The Thinking Lever: คันโยกควบคุมความคิดของ Claude สรุปจาก talk ของ Alexander Bricken (Anthropic)
Alexander Bricken จากทีม Applied AI Research ของ Anthropic อธิบายว่าทำไม thinking toggle แบบเปิด/ปิดถึงเป็น proxy ที่แย่ของ effort และ Claude ใช้ test-time compute อย่างไรผ่าน 2 คันโยกหลักคือ effort level (low ถึง max) กับ budget พร้อม decision matrix ที่ dev ไทยนำไปใช้ตัดสินใจระดับ task ได้ทันที

วิดีโอ "The thinking lever" ที่ Alexander Bricken จากทีม Applied AI Research ของ Anthropic บรรยายในงาน Anthropic Developer Conference ใช้เวลา 21 นาที อธิบายเรื่องที่ dev ส่วนใหญ่เข้าใจผิดมาตั้งแต่ยุค reasoning model รุ่นแรก: การมอง "thinking" เป็นปุ่ม toggle เปิด/ปิดที่ทำให้คำตอบดีขึ้น Bricken ชี้ว่า จริง ๆ แล้ว thinking คือ capability ตัวหนึ่งของ Claude คู่กับ tool calling และ text ไม่ใช่สวิตช์ การปิด thinking toggle จึงเท่ากับตัด capability ทั้งก้อนทิ้งโดยไม่จำเป็น คลิปนี้ Anthropic วาง 2 คันโยกสำหรับ user คือ effort level (low, medium, high, extra-high, max) กับ budget (max tokens, task budgets) พร้อม decision matrix ที่ระบุชัดว่า extra-high คือ default ของ Claude Code และ claude.ai เพราะเป็น Pareto-efficient ส่วน max ใช้ได้ก็ต่อเมื่อรู้แน่ ๆ ว่า task นั้นยากจริง บทความนี้สรุปประเด็นทั้งหมดที่ Bricken อธิบายในคลิป และเรียบเรียงใหม่ตามลำดับการอ่านของ dev ไทย พร้อมตัวอย่าง task ที่ dev ไทยเจอประจำเพื่อ map กลับเข้า effort level ที่ใช้จริง
1. Test-time compute คืออะไร และทำไมจึงเป็นแกนของ reasoning model
Bricken เปิด talk ด้วยการย้อนพัฒนาการของ LLM ในช่วงสองสามปีที่ผ่านมา จุดเปลี่ยนสำคัญคือ reasoning model ซึ่งใช้ test-time compute หมายถึงการให้ model ใช้ token เพิ่มในช่วง inference time เพื่อคิดก่อนตอบ ทำให้คำตอบแม่นยำขึ้น ในเชิงทฤษฎี การ scale performance ทำได้ 2 แกน แกนแรกคือ train-time compute หรือการเพิ่มขนาด parameter ของ model ส่วนแกนที่สองคือ test-time compute หรือการให้ model ใช้ token มากขึ้นตอนตอบ
ใน benchmark ภายในของ Anthropic Bricken แสดงให้เห็นว่ากราฟทั้ง 2 แกนนี้ขนานกัน เมื่อ model ใหญ่ขึ้นจาก Haiku ไป Sonnet ไป Opus คะแนนใน internal agentic coding benchmark ก็ขยับขึ้นจนเกือบ 80% อีกด้านหนึ่ง ถ้าให้ Claude ใช้ token มากขึ้น (แกน x แบบ logarithmic) performance ก็สูงขึ้นในลักษณะเดียวกัน Bricken ย้ำว่ากราฟทั้งสองสะท้อนคะแนนเดียวกัน นั่นคือ test-time compute scale ได้คล้ายกับ train-time compute
