Claude Opus 4.8 มาแล้ว: ราคาเท่าเดิม เก่งขึ้นเกือบทั้งกระดาน ปุ่มปรับ effort ใช้ได้ทุกแผน
Anthropic ประกาศ Claude Opus 4.8 เมื่อวันที่ 28 พฤษภาคม 2026 โดยคงราคาเท่าเดิมที่ $5/$25 ต่อล้าน token แต่ทำคะแนน benchmark สูงขึ้นเกือบทุกแถว เด่นสุดคือ SWE-Bench Pro 69.2% พร้อมของใหม่ 3 อย่าง ปุ่มปรับ effort ที่ใช้ได้ทุกแผน, dynamic workflows ใน Claude Code และ fast mode ที่ถูกลง 3 เท่า ขณะที่จุดเด่นที่ลึกที่สุดคือ "ความซื่อสัตย์" ปล่อย bug หลุดน้อยลงราว 4 เท่า

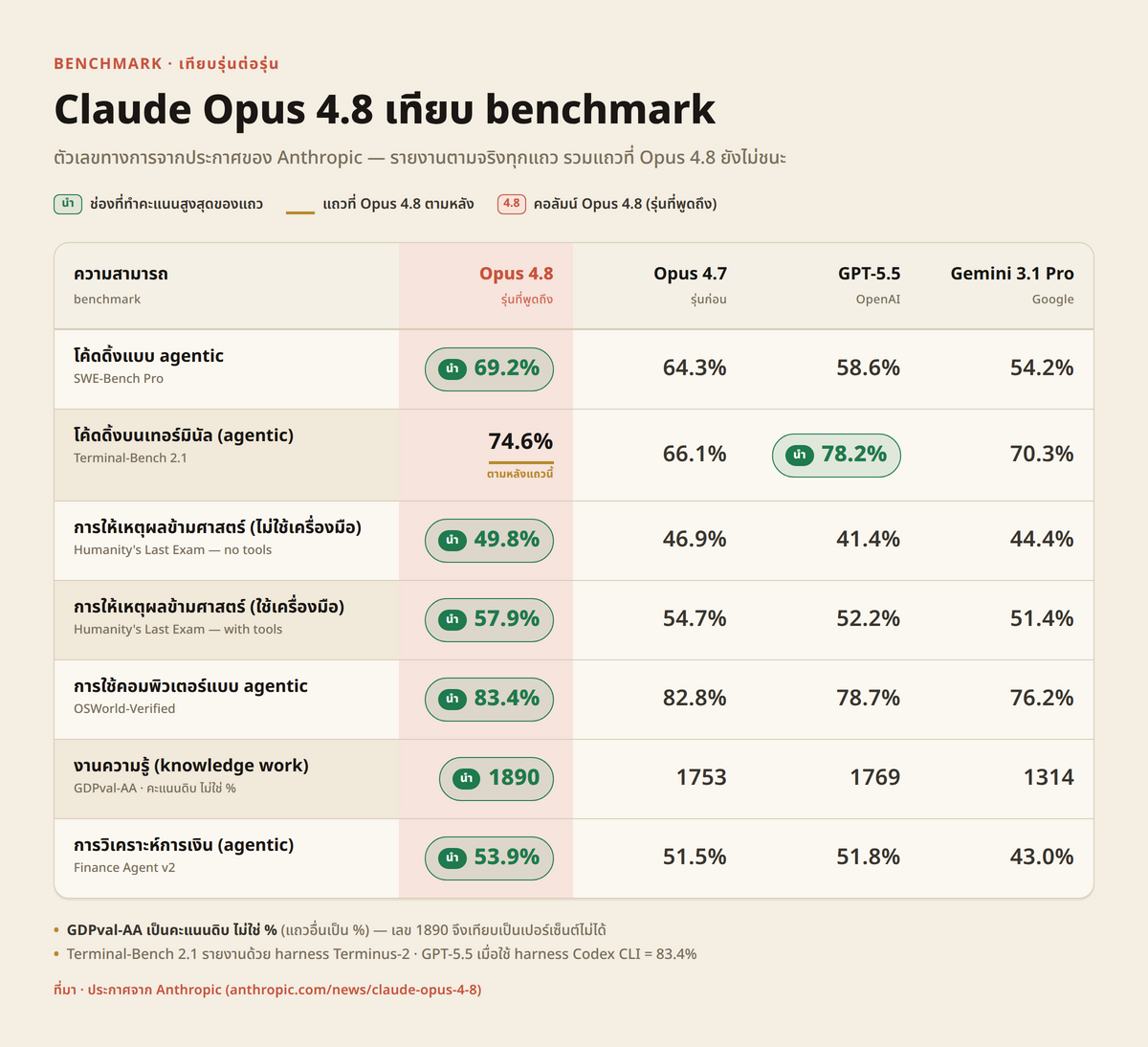
Anthropic ประกาศเปิดตัว Claude Opus 4.8 เมื่อวันที่ 28 พฤษภาคม 2026 เป็นการอัปเกรดต่อยอดจาก Opus 4.7 จุดที่น่าสนใจที่สุดคือ โมเดลรุ่นใหม่ทำคะแนนดีขึ้นเกือบทั้งกระดาน แต่ยังคงราคาเท่าเดิม Anthropic ระบุว่า Opus 4.8 "ดีขึ้นทั่วทั้ง benchmark และเป็นผู้ช่วย (collaborator) ที่มีประสิทธิภาพมากขึ้น" พร้อมเรียกการอัปเกรดครั้งนี้ว่า "ไม่หวือหวาแต่จับต้องได้ (modest but tangible)" สะท้อนว่าเป็นการพัฒนาแบบ incremental ที่เน้นผลใช้งานจริง ไม่ใช่การโหมโรงเรื่องตัวเลขเพียงอย่างเดียว
นอกจากเรื่อง benchmark แล้ว Anthropic เปิดเผยว่าการเปิดตัวครั้งนี้มาพร้อมของใหม่ 3 อย่างที่ผู้ใช้ได้สัมผัสจริง ได้แก่ ปุ่มควบคุมระดับ effort (ระดับความพยายามที่โมเดลทุ่มให้กับงาน) บน claude.ai, ฟีเจอร์ dynamic workflows ใน Claude Code สำหรับงานสเกลใหญ่ และ fast mode ที่เร็วขึ้น 2.5 เท่าในราคาที่ถูกลงกว่ารุ่นก่อน ส่วนธีมที่ลึกที่สุดของรุ่นนี้ไม่ใช่ความเร็วหรือคะแนน แต่เป็นเรื่อง "ความซื่อสัตย์ (honesty)" ของโมเดลที่ Anthropic ให้ความสำคัญเป็นพิเศษ
1. เก่งขึ้นแค่ไหน และจุดที่ยังไม่ชนะ
