บทเรียนจากการสร้าง Claude Code: prompt caching คือทุกอย่างของ agent
Thariq Shihipar จากทีม Claude Code ของ Anthropic เปิดเผยว่า cache read มีราคา 0.1 เท่าของ input ปกติ ซึ่งหมายความว่า cached prompt จ่ายเพียง 10% ของราคาเดิมทุกครั้งที่เรียก บทความนี้สรุปกฎ 7 ข้อที่ทีม Claude Code ใช้ออกแบบ harness ทั้งระบบรอบ prompt caching รวมถึง Plan Mode และ compaction fork ที่นักพัฒนา agent บน Claude API ส่วนใหญ่ยังเข้าใจผิด.

ในการสร้าง agent บน Claude API ตัวแปรเดียวที่ลดทั้ง cost และ latency ได้มากที่สุดไม่ใช่การเลือกโมเดลที่ถูกลง แต่คือ prompt cache hit rate. ประเด็นนี้ถูกเปิดเผยโดย Thariq Shihipar ซึ่งเป็น Member of Technical Staff ในทีม Claude Code ที่ Anthropic ผ่านบทความ Lessons from Building Claude Code: Prompt Caching Is Everything ที่เผยแพร่เมื่อเดือนเมษายน 2026 และ teaser บน X ที่ @trq212. Thariq เล่าว่า harness ทั้งระบบของ Claude Code ถูกออกแบบรอบ prompt caching ตั้งแต่วันแรก โดยตัวเลขที่ทำให้กฎข้อนี้เด็ดขาดคือ cache read มีราคาเพียง 0.1 เท่าของ base input ซึ่งหมายความว่าทุกครั้งที่ cached prompt ถูกใช้ซ้ำ จ่ายแค่ 10% ของราคาเรียกครั้งแรก ส่วน cache miss คือการจ่าย 100% ใหม่ทั้งก้อน. นักพัฒนาที่ build agent โดยไม่รู้กลไกข้อนี้กำลังจ่ายเงินส่วนต่าง 10 เท่าอยู่ทุกการเรียก API โดยไม่รู้ตัว.

ทำไม prompt caching ถึงเป็น "ทุกอย่าง" ของ agent ตามที่ Thariq ระบุ
Thariq เปิดบทความด้วยประโยคว่า long running agentic product อย่าง Claude Code เกิดขึ้นได้เพราะ prompt caching เพราะช่วยนำ computation จาก roundtrip ก่อนหน้ามาใช้ซ้ำ ลดได้ทั้ง latency และ cost อย่างชัดเจน. จุดที่สำคัญกว่าคือทีม Claude Code ปฏิบัติกับ cache hit rate จริงจังมาก: ทีมตั้ง alert ผูกกับ cache hit rate และประกาศ SEV ทันทีเมื่อค่าตก เหมือน monitor uptime ของ production service. Thariq ระบุชัดว่า cache miss rate ที่เพิ่มขึ้นเพียงไม่กี่เปอร์เซ็นต์ก็ส่งผลต่อ cost และ latency แล้ว สะท้อนว่าผู้สร้าง Claude API เองถือกฎข้อนี้เป็น production SLO ระดับเดียวกับ p99 latency.
สำหรับนักพัฒนาที่ build agent บน Claude API ในงาน production จริง ประเด็นนี้หมายความว่า cache hit rate ไม่ใช่ optimization ระดับ "nice to have" ที่ค่อยทำทีหลังได้ แต่เป็น constraint เชิงสถาปัตยกรรมที่ต้องตั้งไว้ตั้งแต่ก่อนเขียนโค้ดบรรทัดแรก. ทีม Claude Code เจอกรณีที่ "ดูสมเหตุสมผล" แต่กลับทำลาย cache มาแล้วหลายครั้ง บทเรียน 7 ข้อต่อไปนี้จึงเป็น post-mortem ที่ Thariq สรุปไว้ในบทความของ Anthropic.
กฎข้อที่ 1: เรียง prompt ให้ static มาก่อน dynamic เสมอ
prompt caching ใน Claude API ทำงานด้วยกลไก prefix matching หมายความว่าระบบจะ cache ทุกอย่างตั้งแต่จุดเริ่มของ request ไปจนถึง cache_control breakpoint แต่ละจุด. ลำดับของ content จึงสำคัญมาก เพราะเป้าหมายคือทำให้ request ของแต่ละ session แชร์ prefix ร่วมกันให้ได้มากที่สุด.