Claude: The thinking lever by Alexander Bricken สาธิตว่าผลแบบนี้เป็นจริงในทุก knowledge domain ไม่ว่าจะเป็น GPQA ซึ่งเป็น reasoning benchmark, OS World ที่วัด computer use หรือ Humanity's Last Exam ซึ่งเป็นชุดข้อสอบระดับ PhD ทั้งหมดนี้ Claude ที่ใช้ token มากขึ้นเพื่อคิดก่อนตอบ ให้ผลลัพธ์ที่ดีขึ้นทุก benchmark
2. 3 รูปแบบของ test-time compute: thinking, tool calling, text
Bricken แยก test-time compute ออกเป็น 3 แบบหลัก เพื่อให้เห็นภาพว่า token ที่ Claude ใช้ในช่วง inference time ถูกใช้ไปกับอะไรบ้าง
แบบแรกคือ thinking space for reasoning เป็น scratch pad ที่ Claude ใช้พิจารณาคำถาม ดูข้อมูลใน prompt และวางแผนขั้นถัดไปก่อนตอบจริง
แบบที่สองคือ tool calling เป็น interface ระหว่าง Claude กับโลกภายนอก ตัวอย่างที่ Bricken ยกในคลิปคือการสั่ง Claude ทำ web search เพื่อหาข้อมูล Anthropic Developer Conference แต่จริง ๆ แล้ว tool คือทุกอย่างที่ทำได้ผ่าน function call ไม่ว่าจะเป็น Salesforce, MCP server, การเขียนไฟล์ลง file system หรืออะไรก็ตามที่ user เปิดสิทธิ์ให้ Claude เรียก
แบบที่สามคือ text คือ output สุดท้ายที่ Claude ตอบกลับ user อาจเป็นสรุปงานทั้งหมดที่ทำ หรือเป็นคำถามขอข้อมูลเพิ่มก่อนเริ่มลงมือ
Bricken ชี้ว่า test-time compute ทั้ง 3 แบบมีต้นทุนตรงในรูป token count และเวลาที่ใช้ ทำให้ user อยากมี lever ที่ควบคุมได้เองว่า task ไหนควรใช้ compute เท่าไหร่
3. 2 คันโยกสำหรับควบคุม: effort level กับ budget
ตามที่ Bricken นำเสนอ Anthropic ออกแบบ 2 คันโยกหลักเพื่อให้ user คุม test-time compute ได้ตรงตามที่ task ต้องการ
คันแรกคือ effort level มี 5 ระดับคือ low, medium, high, extra-high และ max ยิ่งกำหนด effort สูง model ก็จะใช้เวลาคิดนานขึ้นและใช้ token มากขึ้นตามลำดับ Bricken เน้นว่าคำถามที่ user จะเจอประจำคือ "จะ trade intelligence แลกกับ speed ในจุดไหน"
คันที่สองคือ budget ซึ่งเป็นการกำหนด constraint แบบ strict กว่า มี 2 รูปแบบหลักคือ max token constraint และ task budget ที่เป็น feature ใน Anthropic API การใช้ budget เหมาะกับ use case ที่ต้องการเพดานชัดเจน เช่น งานยาวที่ปล่อยให้ agent ทำเองและไม่อยากให้ใช้ compute เกินงบที่ตั้งไว้