ตามตาราง benchmark ในประกาศของ Anthropic, Opus 4.8 ทำคะแนนนำเกือบทุกแถวเมื่อเทียบกับ Opus 4.7, GPT-5.5 และ Gemini 3.1 Pro ตัวเลขที่เด่นที่สุดอยู่ที่งานเขียนโค้ดเชิง agent (ตัวช่วยอัตโนมัติ) ซึ่งวัดด้วย SWE-Bench Pro โดย Opus 4.8 ทำได้ 69.2% ขยับขึ้นจาก 64.3% ของ Opus 4.7 และทิ้งห่าง GPT-5.5 ที่ 58.6% รวมถึง Gemini 3.1 Pro ที่ 54.2% ส่วนงานใช้คอมพิวเตอร์แบบ agent ที่วัดด้วย OSWorld-Verified ทำได้ 83.4% ขยับขึ้นเล็กน้อยจาก Opus 4.7
ด้านการให้เหตุผลข้ามศาสตร์ที่วัดด้วย Humanity's Last Exam, Anthropic เปิดเผยว่า Opus 4.8 ทำได้ 49.8% เมื่อไม่ใช้ tool (เครื่องมือที่โมเดลเรียกใช้) และขยับขึ้นเป็น 57.9% เมื่อใช้ tool ส่วนงานความรู้ทั่วไปที่วัดด้วย GDPval-AA ทำได้ 1890 คะแนน (เป็นคะแนนดิบ ไม่ใช่เปอร์เซ็นต์) สูงกว่าทั้ง Opus 4.7, GPT-5.5 และ Gemini 3.1 Pro ในแถวเดียวกัน ขณะที่งานวิเคราะห์การเงินเชิง agent ที่วัดด้วย Finance Agent v2 ทำได้ 53.9%
Note: จุดที่ Opus 4.8 ยังไม่ชนะคืองานเขียนโค้ดผ่าน terminal ที่วัดด้วย Terminal-Bench 2.1 Anthropic ระบุว่า GPT-5.5 ทำได้ 78.2% นำหน้า Opus 4.8 ที่ 74.6% โดยตัวเลขทุกโมเดลในแถวนี้รายงานด้วย harness สาธารณะชื่อ Terminus-2 ขณะที่ footnote ของตารางยังระบุเพิ่มว่า ถ้า GPT-5.5 ใช้ harness ชื่อ Codex CLI จะทำได้ถึง 83.4%
การที่ Anthropic รายงานจุดที่ตัวเองไม่ชนะไว้ในตารางอย่างเปิดเผย ทำให้ตัวเลขชุดนี้น่าเชื่อถือมากขึ้น เพราะไม่ได้เลือกเทียบเฉพาะแถวที่ได้เปรียบ ในประกาศยังระบุว่ารายละเอียดของชุด eval (การวัดผล) ที่กว้างกว่านี้อยู่ในเอกสาร Claude Opus 4.8 System Card
2. ของใหม่ 3 อย่างที่มาพร้อมกัน
นอกจากตัวโมเดลที่เก่งขึ้นแล้ว Anthropic เปิดเผยว่าการเปิดตัวครั้งนี้มีของใหม่ 3 อย่างที่ผู้ใช้ใช้ได้ทันที อย่างแรกคือ effort control ซึ่งเป็น control ใหม่ข้างตัวเลือกโมเดลบน claude.ai และ Cowork ให้ผู้ใช้เลือกได้ว่าจะให้ Claude ทุ่ม effort กับคำตอบมากแค่ไหน Anthropic ระบุว่า effort สูงทำให้โมเดลคิดบ่อยขึ้นและลึกขึ้นเพื่อคำตอบที่ดีขึ้น ส่วน effort ต่ำทำให้ตอบเร็วขึ้นและใช้ rate limit ช้าลง จุดสำคัญสำหรับผู้ใช้ทั่วไปคือ ฟีเจอร์นี้ใช้ได้ทุกแผน ไม่จำกัดเฉพาะแผนระดับสูง