Thariq อธิบายว่า Claude Code จัดเรียง prompt ทั้งหมดเป็น 4 layer แนวตั้ง โดยวาง static content ไว้ด้านบน และ dynamic content ไว้ด้านล่าง:
- Static system prompt + Tools — globally cached ทุก session
- CLAUDE.md — cached per project
- Session context — cached per session
- Conversation messages — uncached ขยายทุก turn
ลำดับนี้ทำให้ session จำนวนมากจาก user คนละคนยังแชร์ cache hit ของ layer 1 ได้ ซึ่งเป็นชั้นที่ใหญ่ที่สุด.
[ layer 1 — Static System Prompt + Tools ] ← cache_control breakpoint #1
[ layer 2 — CLAUDE.md ] ← cache_control breakpoint #2
[ layer 3 — Session context ] ← cache_control breakpoint #3
[ layer 4 — Conversation messages ] ← dynamic, ไม่ใส่ breakpointClaude API กำหนดเพดานไว้ที่ 4 cache_control breakpoints ต่อ request จึงต้อง design ลำดับ prefix อย่างจงใจ ไม่ใช่ใส่ breakpoint สะเปะสะปะ.
Thariq เตือนว่า structure นี้เปราะบางกว่าที่คิด ทีม Claude Code เคยทำลาย ordering นี้ด้วยเหตุผลที่ดูไม่อันตราย เช่น:
- การใส่ timestamp ละเอียดใน static system prompt ซึ่งเปลี่ยนทุกวินาที
- การ shuffle ลำดับ tool definition แบบ non-deterministic ระหว่าง deploy
- การ อัปเดต parameter ของ tool ระหว่าง session เช่น เปลี่ยน list ของ subagent ที่ Agent tool เรียกได้
ทั้งสามกรณีนี้เปลี่ยน byte ใน prefix แม้เพียงไม่กี่ตัว ทำให้ prefix hash ไม่ตรงและ cache miss ทั้งสาย.
กฎข้อที่ 2: ส่ง update ผ่าน message ห้ามแก้ที่ system prompt
ในหลายกรณี ข้อมูลใน prompt ต้องอัปเดต เช่น เวลาปัจจุบัน หรือผู้ใช้แก้ไฟล์บางไฟล์ระหว่าง session. วิธีที่ดู intuitive คือแก้ system prompt ให้ตรงกับสถานะปัจจุบัน แต่นี่คือกับดักที่ Thariq เตือนชัด เพราะการแก้ system prompt แม้แต่ token เดียวจะทำลาย prefix และทำให้ request หลังจากนั้นกลายเป็น cache miss ทั้งหมด.
Thariq เสนอ pattern ที่ Claude Code ใช้แทน คือส่งข้อมูลใหม่ผ่าน message ใน turn ถัดไป ของ agent โดยใส่ tag <system-reminder> ใน user message หรือ tool result ของ turn ถัดไป. วิธีนี้ทำให้ static system prompt ไม่เปลี่ยน, prefix ยังตรง, cache ยังใช้ได้ และโมเดลก็ได้รับ context ใหม่ตามที่ต้องการ. สำหรับนักพัฒนาที่ build agent บน Claude API กฎข้อนี้ปรับใช้ได้ทันที: เก็บ system prompt ให้เป็น immutable แล้วส่งทุกการเปลี่ยนแปลงผ่าน message channel เท่านั้น.
กฎข้อที่ 3: ห้ามสลับ model กลาง session
prompt cache ของ Claude API ผูกกับโมเดลแต่ละตัวแยกกัน ทำให้คณิตศาสตร์ของ cost ตอนสลับ model สวนทางกับสามัญสำนึก. Thariq ยกตัวอย่างที่ชัดที่สุด: ถ้า conversation วิ่งกับ Opus มาแล้ว 100,000 token แล้วต้องถามคำถามง่าย ๆ การเปลี่ยนไปใช้ Haiku จะ แพงกว่า การให้ Opus ตอบต่อ เพราะ Haiku ต้อง rebuild cache ใหม่ทั้งก้อนตั้งแต่ token แรก.