ในคลิป Bricken บอกตรง ๆ ว่าทั้ง talk จะลงลึกเรื่อง effort เป็นหลัก เพราะเป็น lever ที่ใช้บ่อยกว่าและ map กับการตัดสินใจระดับ task ได้ตรง
Note: state ในอุดมคติของ Anthropic คือ user แค่ส่งคำถามและ Claude รู้เองว่าควรใช้ effort เท่าไหร่ แต่ Bricken ยอมรับว่าในทางปฏิบัติ มนุษย์ก็ยังอยากมี lever ที่ปรับเองได้อยู่ดี
4. การสาธิตจริง: simulation ที่ traffic light บน Opus 4.7
ส่วนที่ทรงพลังที่สุดของ talk คือการสาธิตด้วย prompt เดียวกัน "Create a realistic simulation of cars on a one-way street at a traffic light" รันบน Opus 4.7 ที่ effort 3 ระดับ เพื่อให้เห็นกับตาว่า token ที่เพิ่มขึ้นแปลเป็นคุณภาพที่ต่างกันแค่ไหน
ระดับแรก low effort ใช้เวลาราว 50 วินาที และ output ประมาณ 4,600 token ผลที่ได้เป็น simulation ที่ใช้ได้ มีถนน one-way จริง รถวิ่ง 2 lane หยุดที่ไฟแดงเป็นจังหวะ และปรับ spawn rate กับ cycle ของไฟได้ Bricken ประเมินว่า "ค่อนข้างดี" แต่ก็ "ค่อนข้าง simplistic"
ระดับที่สอง high effort ใช้เวลาราวสองเท่าและใช้ token ประมาณสองเท่าของ low simulation ที่ออกมามีรายละเอียดมากขึ้น มีรถหลายแบบ รวมถึง lorry และตำแหน่งของไฟจราจรเริ่มสมเหตุสมผลกว่า โดยอยู่เหนือถนนแทนที่จะอยู่กลางถนนแบบ low อีกจุดที่ Opus 4.7 รายงานเองคือการทำให้คนขับ "ฉลาดขึ้น" รถรอบ ๆ react ตามกันแทนการเดินอิสระแยกคัน
ระดับสุดท้าย max effort ใช้ token และเวลาราว 10 เท่าของ low simulation ที่ได้มีรายละเอียดมากที่สุด ไฟจราจรห้อยจากเสาตามฟิสิกส์จริง มีฉาก skyscape เป็น background และรถขับสะท้อน intelligent motion ที่ดีกว่ารอบก่อน ๆ
ประเด็นสำคัญที่ Bricken สรุปจากการสาธิตนี้คือ token ที่ใช้เพิ่มขึ้นแปลเป็นคุณภาพที่ดีขึ้นจริง แต่ความสัมพันธ์เป็น logarithmic ไม่ใช่ linear การกระโดดจาก extra-high ไป max ใช้ token เพิ่มเป็นสองเท่า แต่ได้คุณภาพที่ดีขึ้นแบบ marginal เท่านั้น

5. ทำไม "thinking toggle" ถึงเป็น proxy ที่แย่ของ effort
จุดที่ Bricken ใช้เวลาอธิบายมากที่สุดในคลิปคือเหตุผลว่าทำไม mental model แบบ "เปิดหรือปิด thinking" จึงผิด มุมมองเดิมที่ผู้ใช้ส่วนใหญ่มีคือ thinking toggle เป็น dial สำหรับบอกว่าอยากได้คำตอบที่ดีกว่าหรือเร็วกว่า Bricken ยอมรับว่าเป็น instinct ที่เข้าใจได้
