Gemini Omni Flash: โมเดลวิดีโอใหม่ของ Google ที่อยู่ใน YouTube Shorts วันแรก ใช้ฟรีในไทยได้แล้ว

วันที่ 19 พฤษภาคม 2026 ในงาน Google I/O 2026 Google ประกาศ Gemini Omni โดยรุ่นแรกที่ปล่อยจริงคือ Gemini Omni Flash โมเดลวิดีโอแบบ multimodal ที่ออกแบบมาให้ "สร้างอะไรก็ได้จาก input อะไรก็ได้" จุดที่ทำให้การเปิดตัวครั้งนี้ต่างจากการเปิดโมเดลวิดีโอครั้งก่อน ๆ ของ Google ไม่ใช่แค่ตัวโมเดล แต่เป็นการปล่อยพร้อมกันบนแอป Gemini และ YouTube Shorts ตั้งแต่วันแรก ทำให้คนทั่วไปที่ใช้ YouTube อยู่แล้วเข้าถึงได้โดยไม่ต้องสมัครแพลนใด ๆ ตามที่ระบุใน ประกาศของ Google DeepMind
ข่าวจาก TechCrunch ระบุว่า Gemini Omni Flash รับ input ครบ 4 modality (text, image, audio, video) ในหนึ่ง prompt และ generate วิดีโอความยาว 10 วินาทีออกมาเป็นไฟล์เดียวพร้อมเสียงในตัว จุดที่เด่นที่สุดของ Omni เมื่อเทียบกับโมเดลคู่แข่งไม่ใช่ความยาวหรือ resolution เพราะ Sora 2 Pro ของ OpenAI ทำได้ยาวกว่า (25 วินาที) ตามที่ Metapress สรุปไว้ แต่เป็น multimodal input combo การแก้ต่อแบบ chat ที่จำตัวละครกับฉากเดิมได้ และการปล่อยฟรีบนช่องทาง consumer ตั้งแต่ day-one
ทุกคลิปที่ออกจาก Omni ติด watermark ของ SynthID ฝังในไฟล์แบบมองไม่เห็นด้วยตา และมี visible watermark ที่มุมล่างของเฟรม ตามรายงาน TechTimes Google ระบุว่าฐานข้อมูล SynthID มีไฟล์ที่ทำเครื่องหมายไว้แล้วเกิน 100,000 ล้านไฟล์ ส่วน feature ที่ Google ตั้งใจถือไว้ก่อนคือการแก้คำพูดหรือใส่เสียงคนอื่นลงในคลิปที่ generate ออกมา การตัดสินใจนี้ส่งผลโดยตรงต่อความปลอดภัยของครีเอเตอร์ในไทย
บทความนี้สรุปสิ่งที่ Gemini Omni Flash ทำได้จริงตามการสาธิตของ Paul J Lipsky และ Robby Payne จาก Chrome Unboxed เปรียบเทียบกับ Sora 2, Veo 3 และ Kling แล้วประเมินว่าครีเอเตอร์ นักการตลาด ครู และนักพัฒนาในไทยควรหยิบอะไรไปใช้กับงานจริงทันที และอะไรยังไม่ควรเชื่อเกินกว่าที่โมเดลทำได้จริง