ทางออกที่ Thariq เสนอเมื่อจำเป็นต้องใช้โมเดลคนละตัวจริง ๆ คือใช้ subagent โดย agent หลัก (เช่น Opus) เตรียม "hand-off message" แล้วส่งงานต่อให้ subagent อีกตัวที่ใช้โมเดลคนละชนิด. Thariq ยกตัวอย่างว่า Claude Code ใช้ pattern นี้บ่อยกับ Explore agent ซึ่งเป็น subagent ที่รัน Haiku สำหรับงานสำรวจ codebase ที่ไม่ต้องการความสามารถระดับ Opus. โครงนี้ทำให้ cache prefix ของ session หลักไม่ถูกแตะ ส่วน Haiku ก็ทำงานของตัวเองในบริบทใหม่.
กฎข้อที่ 4: ห้าม add หรือ remove tool กลาง session
Thariq ระบุว่าการเปลี่ยน tool set กลาง conversation เป็น 1 ใน "วิธีพังที่เจอบ่อยที่สุด" ของการ break prompt cache. เหตุผลคือ tool definition เป็นส่วนหนึ่งของ cached prefix ดังนั้นการเพิ่มหรือลด tool แม้แต่ตัวเดียวก็ทำให้ prefix hash เปลี่ยน และ invalidate cache ของ conversation ทั้งสายตั้งแต่จุดนั้นเป็นต้นไป.
วิธีที่ดู intuitive คือ "ให้เฉพาะ tool ที่ agent น่าจะใช้ตอนนี้" เพื่อให้ context สะอาดและประหยัด token. Thariq ชี้ว่า intuition นี้สวนทางกับวิธีที่ cache ทำงาน เพราะการลด tool ลงเพียง 1 ตัวเท่ากับต้องจ่ายค่า input เต็มของ conversation ทั้งสายในครั้งถัดไป. ทางออกของ Thariq สำหรับโจทย์นี้อยู่ในกฎข้อที่ 5 และ 6: "ใช้ tool ทำ state transition" แทน "การสลับ tool set".
กฎข้อที่ 5: Plan Mode = วิศวกรรมรอบ cache constraint
Plan Mode ของ Claude Code เป็นกรณีศึกษาที่ Thariq ใช้แสดงหลักการ design feature รอบ caching constraint ได้ชัดที่สุด. โจทย์คือเมื่อผู้ใช้ toggle เข้า Plan Mode (สำรวจ codebase ได้ แต่ห้ามแก้ไฟล์) ทีม dev ส่วนใหญ่จะคิดถึงทางแก้แบบ intuitive: ตัด Edit Write Bash tool ออกจาก request เพื่อบังคับ behavior แบบ read-only. แต่ tool list อยู่ใน cached prefix การตัด tool ออกจึง break cache ทั้งสาย.
วิธีที่ Claude Code ใช้จริงคือเก็บ tool ครบทุกตัวใน request ตลอด session แล้วเพิ่ม EnterPlanMode และ ExitPlanMode เข้าไปเป็น tool ปกติอีกสองตัว. การ toggle Plan Mode เกิดขึ้นผ่าน system message ใน turn ถัดไป เพื่อบอกโมเดลว่ากำลังอยู่ใน Plan Mode พร้อม instruction ให้สำรวจ codebase, ห้ามแก้ไฟล์ และเรียก ExitPlanMode เมื่อ plan เสร็จ. ผลคือ tool definition ไม่เปลี่ยน, prefix ยังตรง, cache ยังคงอยู่ ส่วน behavior ที่ต้องการ enforce ด้วย instruction ใน message ไม่ใช่ด้วย tool list.
Engineering principle ที่ Thariq สรุปจากกรณีนี้คือ:
Use tools to model state transitions, not tool-set swaps.
แทนที่จะใช้ "การมี/ไม่มี tool" เป็น state ของระบบ ให้ใช้ "tool ที่ถูกเรียก" เป็น state transition. หลักการนี้ปรับใช้ได้กับทุก agent ไม่ใช่เฉพาะ Plan Mode เช่น read-only mode, dry-run mode, sandbox mode สามารถ implement เป็น EnterXMode / ExitXMode tool ได้ทั้งหมด. Bonus insight ที่ Thariq เสริมคือ เนื่องจาก EnterPlanMode เป็น tool ปกติ โมเดลจึง เรียกเองได้ เมื่อเจอปัญหายาก เช่น ก่อนแก้งานครั้งใหญ่ โมเดลอาจตัดสินใจเข้า Plan Mode เพื่อสำรวจก่อน โดยไม่ต้องรอผู้ใช้ toggle.