แต่ปัญหาในเชิง model คือ thinking toggle ไม่ได้แสดงเจตนาว่าอยากให้ Claude คิดหนักแค่ไหน มันแค่ปิด capability ตัวหนึ่งของ Claude ลงเท่านั้น เมื่อปิด extended thinking ผู้ใช้ก็ตัด tool ตัวหนึ่งจาก 3 capability หลัก (thinking, tool calling, text) ออกจาก context window ของ Claude ทั้งที่ task บางอย่างอาจต้องการ thinking เป็นช่วง ๆ ไม่ใช่ทั้งหมดหรือไม่เลย
ในคลิป Bricken เปรียบเทียบกับ tool use ตรง ๆ ว่า "เราไม่ได้บอก Claude ว่าห้าม web search ตลอด หรือต้อง search ตลอด เราแค่ให้ search tool และให้ Claude ตัดสินใจเองว่าตอนไหนควร search" Bricken ชี้ว่า thinking ควรทำงานในกรอบเดียวกัน
อีก analogy ที่ Bricken ใช้คือการทำงานกับ teammate ในที่ทำงาน "ไม่มีใครบอกเพื่อนร่วมงานว่าห้ามใช้ inner monologue ตอนคิดงาน แค่บอก constraint ของ task แล้วให้เขาคิดเอง แล้วกลับมาคุยกัน" Bricken บอกว่า Anthropic อยากให้ Claude ทำงานในกรอบเดียวกัน
ด้วยเหตุนี้ Anthropic จึงพัฒนาจาก standard thinking ที่ Claude คิดทีเดียวจบก่อนเรียก tool ทั้งหมด ไปเป็น interleaved thinking ที่คิดได้หลังทุก tool call และล่าสุดเป็น adaptive thinking ที่ปล่อยให้ Claude เลือกเองว่าตอนไหนจะคิด ตอนไหนจะเรียก tool และตอนไหนจะตอบ text ตามลำดับใดก็ได้
Tip: Bricken เน้นว่า adaptive thinking ไม่ใช่ classifier ที่จัดประเภท request ก่อนเข้าทาง mode ใด mode หนึ่ง แต่เป็นการบอก Claude ว่ามี thinking tool ใช้เมื่อจำเป็น และ benchmark ทั้งหมดที่ Anthropic วัด run บน adaptive thinking ทั้งหมด พบว่า Pareto-efficient กว่า interleaved thinking ที่เป็นรูปแบบก่อนหน้า
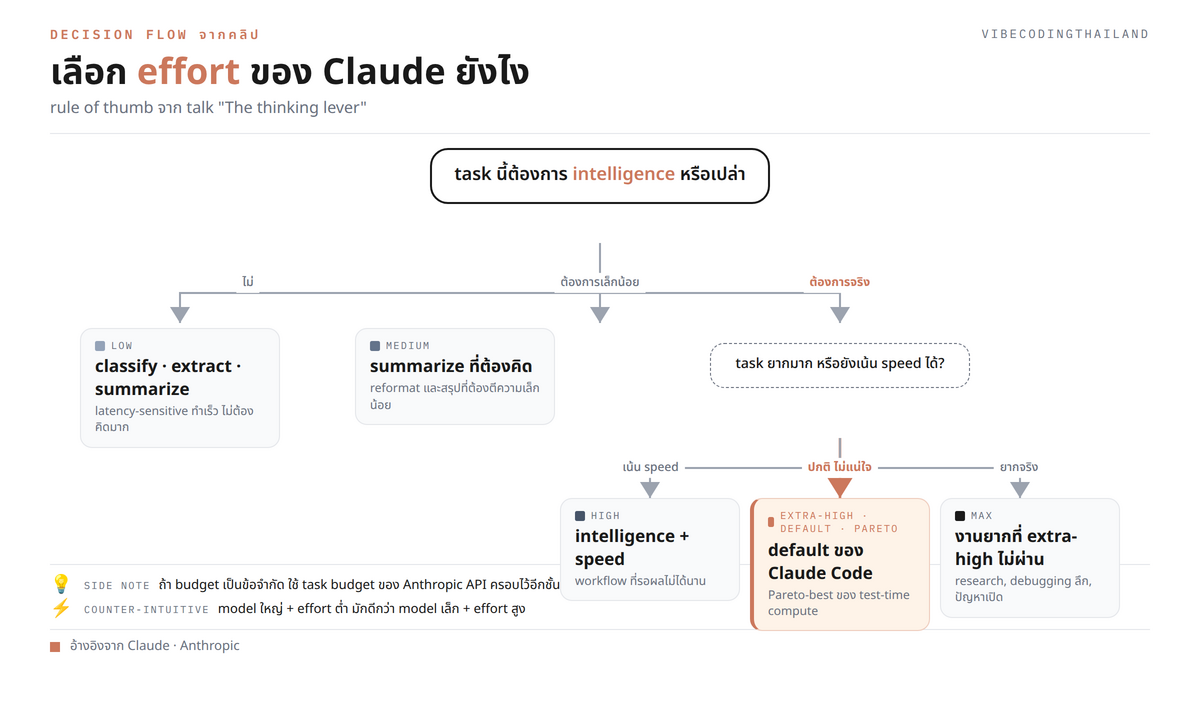
6. Decision matrix: เลือก effort level อย่างไรในแต่ละ task
Bricken ใช้ช่วงครึ่งหลังของ talk วาง decision matrix สำหรับการเลือก effort ซึ่งสรุปได้เป็น 5 ระดับ ตั้งแต่ max ไปจนถึง low
Max effort เหมาะกับ task ที่รู้แน่ ๆ ว่ายากและต้องการ intelligence สูงสุดเท่านั้น Bricken ไม่แนะนำให้เริ่มที่ระดับนี้ ยกเว้น use case ที่พิสูจน์แล้วว่าจำเป็น เพราะใช้ token เกือบสองเท่าของ extra-high แต่ได้ผลที่ดีขึ้นเพียง marginal
Extra-high เป็น default ที่ Anthropic ตั้งให้ทั้ง Claude Code และ claude.ai Bricken ยืนยันว่าเป็น trade-off ที่ดีที่สุดระหว่าง intelligence, speed และ token usage หรือเรียกได้ว่าเป็นจุด Pareto-efficient ของระบบ