Bottom line ที่ใหม่จริงสำหรับโมเดลวิดีโอตัวนี้
สิ่งที่ใหม่จริงในการประกาศครั้งนี้ไม่ใช่ตัวเลขความยาวหรือคุณภาพภาพ เพราะคู่แข่งทำได้ใกล้เคียงหรือดีกว่าในบางมิติแล้ว แต่อยู่ที่สามอย่างที่มารวมในแอปเดียวกัน ได้แก่ multimodal input combo การแก้ต่อแบบบทสนทนาที่จำ scene ได้ และการปล่อยบนช่องทาง consumer ที่มีผู้ใช้อยู่แล้วระดับพันล้านบัญชี
จุดแรกคือการรับ input ครบ 4 modality พร้อมกันในหนึ่ง prompt ตามที่ระบุใน ประกาศของ Google ผู้ใช้ใส่ข้อความเล่าเรื่อง รูปภาพอ้างอิงสไตล์ คลิปวิดีโอที่อยากให้แก้ และตัวอย่างเสียงประกอบได้ในการสั่งงานครั้งเดียว ขณะที่ TheNextWeb ระบุว่า Sora 2 ยังไม่รองรับการรวม image กับ audio และ Veo 3 รับ text หรือ image อย่างใดอย่างหนึ่งเท่านั้น
จุดที่สองคือ conversational editing loop ที่ Google เรียกว่า "the scene remembers what came before" หมายความว่าเมื่อผู้ใช้สั่งแก้ต่อ โมเดลจะรักษาตัวละคร เสื้อผ้า และฉากเดิมไว้ ไม่ได้ generate ใหม่ทั้งคลิป ในการสาธิตของ Paul J Lipsky คำสั่ง "เปลี่ยนสีเสื้อกั๊กเป็นน้ำเงิน" ทำให้ Omni เปลี่ยนแค่สีเสื้อจริง ๆ โดยใบหน้า ท่าทาง และพื้นหลังยังตรงกับคลิปแรก
จุดที่สามคือ distribution ที่ Sora ไม่มี เพราะ Google ปล่อย Omni เข้า YouTube Shorts และเครื่องมือ YouTube Create ตั้งแต่วันแรก ตามที่ TechCrunch ระบุไว้ ครีเอเตอร์ไทยที่มีบัญชี YouTube และใช้ Shorts เป็นประจำสามารถลองได้ทันทีโดยไม่ต้องสมัครแพลนแยก ในทางกลับกัน Sora ของ OpenAI ปิดฟีเจอร์ Cameos ที่เคยคล้ายกันไปก่อนหน้า โดย TechTimes ระบุชัดว่า Google สร้าง Omni Avatars โดยอ้างอิงพื้นฐานจาก Cameos ของ Sora ที่ถูกปิดไป
ฟีเจอร์ที่ทำได้จริง เรียงตาม flow การใช้งาน
