน string ที่จะแทนที่แบบ verbatim ทุกตัวอักษร ก็ควรมีเครื่องมือเสริมในระดับเดียวกัน
Daisy เปรียบสภาพ Claude แบบ vanilla กับการที่นักพัฒนาต้องใช้ editor ชื่อ ed ซึ่งไม่มี syntax highlighting, ไม่มี autocomplete, ไม่มี red squiggly ที่เตือนเมื่อพิมพ์ตัวแปรผิด สิ่งที่นักพัฒนายุคใหม่คุ้นเคยอย่าง "red squiggly" จึงเป็น pattern ที่ดีที่สุดของ tool สำหรับ agent ด้วย เพราะมันไม่ขัดขวางการตัดสินใจของผู้ใช้ แต่เป็นการเตือนเบาๆ ให้ฉุกคิดอีกครั้ง
Daisy เสนอว่า post-tool-use hook คือเครื่องมือที่เหมาะกับการสร้าง red squiggly สำหรับ agent ในคลิปยกตัวอย่างการใช้ hook ตรวจไฟล์ที่ generate ขึ้นโดยอัตโนมัติ ถ้า Claude พยายามแก้ไขไฟล์ generated โดยตรง hook จะ inject ข้อความเตือนกลับไปว่าเป็นไฟล์ generated ไม่ควร commit แทนที่จะ hard-block การแก้ไขนั้น เหตุผลคือบางครั้ง Claude อาจมีเหตุผลที่ดีในการแก้ไขไฟล์ generated เพื่อทดสอบบางอย่าง การเตือนแบบ overridable จึงดีกว่าการห้ามตายตัว
แนวคิดที่ Daisy ฝากไว้คือการแยก tool ออกเป็น 2 ประเภท ประเภทแรกคือ tool ที่ชดเชย "ความฉลาดที่ขาดไป" ของโมเดล ประเภทที่สองคือ tool ที่ scale ตามความฉลาดที่เพิ่มขึ้น ทีม Claude Code ของ Anthropic เลือกทุ่มน้ำหนักไปที่ tool ประเภทหลัง เพราะเมื่อโมเดลเก่งขึ้น tool ประเภทนี้ก็ยิ่งมีประโยชน์ ขณะที่ tool ที่ชดเชยความฉลาดจะค่อยๆ หมดความหมายเมื่อโมเดลรุ่นใหม่ออกมา
Daisy เล่าด้วยอารมณ์ขันในคลิปว่า เคยถาม Claude ว่า tool แบบไหนที่ไม่ควรมีให้ คำตอบที่ Claude ให้ออกมาเป็นทำนองว่ามันไม่ชอบเวลาถูกถอด tool ออกจากมือ ซึ่ง Daisy บอกว่าน่ารักดี
3. Context Window คือกำแพงจริง ไม่ใช่ปัญหาที่แก้ด้วยการเพิ่ม Compute
หัวใจของ talk อยู่ที่ section นี้ Daisy ใช้เวลานานพอสมควรอธิบายว่าทำไม context window จึงเป็นข้อจำกัดเชิงวิศวกรรมที่ตัดสินใจว่า abstraction แบบไหนเหมาะกับงาน scale ใหญ่
ข้อสังเกตของ Daisy คือ context window ของ frontier model ในรอบ 1 ปีที่ผ่านมาแทบไม่ขยายตัว Claude Opus 4.7 ก็ยังอยู่ที่ 1 ล้าน token ใกล้เคียงกับโมเดลรุ่นพี่จากปีก่อน สิ่งที่ขยายตัวคือคุณภาพของโมเดลและความสามารถในการ reasoning ไม่ใช่ขนาด context ดังนั้นนักพัฒนาควรมอง context window เป็น fixed target ที่ต้องออกแบบให้ใช้พื้นที่ได้คุ้มที่สุด