High เหมาะกับ task ที่ต้องการ intelligence แต่ยังให้ความสำคัญกับ speed อยู่ Bricken แนะนำว่า "ถ้า use case ต้องการ intelligence ในระดับใดก็ตาม ควรลงเอยที่นี่"
Medium และ low ใช้กับ task ที่ latency-sensitive และไม่ใช่ intelligence-bound เช่น classification, summarization และ data extraction Bricken ยกตัวอย่างน่าสนใจของ low effort ที่กลายเป็นจุดแข็งโดยไม่คาดคิด นั่นคือ benchmark "Claude plays Pokémon" เมื่อจำกัด Claude ไว้ที่ low effort กลับใช้กลยุทธ์ "scapegoat the game" เช่น ใช้ repel หลีกเลี่ยง random encounter ใช้ potion เพื่อไม่ต้องกลับ Pokémon Center และวิ่งหนีศึกที่เจอตอนเดินใน grass ผลคือไปจบเกมได้เร็วกว่า effort สูง เพราะระบบบังคับให้คิดน้อยลงและหา unique attractor state ที่ effort สูงไม่เห็น
ในมุมของ dev ไทย Bricken เสนอ rule of thumb สำหรับช่วงเริ่มต้นที่ใช้ได้ทันที คือ "เมื่อไม่แน่ใจ เริ่มที่ extra-high" เพราะเป็น default ที่ Anthropic ใช้กับ product ของตัวเองอยู่แล้ว ส่วน task ที่เป็น latency-bound (classify, summarize, extract) ค่อยลด effort ลงตามจำเป็น
7. Model size vs effort: ขัด intuition ของ dev ส่วนใหญ่
อีกประเด็นที่ Bricken เน้นและขัดกับ intuition คือคำถามว่าควรเลือก model เล็กที่ effort สูง หรือ model ใหญ่ที่ effort ต่ำ เมื่อต้นทุนเท่ากัน
ในคลิป Bricken แสดง side-by-side ของ simulation prompt เดียวกัน รันบน Opus 4.7 กับ Haiku 4.5 พบว่า Haiku ใช้เวลาราวครึ่งหนึ่งของ Opus และใช้จำนวน token ใกล้เคียงกัน แต่ผลที่ได้ห่างกันชัด Bricken แสดงความเห็นตรง ๆ ในคลิปว่าภาพที่ Haiku ออกมาแทบดูไม่ออกด้วยซ้ำว่าเป็นรถ
ข้อสรุปที่ Bricken วางคือ ถ้า task ต้องการ intelligence ในระดับใดก็ตาม model ที่ใหญ่กว่ามักจะให้ผลที่ดีกว่า แม้จะตั้ง effort ไว้ที่ low ก็ตาม ส่วน model ขนาดเล็กควรใช้กับ use case ที่ผลลัพธ์ไม่ซับซ้อนมาก เช่น classification เรียบง่าย หรือ data extraction ที่ไม่ต้องคิดเชิง reasoning
แนวคิดที่ดีที่สุดตาม Bricken คือถ้ามีทรัพยากรพอ ให้รัน eval ให้ครอบทุก model (Haiku, Sonnet, Opus) และทุก effort level เพื่อหา balance ที่ดีที่สุดของ use case ตัวเอง แต่เมื่อไม่มี eval ที่สมบูรณ์ rule of thumb คือ "model ใหญ่ + effort ต่ำ" มักจะดีกว่า "model เล็ก + effort สูง"
8. Map กลับเข้า workflow ของ dev ไทย