การทดลอง Omni เริ่มจากการตั้งค่า avatar ครั้งเดียวในแอปมือถือ ขั้นตอนนี้ใช้เวลาประมาณสองนาที โดย Chrome Unboxed สรุปไว้ว่าผู้ใช้ต้องถ่ายใบหน้าตามคำสั่งบนจอ ขยับศีรษะตามมุมที่กำหนดในแสงที่เพียงพอ จากนั้นอ่านชุดตัวเลขและวลีสุ่มออกเสียงดัง ๆ เพื่อให้ระบบจับ cadence โทนเสียง และสำเนียง ตามที่ Chrome Unboxed รายงาน Google ยังบังคับว่าผู้ใช้ต้องอายุ 18 ปีขึ้นไป และต้อง setup ด้วยตัวเองเท่านั้น ไม่ใช่ upload รูปคนอื่น เพื่อกัน deepfake ตั้งแต่ขั้นตอน onboarding
หลัง avatar พร้อมใช้ ผู้ใช้เลือกได้ระหว่าง preset templates สำเร็จรูปกับการพิมพ์ prompt เอง ใน hands-on ของ Paul J Lipsky มี preset 3 ตัวที่นำมาสาธิต ได้แก่ Metallic ซึ่งเปลี่ยนผู้ใช้เป็นโลหะเหลวที่ไหลคลุมร่างกาย, Meme Me ซึ่ง generate meme video รอบตัวผู้ใช้ และ Indie Pastel ที่ให้โทนสมมาตรแบบ Wes Anderson ทุกชอต นอกจากนี้ยังมี preset Montage ที่รับรูปได้สูงสุด 5 รูปและคลิปวิดีโอ 1 คลิปมาตัดต่อรวมเป็นคลิปเดียว ทั้งนี้ตัวเลข 5 รูปและรายชื่อ preset เป็นการสังเกตของ creator ในคลิปต้นทาง Google ยังไม่ได้เผยแพร่รายการ preset อย่างเป็นทางการ จึงควรอ่านในฐานะ "ตามที่ creator ทดสอบเห็น" ไม่ใช่ spec ที่ Google ประกาศ
สำหรับการ generate ทั่วไป Google ระบุว่า Flash tier จำกัดคลิปไว้ที่ 10 วินาทีต่อหนึ่งการ generate ส่วน resolution 720p ที่ Paul J Lipsky ระบุในคลิป และเวลา generation 60-90 วินาทีตามรายงาน TechTimes เป็นค่าจากการทดสอบ hands-on ของ creator ไม่ใช่ spec ทางการของ Google ดังนั้นเมื่อนำไปอ้างอิงในงานควรระบุที่มาให้ตรง
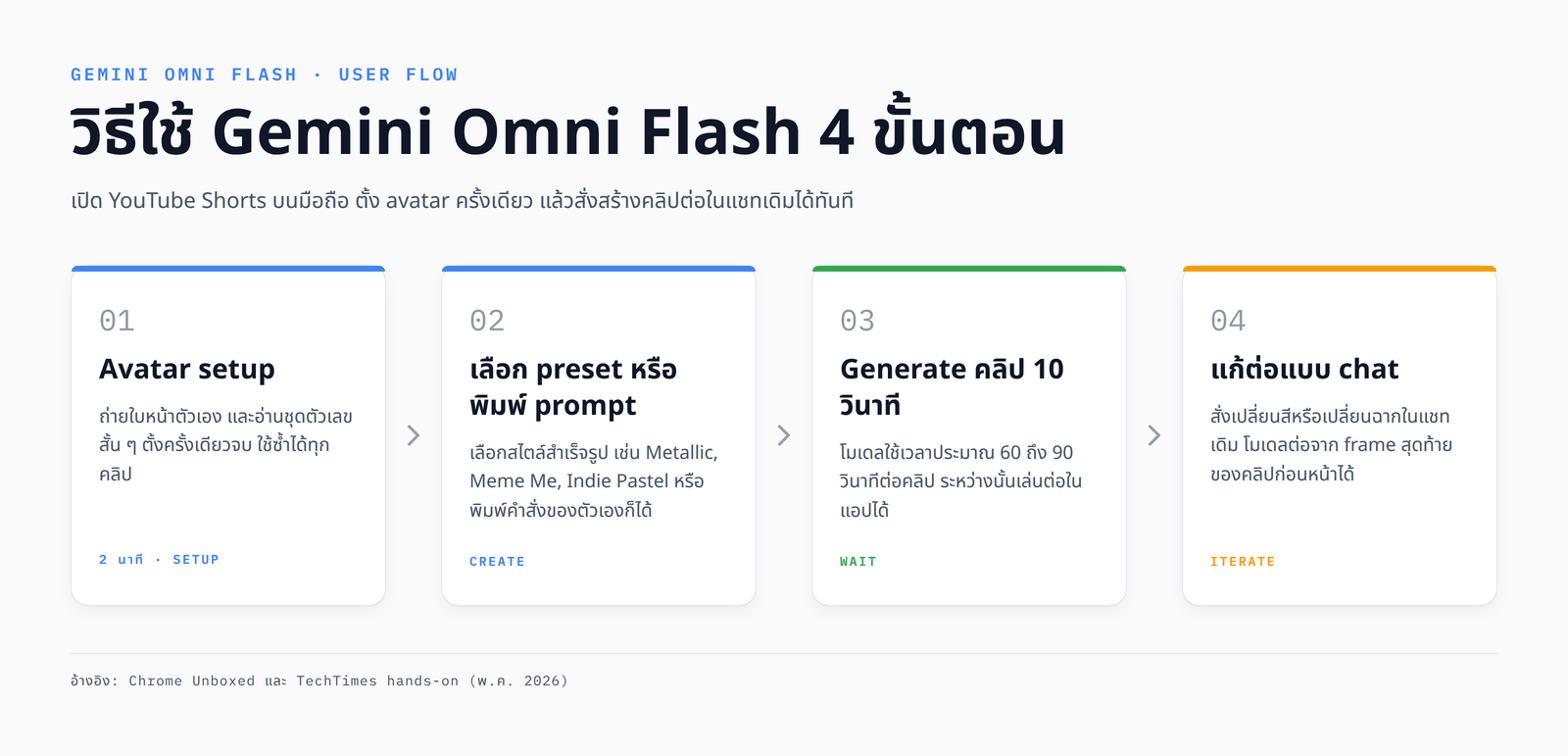
จุดที่ทำให้ workflow ของ Omni ต่างจากเครื่องมือ video gen ตัวอื่นคือการแก้ต่อในห้องแชทเดิม ในการสาธิตของ Paul J Lipsky คำสั่ง "pick up from the last frame" ทำให้ Omni สร้างคลิปต่อจากเฟรมสุดท้ายของคลิปแรกได้อย่างต่อเนื่อง ส่วนคำสั่ง "เปลี่ยนสีเสื้อกั๊กเป็นน้ำเงิน" แก้ attribute เดียวได้โดยไม่ทำลายภาพอื่นในเฟรม ฟีเจอร์ video-in/video-out