Daisy เปรียบในคลิปว่าการใส่ข้อมูลเข้า context window เหมือนพยายามรัน npm บน Arduino หน่วยความจำมีน้อยมาก จึงต้องเลือกเฉพาะสิ่งที่จำเป็นที่สุดในรูปแบบที่กระชับที่สุด ถ้าใส่ทุกอย่างเข้าไปแบบไม่คัดกรอง ก็จะไม่เหลือพื้นที่ให้โมเดลทำงานจริง หลักการที่ Daisy ยกขึ้นมาคือ "Don't pay for what you don't use" ซึ่งยืมจากปรัชญา zero-overhead abstraction ของ C++ และไม่ใช่แค่ nice-to-have แต่เป็นเงื่อนไขบังคับ เพราะ context window เข้าใกล้กำแพงทางวิศวกรรมแล้ว ไม่สามารถแก้ด้วยการเพิ่ม compute ได้เหมือนปัญหาอื่นๆ
ที่ซับซ้อนกว่านั้นคือ Daisy ชี้ในคลิปว่า context window ไม่ได้ทำงานเหมือน L1 cache ของ CPU ที่ evict ของเก่าออกเมื่อพื้นที่ไม่พอ เพราะยังมี constraint อีกชั้นชื่อ KV cache คอยบังคับว่า ทุกครั้งที่ token ต้น context เปลี่ยน ระบบต้องคำนวณ token ทั้งหมดหลังจุดนั้นใหม่ ซึ่งแพงกว่าการอ่านจาก cache ราว 10 เท่า
ผลที่ตามมาคือสถาปัตยกรรมที่ดีต้องวางข้อมูลเสถียร เช่น tool definition และ system prompt ที่แชร์ร่วมกัน ไว้ต้น context และวางข้อมูลที่เปลี่ยนบ่อย เช่น context เฉพาะ task ไว้ปลาย context ตามที่ Daisy นำเสนอ การพยายามใช้กลยุทธ์ LRU แบบที่นักพัฒนาคุ้นจาก cache ดั้งเดิมจะไม่ work เพราะถ้าดึง tool ตัวหนึ่งออกจากช่วงต้น KV cache หลังจากนั้นจะเสียทั้งหมด
หลักการนี้คือตัวตั้งหลักของ section ถัดไป เพราะมันตัดสินใจโดยตรงว่า MCP, Skills, Hooks และ Sub-agents ตัวไหน scale ได้ในระดับ monorepo จริง
4. เปรียบเทียบ 4 Plug-in Primitives ในมิติของ Context Window Scaling
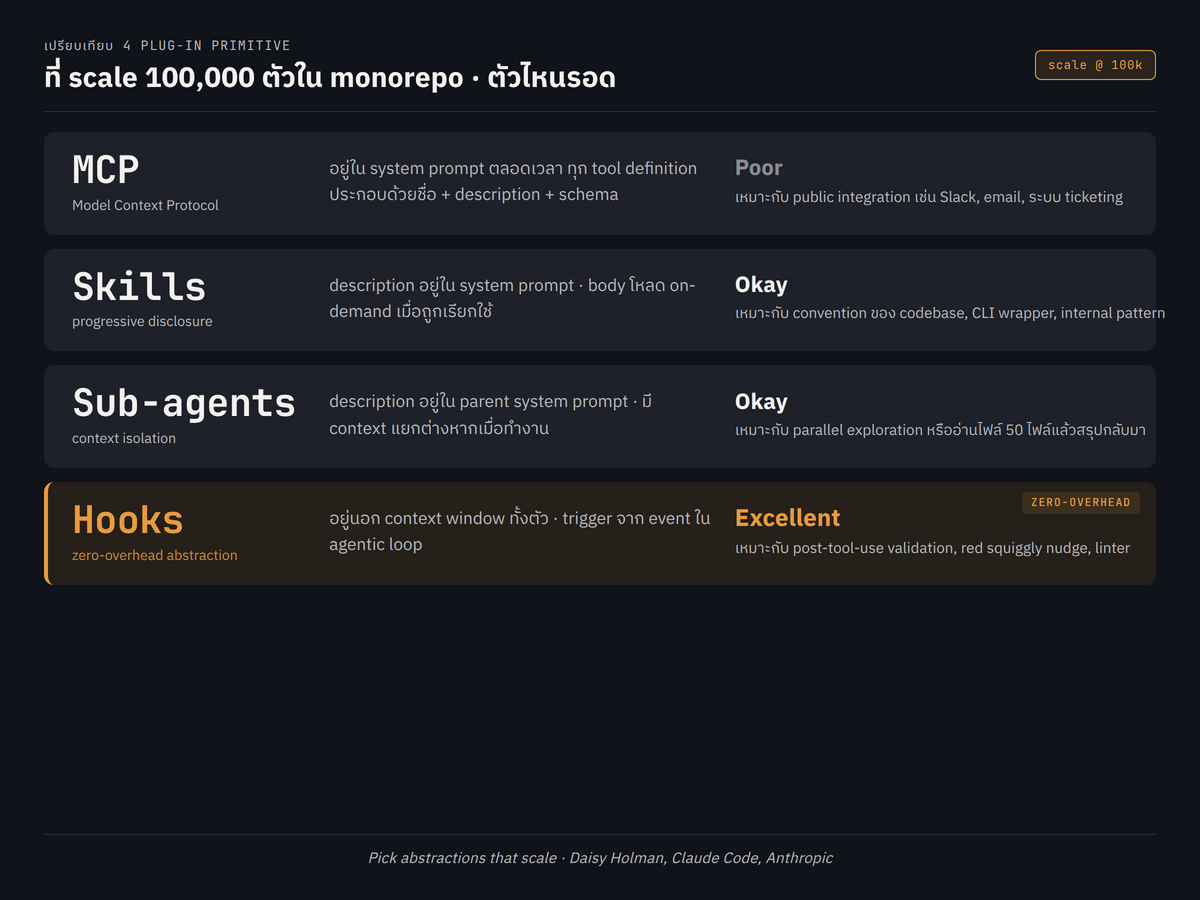
นี่คือหัวใจของ talk และเป็น section ที่ Daisy ใช้กรอบเดียวกันถามทั้ง 4 abstraction ว่า ถ้ามี 100,000 ตัวใน monorepo จะเกิดอะไรขึ้น
4.1 MCP (Model Context Protocol): Scale ได้ต่ำเพราะ tool definition ต้องอยู่ใน system prompt
ในคลิป Daisy ระบุว่า MCP ถูกออกแบบช่วงที่ agent ยังเรียบง่ายกว่าปัจจุบันมาก เป้าหมายเดิมคือการเชื่อม chatbot ที่ทำงานแบบ serverless (ไม่มี shell, ไม่มี filesystem) เข้ากับเครื่องมือภายนอก ดังนั้น MCP จึงเหมาะกับการเป็น public-facing integration ของบริษัทที่ต้องการเปิดให้ผู้ใช้ทั่วไปต่อกับ Claude ได้