เพื่อให้ rule ที่ Bricken อธิบายใช้งานได้จริง ตารางต่อไปนี้สรุปการ map effort level เข้ากับ task ที่ dev ไทยเจอประจำ โดยอ้างอิงจากแนวคิด Pareto-efficient ที่ Bricken วางไว้ในคลิป
- Refactor service ขนาดกลาง (เช่น Go service ที่มี 20 file) + debug race condition จริง → extra-high หรือ max เมื่อ pattern bug ซับซ้อนและทดสอบ reproduce ยาก ส่วน max ใช้ก็ต่อเมื่อ extra-high ทำให้ผ่านบาง iteration แล้วยังไม่จบ
- เขียน skill module / SOP ของบริษัทเป็นเอกสารยาว 2,000 คำขึ้นไป → high หรือ extra-high เพราะต้องการ intelligence ในการเรียบเรียง แต่ไม่ใช่ task ที่ตัดสินใจหนักเป็นหลัก
- Classify feedback comment ภาษาไทย 200 row ลง bucket → low หรือ medium เพราะ task แบบนี้ Bricken จัดอยู่ใน latency-sensitive อย่างชัดเจน
- Summarize meeting transcript 30 หน้า ให้ออกมาเป็น bullet 10 ข้อ → low หรือ medium ตาม decision matrix ส่วนของ Bricken ที่ระบุ "summarization" เป็น use case ของ low effort โดยตรง
- Extract field จากใบเสร็จที่ scan มา 100 ใบ ให้ลง schema JSON → low เพราะเป็น data extraction บริสุทธิ์
- Build agentic workflow ที่ทำงานเอง 1 สัปดาห์ + deploy ขึ้น production → extra-high หรือ max + budget cap (ใช้ task budget ของ Anthropic API กำหนด cost ceiling) เพื่อให้ Claude self-allocate ได้แต่ไม่ทะลุงบ
- Vibe-coding ทำต้นแบบเล่น ๆ ใน 30 นาที → extra-high ตาม default ของ Claude Code ที่ Bricken ระบุ ไม่ต้องคิดเพิ่ม
จุดที่ควรจำคือ rule ที่ Bricken เน้นว่า "ถ้า task ต้องการ intelligence ในระดับใดก็ตาม ควรลงเอยที่ high ขึ้นไป" และ "เมื่อไม่แน่ใจ เริ่มที่ extra-high" สอง rule นี้ครอบ workflow ส่วนใหญ่ของ dev ไทยได้แล้ว ส่วนการลด effort ลงควรทำเฉพาะเมื่อ benchmark ภายในของตัวเองยืนยันว่า task นี้ไม่ใช่ intelligence-bound จริง
9. End-state vision: ตั้ง bar/budget แล้วให้ Claude allocate เอง
จุดที่ Bricken ทิ้งท้ายและเป็นวิสัยทัศน์ของ Anthropic คือ ideal world ที่ user แค่กำหนด "bar" หรือ "budget" ของ task แล้วให้ Claude allocate compute เอง ตัวอย่างที่ Bricken ยกในคลิปคืองาน long-horizon ระดับวันหรือสัปดาห์ โดย user แค่บอกว่า "ทำงานนี้ภายใน 1 สัปดาห์" หรือ "ใช้เงินไม่เกินจำนวน X" จากนั้น Claude จะรู้เองว่าควรใช้ token เท่าไหร่กับแต่ละ subtask และส่งผลลัพธ์กลับมา