ยังให้ผู้ใช้อัปคลิป dashcam ตัวเองเข้าไป แล้วสั่งให้ Omni เพิ่มภูเขาไฟกำลังระเบิดด้านหลังภูเขาในคลิปต้นฉบับโดยที่ภาพหลักไม่แตก เมื่อรวมกันแล้ว องค์ประกอบเหล่านี้ทำให้การปรับ creative หลายรอบใช้เวลาน้อยกว่าการ generate ใหม่ทั้งคลิป ซึ่ง Veo 3 และ Sora 2 ส่วนใหญ่ยังต้องทำ
อะไรใหม่จริง เทียบกับของที่คนอื่นมีอยู่แล้ว
ในกระแสข่าวรอบเปิดตัว มีหลายฟีเจอร์ที่ดูเหมือนใหม่ แต่หลายอย่างคู่แข่งทำได้ก่อนหรือทำได้ดีกว่าด้วยซ้ำ การแยกว่าอะไร "ใหม่จริง" อะไร "ตามคู่แข่ง" และอะไร "ยังต้องระวัง" จะช่วยให้ตัดสินใจได้ว่าควรย้ายงานบางส่วนมาใช้ Omni หรือยังควรอยู่กับเครื่องมือเดิม

ฟีเจอร์ที่ใหม่จริงในตลาดวิดีโอ AI ตอนนี้มีสามอย่าง ได้แก่ multimodal input combo ที่รับ text รวมกับ image, audio และ video ในการสั่งงานครั้งเดียว, conversational edit loop ที่จำตัวละครและฉากข้ามการแก้ได้ และการที่โมเดลอยู่ใน YouTube Shorts ฟรีตั้งแต่วันแรก ซึ่ง Sora ไม่เคยมี distribution channel ระดับนี้ ส่วนฟีเจอร์ที่ตามคู่แข่งแล้วคือ avatar ที่ใส่ตัวเองในคลิปได้ ซึ่ง Sora ทำผ่าน Cameos ไปก่อนหน้าและเพิ่งถูกปิด รวมถึง audio sync ในคลิปที่ Veo 3 และ Sora 2 ทำได้แล้ว ขณะที่ความยาว 10 วินาทีของ Omni Flash ยังสั้นกว่าของ Sora 2 Pro ซึ่งทำได้ 25 วินาที ตามที่ Metapress สรุปไว้
ส่วนข้อที่ต้องระวังมีสองเรื่อง เรื่องแรกคือ start-frame ของรูปที่อัปเข้าไปเป็น reference ยังหลุดบ่อย Paul J Lipsky สังเกตในคลิปเองว่าการใช้ภาพหรือคลิปก่อนหน้าเป็น start frame ยังให้ผลไม่นิ่ง เรื่องที่สองคือ SynthID watermark ที่ฝังอยู่ในทุกคลิป แม้มองไม่เห็นด้วยตา แต่ผู้ใช้ปิดไม่ได้ และตรวจสอบย้อนกลับได้ผ่าน Gemini app, Chrome หรือ Google Search ทำให้คลิปที่ใช้งานเชิงพาณิชย์ในบางอุตสาหกรรมใช้ Omni โดยตรงไม่ได้ หากลูกค้าระบุว่าห้ามมี AI watermark
เทียบกับ Sora 2, Veo 3 และ Kling