กฎข้อที่ 6: ใช้ tool search + defer_loading แทนการลด tool
โจทย์ถัดมาที่ Thariq เล่าคือกรณีที่ agent ต้องรองรับ tool จำนวนมาก เช่น MCP server ที่มี tool หลายสิบตัว. ถ้าใส่ schema เต็มของทุกตัวในทุก request ค่าใช้จ่ายจะแพงมหาศาล แต่การตัด tool ออกระหว่างทางก็ break cache ตามกฎข้อที่ 4 ทำให้ทางออกที่ดูชัดเจนทั้งสองทางใช้ไม่ได้.
Thariq เสนอกลไก defer_loading: true ซึ่งส่ง stub ของ tool (เฉพาะชื่อ tool โดยไม่มี full schema) ใน request ทุกครั้ง และเรียงในลำดับเดิมเสมอ. โมเดลจะ "discover" tool ผ่าน tool search tool เมื่อจำเป็น และ full schema จะโหลดเฉพาะตอนที่โมเดลตัดสินใจเลือกใช้ tool นั้นจริง. โครงนี้ทำให้ cached prefix คงที่ เพราะ stub ชุดเดิมอยู่ในลำดับเดิมตลอด ส่วน cost ของการโหลด schema เต็มเกิดเฉพาะกับ tool ที่ถูกเลือกใช้จริงเท่านั้น. Thariq ระบุว่า tool search tool ใช้ผ่าน API ได้โดยตรง ไม่ต้อง implement กลไกค้นหา tool เองตั้งแต่ต้น.
กฎข้อที่ 7: compaction ต้อง fork จาก parent prefix ให้ตรงเป๊ะ
เมื่อ context window เต็ม Claude Code ต้อง summarize บทสนทนาเก่าให้สั้นลงเพื่อทำงานต่อ กระบวนการนี้เรียกว่า compaction. Thariq เน้นว่ากรณีนี้คือ cost trap ที่นักพัฒนาส่วนใหญ่เจอ เพราะวิธีที่ดู intuitive ที่สุดคือเปิด API call แยกสำหรับ summarize โดยใช้ system prompt ใหม่ที่บอกว่า "summarize this" และไม่ใส่ tool เลย:
POST /messages
system: "Summarize this conversation."
tools: []
messages: [...conversation ทั้งหมด...]ปัญหาคือ cache ทำงานด้วย prefix match แบบ byte for byte ตั้งแต่ token แรก. main conversation ถูก cache ภายใต้ system prompt และ tool set ชุดหนึ่ง แต่ summarization call ใช้ system prompt คนละชุดและไม่มี tool ทำให้ prefix แตกต่างจาก parent ตั้งแต่ byte แรก. ผลคือ cache ไม่ apply เลยแม้แต่ token เดียว และต้องจ่ายราคา input เต็มของ conversation ทั้งสาย ยิ่ง conversation ยาว (= ยิ่งต้องการ compaction) ค่าเรียกครั้งนั้นยิ่งแพงมหาศาล.
วิธีที่ Claude Code ใช้จริงคือ fork จาก parent prefix โดย Thariq อธิบายโครงสร้างของ cache-safe compaction ไว้แบบนี้:
POST /messages
system: <ชุดเดิมของ parent — byte for byte>
tools: <ชุดเดิมของ parent — byte for byte>
messages: [
...conversation เดิมของ parent ทั้งหมด,
{ role: "user", content: "<compaction prompt>" } // append ตัวสุดท้าย
]จากมุมของ API request หน้าตาของ call นี้เกือบเหมือน request สุดท้ายของ parent conversation ทุกอย่าง: prefix เดียวกัน, tool ชุดเดียวกัน, history เดียวกัน. cache ของ parent จึง reuse ได้เต็ม ส่วน token ใหม่มีแค่ compaction prompt ที่ append เข้าไปท้ายสุดเท่านั้น. Thariq เพิ่มเติมว่าวิธีนี้บังคับให้ต้องสำรอง compaction buffer ไว้ใน context window ให้เพียงพอสำหรับใส่ compaction prompt และ output summary token. หลักการที่ Thariq สรุปแบบทั่วไปกว่านี้คือ:
Fork operations need to share the parent's prefix.