วิสัยทัศน์นี้สำคัญกับงาน agentic ที่กำลังโตเร็วในตลาด เพราะ task หลายอย่างที่ agent รับไปทำมีลักษณะ long-horizon และไม่สามารถวางแผนล่วงหน้าได้ละเอียดในทุก step ดังนั้นการให้ model แยกแยะเองว่า task ไหนสำคัญแค่ไหนและ allocate compute ให้เหมาะ จะเป็นทิศทางที่ Anthropic ผลักดันใน roadmap ต่อ ๆ ไป
ใน benchmark Bricken แสดง METR benchmark ที่ track ว่า Claude แต่ละ generation รับงาน human-level ได้นานแค่ไหนที่ระดับความแม่นยำ 50% โดย Mythos ซึ่งเป็น model ตัวล่าสุดของ Anthropic ทำได้ราว 16 ชั่วโมงของงานคน นี่คือผลของ train-time compute (model ใหญ่ขึ้น) บวก test-time compute (effort และ adaptive thinking ที่ดีขึ้น) ทั้งสองแกนรวมกัน
10. สรุป
talk ของ Alexander Bricken วาง mental model ใหม่ของการคุม Claude ที่ตรงข้ามกับสิ่งที่ผู้ใช้ส่วนใหญ่เคยเข้าใจ: thinking ไม่ใช่ toggle เปิด/ปิดที่ทำให้คำตอบดีขึ้น แต่เป็น capability ตัวหนึ่งคู่กับ tool calling และ text การปิด toggle จึงเท่ากับการตัด capability ทิ้ง ไม่ใช่การประหยัด token
สำหรับ user ที่อยากคุม test-time compute Anthropic วาง 2 lever คือ effort level (low ถึง max) กับ budget (max token, task budget) ในเชิงปฏิบัติ extra-high เป็น default ที่ Anthropic เลือกให้ Claude Code และ claude.ai แล้ว ส่วน max ควรใช้เฉพาะเมื่อรู้ชัดว่า task นั้นยากจริงและ extra-high ทำไม่ผ่าน สำหรับ low/medium ให้เก็บไว้ใช้กับ task ที่ latency-sensitive อย่าง classification, summarization และ extraction
rule ที่ Bricken เน้นและขัดกับ intuition คือ เมื่อ task ต้องการ intelligence แม้เพียงเล็กน้อย model ใหญ่ + effort ต่ำ มักจะดีกว่า model เล็ก + effort สูง และเมื่อไม่แน่ใจ การเริ่มที่ extra-high จะคุ้มที่สุดเสมอ
ในระยะยาว ทิศทางของ Anthropic คือให้ user กำหนดแค่ "bar" หรือ "budget" แล้ว Claude allocate compute เอง แนวทางนี้เป็นพัฒนาการต่อจาก adaptive thinking ที่ปัจจุบัน Claude ตัดสินใจได้เองแล้วว่าจะคิด เรียก tool หรือตอบ text ตามลำดับใดที่เหมาะกับ task
ที่มา: Claude: The thinking lever : Alexander Bricken (Anthropic Applied AI Research) (YouTube, 2026-05-20) ดูช่องเต็มของ Claude ที่ youtube.com/@claudeai ทุกประเด็นในบทความนี้สรุปจากเนื้อหาในคลิปดังกล่าวเท่านั้น