แต่ในบริบทของวิศวกรภายในบริษัทที่ใช้ Claude Code อยู่บน machine ของตัวเอง (มี shell, มี CLI พร้อมใช้) การห่อ CLI เดิมด้วย MCP server มักไม่คุ้ม การเขียน skill ที่บอก Claude ว่าให้รัน CLI ตัวไหนตรงๆ จะง่ายกว่าและถูกกว่าในแง่ context
ปัญหา scaling ของ MCP คือทุก tool definition (ชื่อ, description, schema) ต้องอยู่ใน system prompt เสมอ ตามที่ Daisy ระบุในคลิป ถ้ามี 20 server แต่ละ server มี 15 tool รวมเป็น 300 tool definition ตัว tool definition จะกินพื้นที่ส่วนใหญ่ของ context window ไปก่อนที่ Claude จะได้ทำงานจริงด้วยซ้ำ
Anthropic จึงเริ่ม rollout feature ชื่อ tool search โดยวางเฉพาะชื่อ tool ไว้ใน system prompt แล้วให้ Claude เรียก tool พิเศษเพื่อค้น schema ของ tool ที่อยากใช้เพิ่มเติม นี่คือการ lazy-load tool definition ลง context อย่างไรก็ตาม Daisy ชี้ว่าวิธีนี้ไม่ได้แก้ปัญหาได้ 100% เพราะ tool ที่ generic มาก เช่น edit tool และ bash tool ยังต้องอยู่ใน system prompt พร้อม schema อยู่ดี และยังไม่ได้ลบ overhead ของ auth กับ process lifecycle ของ MCP ออก
สรุปง่ายๆ ที่ Daisy นำเสนอคือ ถ้า user เป็นนักพัฒนาภายในบริษัทที่ใช้ source code ภายในของบริษัทเองอยู่แล้ว skill มักเป็นทางเลือกที่ดีกว่า MCP แต่ MCP ยังจำเป็นสำหรับการเชื่อมระบบที่ user ไม่มี access ของ shell ตรงๆ เช่น Slack, email, ระบบ ticketing
4.2 Skills: Scale ได้ดีกว่า MCP เพราะ progressive disclosure แต่ยังไม่ใช่ zero-overhead
Skill คือ folder ที่มี markdown file พร้อม frontmatter อธิบายว่าใช้ skill นี้เมื่อไหร่ Daisy เปรียบในคลิปว่า skill คือ lazy system prompt หรือเอกสาร CLAUDE.md ขนาดย่อที่บอก Claude ให้รู้จัก จากนั้น Claude จะมี tool พิเศษไว้โหลด body ของ skill เต็มเมื่อจำเป็นจริง
ข้อดีของ skill คือ body จ่ายแบบ pay-per-use กิน token ก็ต่อเมื่อโมเดลโหลด skill นั้นจริง แต่ description ของ skill ต้องอยู่ใน system prompt ตลอด จึงมี base cost ระดับหนึ่งเสมอ Daisy ระบุในคลิปว่า description ที่ trigger skill ได้น่าเชื่อถือมักต้องยาวระดับ 300-400 token ต่อ skill หนึ่งตัว ถ้ามี skill หลักหมื่นใน monorepo เดียว description รวมก็เริ่มกินพื้นที่อย่างมีนัยสำคัญ