หลักการเดียวกันใช้ได้กับทุก side computation ที่ต้องเปิด API call แยกจาก main conversation ไม่ว่าจะเป็น summarization, skill execution หรือ sub-task delegation. Thariq ระบุปิดท้ายว่า Anthropic implement กฎข้อนี้เป็น compaction API อย่างเป็นทางการแล้ว เพื่อให้นักพัฒนาที่ build agent ทั่วไปไม่ต้องเขียน fork logic เองตั้งแต่ต้น.
ตัวเลข cost ที่ทำให้กฎเหล่านี้คุ้มค่าทุกครั้ง
ตัวเลขที่ทำให้ทุกกฎข้างต้นมีน้ำหนักคือ multiplier ของ Claude API ที่ระบุไว้ใน Anthropic API prompt caching reference:
| รายการ | ตัวคูณของ base input |
|---|---|
| Base input (uncached) | 1.00× |
| Cache write 5 นาที | 1.25× |
| Cache write 1 ชั่วโมง | 2.00× |
| Cache read | 0.10× |
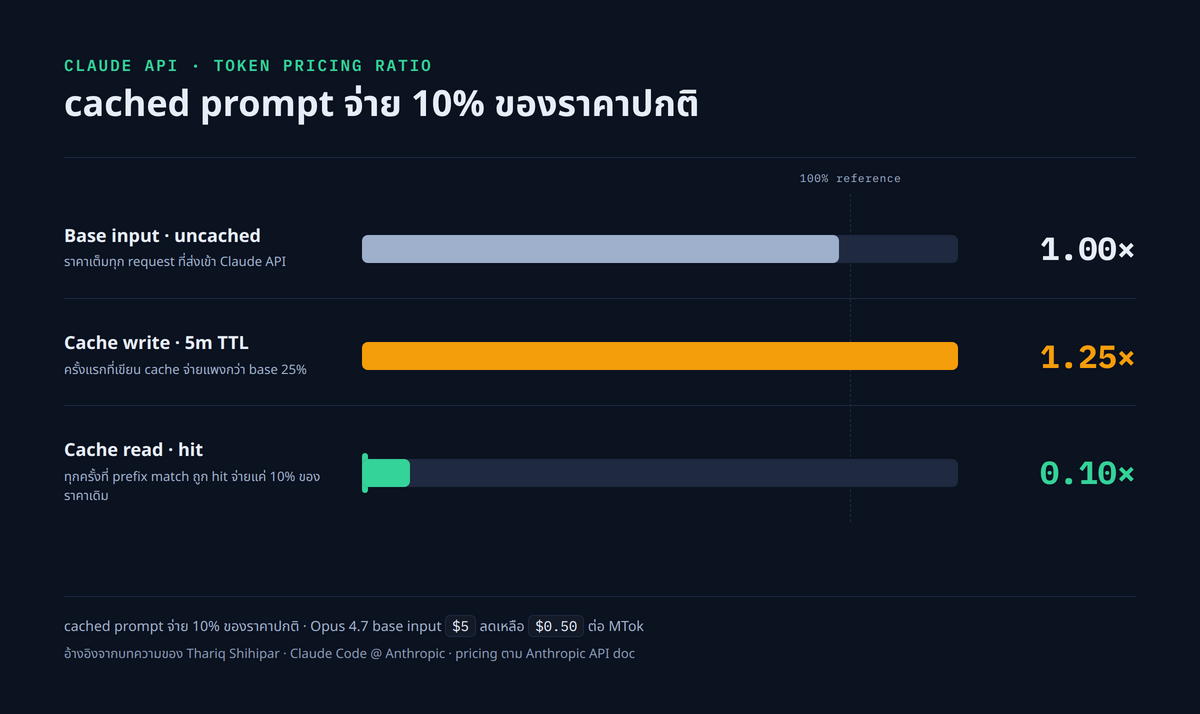
แปลเป็นตัวเลขจริงของ Claude Opus 4.7 ราคา base input คือ 5 ดอลลาร์ต่อล้าน token ส่วน cache hit อยู่ที่ 0.50 ดอลลาร์ต่อล้าน token เท่ากับส่วนต่าง 10 เท่าต่อการเรียก. TTL ของ cache อยู่ที่ 5 นาทีโดย default และเลือกขยายเป็น 1 ชั่วโมงได้เมื่อ session ยาว แต่ต้องจ่ายฝั่ง write เพิ่มจาก 1.25× เป็น 2× ส่วนฝั่ง read ยังคงที่ 0.1×.