ของใหม่อย่างที่สองคือ dynamic workflows ใน Claude Code ซึ่งในประกาศระบุว่ายังอยู่ในสถานะ research preview ฟีเจอร์นี้ทำให้ Claude วางแผนงานเอง รัน subagents (ตัวช่วยย่อย) ขนานกันได้หลายร้อยตัวใน session เดียว แล้วตรวจสอบผลลัพธ์ของตัวเองก่อนรายงานกลับมาให้ผู้ใช้ Anthropic ยกตัวอย่างว่า Claude Code ที่รันบน Opus 4.8 ทำงาน migration ระดับ codebase ข้ามโค้ดหลายแสนบรรทัดได้ตั้งแต่เริ่มงานจนถึงขั้น merge โดยใช้ชุดเทสต์ที่มีอยู่เดิมเป็นเกณฑ์วัด ปัจจุบัน dynamic workflows ใช้ได้ใน Claude Code สำหรับแผน Enterprise, Team และ Max
ของใหม่อย่างที่สามเป็นของฝั่งนักพัฒนา โดย Messages API รองรับ "system entries" ใน array ของ messages ได้แล้ว ทำให้นักพัฒนาอัปเดตคำสั่ง (instructions) ของ Claude ระหว่างที่งานกำลังรันได้ โดยไม่ทำให้ prompt cache พัง และไม่ต้องส่งคำสั่งผ่าน user turn Anthropic ระบุว่าความสามารถนี้ใช้ปรับ permissions, token budgets หรือ environment context ระหว่างที่ agent กำลังทำงานอยู่ได้
3. ปุ่มปรับ effort ทำงานอย่างไร และควรเลือกระดับไหน
เรื่อง effort เป็นจุดที่ Anthropic อธิบายไว้ละเอียดเป็นพิเศษในประกาศ โดยระบุว่า Opus 4.8 ตั้งค่าเริ่มต้นไว้ที่ระดับ high effort ซึ่ง Anthropic ประเมินว่าเป็นสมดุลที่ดีที่สุดระหว่างคุณภาพของคำตอบกับประสบการณ์การใช้งาน จุดที่น่าสนใจคือ บนงานเขียนโค้ด ระดับ high effort ใช้ token ใกล้เคียงกับค่า default เดิมของ Opus 4.7 แต่ให้ผลงานที่ดีกว่า หมายความว่าผู้ใช้ได้คุณภาพสูงขึ้นโดยไม่ต้องจ่าย token เพิ่มในระดับเดียวกัน