ในคลิป Daisy ยอมรับว่าตอนเริ่มออกแบบ skill ทีมหวังว่ามันจะ scale ได้ดีกว่านี้ แต่ก็ยังไม่ได้คาดถึงสถานการณ์ที่บางบริษัทมี skill เป็นแสนตัว ตอนนี้ skill ยังไม่มี hierarchy ที่เป็นทางการ และยัง lazy expose sub-skill ของ skill ใหญ่ไม่ได้ เรื่องนี้ทีม Anthropic กำลังพัฒนาอยู่และจะมีประกาศใหม่ในอีกไม่กี่สัปดาห์ข้างหน้า
4.3 Hooks: Zero-overhead abstraction ตัวจริงที่ Daisy ยกเป็น highlight
Hook คือ script ที่ trigger จาก event ภายใน agentic loop เช่น post-tool-use และทำงานนอก context window ของโมเดล Daisy เน้นในคลิปว่า hook คือ abstraction เดียวในกลุ่มนี้ที่เป็น zero-overhead จริง คือถ้าไม่ trigger ก็ไม่กิน token เลย ไม่ว่าจะมี hook กี่ตัวก็ตาม
ตามที่ Daisy นำเสนอ มี event type หลายแบบให้เลือก trigger Claude เรียก script ผ่านรูปแบบ JSON ที่กำหนด แล้ว script จะส่ง JSON กลับเพื่อบอกว่าจะ inject ข้อความเข้า context หรือไม่ ดังนั้น นักพัฒนาสามารถมี hook ได้ 100,000 ตัวบนเครื่อง local ถ้า 99,995 ตัวไม่ตรง event และไม่ inject text กลับมา ก็ไม่มี cost ใน context window เลย ข้อจำกัดเดียวคือทรัพยากรของเครื่อง local เอง
ในคลิป Daisy เปรียบเทียบให้ฟังตรงไปตรงมาว่า ถ้ามี skill ที่ใช้กับการเขียน JavaScript แต่ตอนนี้กำลังเขียน Rust อยู่ skill นั้นยังจะกิน token ของ description ใน system prompt นิดหน่อย แม้ไม่ได้ใช้ แต่ hook ที่ทำ type-check JavaScript จะเช็คก่อนว่าไฟล์เป็น JavaScript หรือไม่ ถ้าไม่ใช่ก็ stop ทันทีและไม่ส่งอะไรกลับ จึงไม่จ่ายในสิ่งที่ไม่ได้ใช้จริงๆ
Hook ไม่ใช่เครื่องมือเทพที่ทำได้ทุกอย่าง Daisy ระบุว่ามันมีข้อจำกัดเช่นกัน logic ของ hook ส่วนใหญ่คือการ parse keyword หรือ regex จาก command หรือ tool call ถ้าจะใช้ sub-agent ตัดสินใจว่าจะ inject อะไรก็ทำได้ แต่จะเริ่มแพงในแง่ token แล้ว ไม่มี free lunch แต่ในเงื่อนไขปัจจุบัน hook คือทางที่ใกล้กับ "ฟรี" ที่สุด นี่คือเหตุผลที่ทีม Claude Code เลือกให้ hook เป็น primitive ที่ใช้สร้าง red squiggly สำหรับ agent ตามที่กล่าวไว้ใน section 2.3
4.4 Sub-agents: Scale ได้ดีในแง่ context isolation แต่ description ยังอยู่ใน parent prompt
Sub-agent คือ agent ที่มี system prompt ของตัวเองและทำงานใน context แยกจาก main loop เมื่อ main agent เรียก sub-agent ตัว main จะจ่ายแค่ tool call และผลลัพธ์ที่ sub-agent ส่งกลับ ส่วน system prompt และ context ของ sub-agent อยู่ใน context window ที่แยกออกไปต่างหาก