ส่วน threshold ของ token ขั้นต่ำที่ cache ได้คือ 4,096 token สำหรับ Opus (4.7 / 4.6 / 4.5) และ Haiku 4.5 ส่วน Sonnet (4.6 / 4.5) อยู่ที่ 1,024 token. ถ้า prompt สั้นกว่านี้ ทั้ง cache_creation_input_tokens และ cache_read_input_tokens จะกลับมาเป็น 0 หมายความว่า cache ไม่เกิดเลย. Claude API ยังกำหนด cache_control breakpoint ได้สูงสุด 4 จุดต่อ request บังคับให้นักพัฒนาวาง prefix อย่างจงใจ ไม่ใช่ใส่ breakpoint ทั่วทุกที่. การ track cache ทำผ่าน field สามตัวใน response.usage คือ cache_creation_input_tokens cache_read_input_tokens และ input_tokens ซึ่งทีม Claude Code ใช้คำนวณ cache hit rate สำหรับเปิด alert.
Tip: ก่อน deploy agent ใน production ลองเขียน metric pipeline ที่ดึงสาม field นี้จาก
response.usageทุก request แล้วคำนวณ hit rate ต่อ session. ถ้า hit rate ตกต่ำกว่าค่าปกติของระบบ ให้ trigger alert เหมือนที่ทีม Claude Code ทำ เพราะ Thariq อธิบายว่าทีมประกาศ SEV และ treat เป็น incident ทุกครั้ง.
สรุป: 4 บทเรียนที่นักพัฒนาไทยนำไปใช้ได้ทันที
บทความของ Thariq ปิดด้วย 5 lesson หลักของทีม Claude Code สรุปเป็นข้อปฏิบัติสำหรับนักพัฒนาไทยที่ build agent บน Claude API ได้ดังนี้:
- ตั้ง prefix match เป็น constraint ข้อแรกของ design เรียง prompt ให้ static อยู่บนและ dynamic อยู่ล่าง วาง
cache_controlbreakpoint อย่างจงใจไม่เกิน 4 จุด และห้ามให้ timestamp หรือ tool order เปลี่ยน prefix ระหว่าง request - อัปเดต state ผ่าน message channel เท่านั้น ใช้
<system-reminder>pattern หรือ tool result เพื่อส่งข้อมูลใหม่ ห้ามแก้ system prompt ทุกกรณี - อย่าสลับ model หรือ tool set กลาง session ถ้าต้องการสลับ model ให้ใช้ subagent ทำ hand-off. ถ้าต้องการเปลี่ยน behavior ให้ใช้ tool ทำ state transition (
EnterPlanMode/ExitPlanModepattern). ถ้ามี tool เยอะ ให้ใช้defer_loadingไม่ใช่ลบ tool - fork operation ต้อง share prefix กับ parent ให้ตรง byte ต่อ byte ไม่ว่าจะเป็น compaction summarization หรือ side computation อื่น และต้อง monitor cache hit rate ในระดับเดียวกับ uptime
ทุกข้อข้างต้นเป็น engineering practice ที่ Thariq Shihipar จากทีม Claude Code ที่ Anthropic เปิดเผยใน Lessons from Building Claude Code: Prompt Caching Is Everything ซึ่ง teaser ต้นทางอยู่ที่ X post ของ Thariq เอง @trq212. ตัวเลข cost multiplier ทั้งหมดอ้างอิงจาก Anthropic API prompt caching reference ซึ่งเป็น spec อย่างเป็นทางการที่บทความของ Thariq ชี้ไป.
ที่มา: Lessons from Building Claude Code: Prompt Caching Is Everything โดย Thariq Shihipar (Anthropic), X post ของ Thariq @trq212, Anthropic API — Prompt caching reference