สำหรับงานที่ยากขึ้น Anthropic เปิดเผยว่าผู้ใช้เลือกระดับ "extra" (ใน Claude Code เรียกว่า "xhigh") หรือ "max" ได้ โดยโมเดลจะใช้ token มากขึ้นเพื่อแลกกับผลลัพธ์ที่ดีขึ้น ในประกาศแนะนำให้ใช้ระดับ "extra" สำหรับงานยากและ workflow แบบ asynchronous ที่รันยาว นอกจากนี้ Anthropic ยังเพิ่ม rate limits ใน Claude Code เพื่อรองรับการใช้ token ที่มากขึ้นจาก effort ระดับสูง ทำให้ผู้ใช้ที่ต้องการเร่งคุณภาพไม่ติดเพดานเร็วเกินไป
4. ความซื่อสัตย์ของโมเดล จุดเด่นที่อาจถูกมองข้าม
แม้ตัวเลข benchmark จะเป็นพระเอกของหน้าประกาศ แต่ Anthropic ให้น้ำหนักกับเรื่อง "honesty" หรือความซื่อสัตย์ของโมเดลไว้ค่อนข้างมาก Anthropic ระบุว่า ปัญหาที่พบบ่อยของโมเดล AI คือบางครั้งโมเดลรีบสรุป (jump to conclusions) และอ้างอย่างมั่นใจว่างานคืบหน้าแล้วทั้งที่หลักฐานยังบาง ทีมจึงเทรนทุกโมเดลให้หลีกเลี่ยงการกล่าวอ้างสิ่งที่สนับสนุนไม่ได้ ทำให้ Opus 4.8 มีแนวโน้มที่จะ flag ความไม่แน่ใจเกี่ยวกับงานของตัวเองมากขึ้น และอ้างสิ่งที่ไม่มีหลักฐานน้อยลง
ตัวเลขที่ Anthropic ยกมาประกอบเรื่องนี้คือ ในการประเมิน Opus 4.8 มีโอกาสปล่อยให้ข้อบกพร่องในโค้ดที่มันเขียนเองหลุดผ่านไปโดยไม่ทักท้วงน้อยลงราว 4 เท่าเมื่อเทียบกับรุ่นก่อนหน้า สำหรับงานจริงของนักพัฒนาและนักวิเคราะห์ การที่โมเดลยอมบอกว่า "ไม่แน่ใจ" หรือทักท้วงเมื่อพบจุดผิดปกติ มีค่ามากกว่าโมเดลที่มั่นใจแต่ผิด เพราะช่วยลดงานรีวิวและลดความเสี่ยงที่จะปล่อย bug หลุดไปถึงขั้นใช้งานจริง
ด้าน alignment (การปรับโมเดลให้สอดคล้องกับเจตนาที่ปลอดภัย) Anthropic เปิดเผยว่าทีม Alignment ประเมินอย่างละเอียดก่อนปล่อยโมเดล และสรุปว่า Opus 4.8 ทำสถิติใหม่ในด้านคุณลักษณะเชิงสังคม (prosocial traits) เช่น การสนับสนุนอิสระในการตัดสินใจของผู้ใช้และการกระทำเพื่อประโยชน์สูงสุดของผู้ใช้ ขณะที่อัตราพฤติกรรมที่ misaligned เช่น การหลอกลวงหรือร่วมมือกับการใช้ในทางที่ผิด อยู่ต่ำกว่า Opus 4.7 อย่างมีนัยสำคัญ และใกล้เคียงกับ Claude Mythos Preview โมเดลที่ aligned ดีที่สุดของ Anthropic รายงานฉบับเต็มอยู่ใน Claude Opus 4.8 System Card