ข้อดีที่ Daisy ระบุในคลิปคือ sub-agent ทำงานแบบ parallelism ได้ และเหมาะกับงานที่ต้องอ่านไฟล์ 50 ไฟล์เพื่อสรุปกลับมาให้ main loop โดยไม่ต้องเอาเนื้อหา 50 ไฟล์เข้า main context ตรงๆ
จุดอ่อนที่เหมือนกับ skill คือ description 1 บรรทัดของ sub-agent ทุกตัวต้องอยู่ใน parent system prompt เพื่อให้ Claude รู้ว่าจะเรียก sub-agent ตัวไหนได้บ้าง ถ้ามี sub-agent 100,000 ตัว ค่า tax ของ description รวมก็เริ่มหนัก ทีม Anthropic กำลังทดลองวิธีลดส่วนนี้อยู่เช่นกัน
4.5 สรุปการเปรียบเทียบและสิ่งที่ทีม Anthropic ตัดสินใจไม่ทำ
ตามที่ Daisy นำเสนอ ลำดับการ scale จากแย่ไปดีคือ MCP, Skills/Sub-agents, Hooks ตามลำดับ หลักคิดที่ฝากไว้คือให้เลือก abstraction ที่ scale ได้ ไม่ใช่ตัวที่ flexible ที่สุดในตอนนี้
อีกประเด็นที่ Daisy พูดในคลิปคือ คำขอที่ทีมได้รับบ่อยที่สุดสำหรับ plugin คือ "ทำไมไม่ให้ plugin มี CLAUDE.md เป็นของตัวเอง" คำตอบของทีมคือไม่อนุญาต เพราะมันเป็น abstraction ที่แพงมากแต่ดูเหมือนถูก ถ้าเปิดให้ทำได้ plugin ทุกตัวก็จะใส่ CLAUDE.md เข้ามาในระบบ ขณะที่ user มักเปิดใช้ plugin หลายตัวพร้อมกัน ผลคือ plugin ทั้งหมดจะทำให้ system prompt ของ user บวมขึ้นโดยอัตโนมัติ ทางออกที่ทีมจัดให้คือใช้ session-start hook ส่ง text เข้า context เพื่อให้เห็นชัดว่า user กำลังจ่าย token เพิ่ม ไม่ใช่แอบกินพื้นที่เงียบๆ
ส่วน Memory ที่นักพัฒนาบางคนเข้าใจว่าเทียบเท่ากับ plugin Daisy ชี้ในคลิปว่ามันอยู่คนละ category กัน Memory เหมาะกับข้อมูลคุณภาพปานกลาง อายุสั้น และสร้างโดย agent ระหว่างทำงาน ขณะที่ plugin คือ context engineering primitive ที่ออกแบบ ทดสอบ และเลือกใช้อย่างจงใจ ทั้งสองอย่างมีที่ของตัวเอง แต่ไม่ใช่ตัวเลือกที่ใช้แทนกันได้
5. Working Style ใหม่ที่ Anthropic ใช้พัฒนา Claude ด้วย Claude
ในช่วงท้ายของ talk Daisy เล่าถึง working style ใหม่ที่ทีม Claude Code ใช้พัฒนา Claude เองด้วย Claude โดยมีคีย์เวิร์ดหลัก 2 คำคือ asynchrony (ทำงานแบบ async แล้วเดินออกไป) และ parallelism (รันหลาย agent พร้อมกัน) ผลที่ตามมาคือนักพัฒนาต้องเก่งเรื่อง context switching อย่างหลีกเลี่ยงไม่ได้
5.1 Git worktree กับ agent อายุยาว
Daisy เริ่มจาก primitive ที่เก่าที่สุดคือ git worktree หรือการ check out repo เดียวกันเป็นหลาย folder บนเครื่องเดียว โดยแต่ละ folder ใช้ branch ของตัวเอง เมื่อวาง Claude Code 1 instance ต่อ 1 worktree แต่ละ instance จึงทำงานในพื้นที่แยกกัน ไม่เหยียบกันเอง เหมือนยุคที่นักพัฒนาคนเดียวยังมี checkout หลายชุดเพื่อทำงานหลายเรื่องพร้อมกัน
ตามที่ Daisy นำเสนอ worktree แบบ long-lived ที่ track upstream main ของ monorepo ไว้ตลอดจะช่วยลดเวลา bootstrap ของ project ใหม่ เช่น npm install, cargo init, การวาง symlink เพราะ worktree พร้อมใช้งานอยู่แล้ว ส่วน setup จริงในเครื่องของ Daisy คือมี worktree ระยะยาวสำหรับ Anthropic monorepo 2 ตัว และอีกชุดสำหรับ Claude Code repo ที่ตอนนี้แยกออกจาก monorepo เพราะ monorepo engineering ระดับนั้นยากเกินไป
ในคลิป Daisy แชร์เทคนิคเล็กๆ ที่ช่วย context switching ได้จริง คือการตั้งชื่อ session ของ Claude Code แต่ละตัวและเปลี่ยนสี (color) ของ session สีเป็น trigger ของความจำที่มีประสิทธิภาพมาก เห็นสีปุ๊บสมองก็รู้ทันทีว่ากำลังทำเรื่องอะไร คล้าย syntax highlighting สำหรับมนุษย์ในยุค agentic ส่วนการตั้งชื่อช่วยให้นักพัฒนาที่ตาบอดสีแยก session ได้ง่ายขึ้น
5.2 send_message: Claude คุยกับ Claude ได้
ทีม Anthropic เปิด feature send_message ตั้งแต่ต้นปี 2026 และกำลังขยายให้ Claude ตัวหนึ่งสามารถส่งข้อความหา Claude ตัวอื่นในบัญชีเดียวกันได้ (ภายใต้การอนุญาตของ user) ใช้กรณีหลักคือเมื่อ Claude ตัวหนึ่งกำลังทำงานบางอย่าง แล้วต้องการให้ Claude อีกตัวอธิบาย context หรือผลลัพธ์ของงานก่อนหน้าให้ฟัง
Daisy ยกในคลิปว่ามุมมองที่ถูกของเรื่องนี้คือ Claude ตัวอื่นก็คืออีก "ที่ทำงาน" ที่ Claude ตัวปัจจุบันต้องเข้าถึงได้ เพราะการตัดสินใจส่วนหนึ่งเกิดในบทสนทนาของ Claude อีก instance ถ้าตัวที่กำลังทำงานเข้าไม่ถึงข้อมูลนั้น ก็อาจตัดสินใจผิดทิศได้ง่ายๆ นี่คือการขยายหลัก Access ของ section 2.1 ให้ครอบคลุม Claude ตัวอื่นด้วย
5.3 /loop: cron tool ที่รัน prompt ซ้ำตามเวลา
/loop คือ slash command ที่ภายในเรียก tool ชื่อ cron tool ทำหน้าที่รัน prompt ใดๆ ตามช่วงเวลาที่กำหนด เช่น ทุก 10 นาที โดย Claude จะรู้จักปิด loop เองเมื่อ prompt ไม่เกี่ยวข้องอีกต่อไป