5. ราคา วิธีใช้ และทิศทางถัดไป
ด้านราคาและการใช้งาน Anthropic ระบุว่า Claude Opus 4.8 ใช้ได้ทุกที่แล้วตั้งแต่วันเปิดตัว โดยราคาการใช้งานปกติเท่าเดิมกับ Opus 4.7 ที่ $5 ต่อล้าน input token และ $25 ต่อล้าน output token ส่วนนักพัฒนาเรียกใช้ผ่าน Claude API ด้วย model id claude-opus-4-8 หมายความว่าผู้ที่ใช้รุ่นก่อนอยู่แล้วเปลี่ยนมาใช้รุ่นใหม่ได้โดยไม่มีต้นทุนเพิ่ม
จุดที่น่าสนใจสำหรับงานที่ต้องการความเร็วคือ fast mode ของ Opus 4.8 โดยในประกาศระบุว่าทำงานเร็วขึ้น 2.5 เท่า และตอนนี้ถูกลง 3 เท่าเมื่อเทียบกับโมเดลรุ่นก่อน ราคา fast mode อยู่ที่ $10 ต่อล้าน input token และ $50 ต่อล้าน output token ทำให้งานที่ผู้ใช้ต้องรอคำตอบแบบทันที เช่น chat หรือ agent ที่ต้องตอบสนองเร็ว มีต้นทุนที่จับต้องได้มากกว่าเดิม
สำหรับทิศทางถัดไป Anthropic เปิดเผยว่ากำลังพัฒนาโมเดลที่ให้ความสามารถระดับ Opus หลายอย่างในต้นทุนที่ถูกลง พร้อมแผนปล่อยโมเดล "คลาสใหม่" ที่ฉลาดกว่า Opus นอกจากนี้ในประกาศยังกล่าวถึง Project Glasswing ซึ่งมีองค์กรจำนวนน้อยกำลังใช้ Claude Mythos Preview สำหรับงาน cybersecurity โมเดลระดับนี้ต้องมี cyber safeguards ที่แข็งแรงกว่าก่อนปล่อยใช้ทั่วไป Anthropic ระบุว่าความคืบหน้าเป็นไปอย่างรวดเร็ว และคาดว่าจะนำโมเดลคลาส Mythos มาสู่ลูกค้าทุกคนได้ "ในอีกไม่กี่สัปดาห์ข้างหน้า"
โดยสรุป สิ่งที่ผู้ใช้คนไทยได้ทันทีจากการอัปเกรดครั้งนี้คือ ปุ่มปรับ effort ที่ใช้ได้ทุกแผน ทำให้คุมงบการใช้ AI ได้ด้วยตัวเอง, ราคา API ที่เท่าเดิมแต่ของดีขึ้น, fast mode ที่ถูกลง 3 เท่าสำหรับงานที่ต้องการความไว และโมเดลที่ปล่อย bug หลุดน้อยลงราว 4 เท่า จึงช่วยลดภาระงานรีวิวของทีมพัฒนาได้จริง