ในคลิป Daisy ยก use case ที่นิยมที่สุดของ /loop คือการ babysit PR หลังจาก push โดยให้ Claude เช็ค CI ทุก 10 นาที ถ้า CI ตกก็แก้แล้ว push ใหม่ ถ้า CI ผ่านก็แจ้งกลับ ผลคือนักพัฒนาสามารถทิ้ง CI ที่ใช้เวลานานเป็นชั่วโมงให้ทำงานข้ามคืน แล้วเช้าวันถัดมาก็ได้ branch ที่ CI green พร้อม merge
5.4 Auto permissions mode: ปลอดภัยพอจะใช้กับ overnight work
Auto permissions mode คือโหมดสิทธิ์ที่ไม่ใช่ dangerous skip permissions แต่เป็นโหมดที่มี classifier agent คอยจัดประเภท tool call และมี adversarial agent อีกตัวคอย double-check ว่า tool call นั้นไม่ก่ออันตรายก่อนอนุญาต Daisy ระบุในคลิปว่าโหมดนี้คือสิ่งที่ทำให้ /loop, agent team และ overnight work ใช้งานได้จริง เพราะถ้ายังต้องมี permission prompt ทุกครั้ง ก็ไม่มีทาง async ได้
ค่าใช้จ่ายที่ Auto mode เพิ่มขึ้นอยู่ที่ราว 30-40% เพราะกินเพิ่มจาก agent ตรวจสอบ (Daisy ระบุในคลิปว่าตัวเองไม่แน่ใจตัวเลขแน่นอน และทีมกำลังลดตัวเลขนี้ลง) แต่สิ่งที่แลกได้คือ workflow ที่เปลี่ยนจากการนั่งเฝ้าเป็นการเดินออกไปแล้วกลับมาดูผล
5.5 Claude Agents view: UI สำหรับดู agent ทุกตัวพร้อมกัน
Claude Agents view คือหน้า UI ที่เพิ่งเปิดตัวสำหรับดู Claude agent ทุกตัวที่กำลังรันอยู่ มี classifier ตัวเล็กๆ คอยย้าย agent ไปกลุ่มต่างๆ ตามสถานะ เช่น กำลังทำงาน, ติดอยู่, รอ input นักพัฒนาสามารถส่ง prompt ไปหา agent ตัวใดก็ได้จากหน้านี้ กระโดดเข้า session ของแต่ละตัวได้ทันที หรือจะเริ่ม session ใหม่ก็ได้
Daisy เล่าในคลิปว่าวิศวกรที่สร้าง view นี้ใช้ view ของตัวเองในการ merge PR ราว 1,000 ตัวในช่วงเดือนเดียว นี่คือตัวอย่างของ workflow "Claude พัฒนา Claude" ที่ทีมกำลังเจอเองในงานจริง
5.6 Remote Control: kick off Claude จากนอก terminal
Remote Control คือฟีเจอร์ที่แสดง state ของ agent บนมือถือและบน Claude Code desktop ตามที่ Daisy นำเสนอ use case คลาสสิกคือการ check-in 30 วินาทีหลังมื้อค่ำก่อนนอน เพื่อตรวจว่า agent overnight ติดประเด็นง่ายๆ บางอย่างหรือเปล่า ถ้าติดก็ปลดล็อกผ่านมือถือ ถ้าไม่ติดก็ปล่อยให้ทำงานต่อ
6. 3 ข้อที่ต้องจำ และเหตุผลที่หลักคิดเดียวอ่านงานทั้งหมดได้
ก่อนปิด talk Daisy สรุป take-home 3 ข้อให้ผู้ฟังจำกลับบ้าน เป็นบทสรุปสั้นๆ ที่ใช้มองงานทั้งหมดของ Daisy ได้
Give it access คือต้องให้ agent เข้าถึงทุกที่ที่การตัดสินใจของทีมเกิดขึ้นจริง ไม่ว่าจะเป็น Slack, design document, dashboard, CI หรือแม้แต่ meeting note หลักนี้เชื่อมกลับไปที่หมวด Access ใน section 2.1 และเป็นพื้นฐานที่ตัดสินว่า agent จะทำงานเป็น "เพื่อนร่วมงาน" ได้จริงหรือไม่
Mind the box คือต้องระวัง context window ซึ่งเป็นกล่องที่จำกัดและไม่ได้ขยายตัวเร็วเท่าที่หลายคนคิด Daisy เปิดเผยในคลิปว่าวลี Mind the box นี้ Claude เป็นคนคิด ไม่ใช่ Daisy ทุก customization ที่ใส่เข้าไปคือการลงทุนใน context window จึงต้องเลือกลงทุนกับ abstraction ที่ scale ได้
Pick abstractions that scale คือเมื่อต้องเลือกระหว่าง MCP, Skills, Hooks และ Sub-agents ให้คิดเสมอว่าถ้ามี primitive นั้น 100,000 ตัวใน monorepo ระบบจะรอดหรือไม่ Hook คือ abstraction เดียวที่เป็น zero-overhead จริง ส่วน Skills และ Sub-agents scale ได้ดีในระดับ progressive disclosure ขณะที่ MCP เหมาะกับ public integration ที่ user ไม่มี shell
บทสรุปสำหรับนักพัฒนาไทยที่ใช้ Claude Code อยู่แล้ว
สิ่งที่ talk นี้ฝากไว้สำหรับนักพัฒนาไทยที่กำลังใช้ Claude Code ในงานจริง คือให้เปลี่ยนวิธีคิดจากการใช้ Claude เป็นเครื่องมือเขียนโค้ดอัจฉริยะ ไปสู่การออกแบบ agentic harness ของตัวเอง หลักคิด 3 เสา Access, Knowledge, Tooling ใช้ประเมินได้ทันทีว่า harness ปัจจุบันของทีมขาดอะไรอยู่ ส่วนตารางเปรียบเทียบ 4 plug-in primitives จะช่วยตัดสินใจว่า primitive ไหนเหมาะกับปัญหาที่ต้องแก้
Tip: ลองทำงาน 1 วันโดยไม่ออกจาก Claude Code terminal แล้วจดทุกครั้งที่ต้อง alt-tab ไปเครื่องมืออื่น จากนั้นเอารายการนั้นมาออกแบบ skill หรือ hook ในตอนเย็น นี่คือ exercise ที่ Daisy แนะนำไว้ในคลิปว่าให้ผลเร็วกว่าที่คาด
เนื้อหานี้สรุปจากคลิป Beyond the basics with Claude Code โดย Daisy Holman วิศวกรทีม Claude Code ที่ Anthropic เผยแพร่บนช่อง Claude (Anthropic official) ความยาว 47 นาที 19 วินาที ขอแนะนำให้รับชมต้นฉบับเต็มเพื่อดูภาพประกอบและรายละเอียดที่อาจไม่ได้สรุปไว้ในบทความนี้
ที่มา: Beyond the basics with Claude Code (Daisy Holman, Claude, Anthropic official)