การเลือกใช้ Omni สำหรับงานจริงจำเป็นต้องเข้าใจว่ามันชนะคู่แข่งในแกนไหนและแพ้ในแกนไหน เพราะแต่ละโมเดลออกแบบมาเพื่อเป้าหมายต่างกัน

เมื่อเทียบกับ Sora 2 Pro ของ OpenAI ตามรายงาน Metapress Sora 2 Pro ยังนำที่ความยาวคลิป 25 วินาทีและความนิ่งของตัวละครเมื่อ generate หลายคลิปต่อเนื่อง แต่ Omni ชนะที่การรับ input หลาย modality ในครั้งเดียวและการแก้ต่อแบบ chat อีกทั้งฟีเจอร์ Cameos ของ Sora ถูกปิดไปแล้ว ทำให้ผู้ใช้ที่เคยพึ่ง Cameos ย้ายมาที่ Omni Avatars ในตอนนี้
เมื่อเทียบกับ Veo 3.1 ซึ่งเป็นโมเดลฝั่ง premium ของ Google เอง Veo 3 ออกแบบมาสำหรับ professional filmmaking และ enterprise โดยเข้าผ่าน Vertex AI ตามที่ WaveSpeed สรุปความต่าง 4 ข้อระหว่างทั้งสองโมเดลไว้ ส่วน Omni Flash เน้นมือถือและ consumer ที่ไม่ต้องตั้งค่ารายเดือน ทั้งสองโมเดลจึงไม่ได้แข่งกันโดยตรง แต่ตอบโจทย์คนละขั้นของ pipeline การผลิต
เมื่อเทียบกับ Kling 3.0 ของ Kuaishou และ Hailuo ของ MiniMax ทั้งสองตัวยังมี edge เรื่องคุณภาพภาพดิบและความหลากหลายของ motion โดยเฉพาะงานสไตล์โฆษณา การ์ตูน และ cinematic ส่วน Omni ชนะที่ workflow และการเข้าถึงฟรี ครีเอเตอร์ที่ต้องการคุณภาพภาพระดับงานโฆษณาจึงยังควรเก็บ Kling ไว้สำหรับงาน final ส่วน Omni เหมาะกับงาน iterate เร็ว ทดสอบหลาย version และโพสต์ลง Shorts โดยตรง
ฟีเจอร์ที่ Google ตั้งใจไม่ปล่อย และเหตุผลที่สำคัญต่อครีเอเตอร์ไทย
ส่วนที่หายไปจาก Omni Flash ไม่ใช่ความบังเอิญ แต่เป็นการตัดสินใจของ Google โดยตรง ตามที่ TechTimes และ TheNextWeb รายงานตรงกัน Google ระบุว่ายังไม่ปล่อยฟีเจอร์ general-purpose voice/speech editing ซึ่งหมายถึงการเปลี่ยนคำพูดในคลิปคนอื่นหรือใส่เสียงคนอื่นลงในคลิปที่ generate ออกมา Google ใช้ถ้อยคำว่า "still working to test this and better understand how we can bring this capability to users responsibly" แปลตรง ๆ คือ Google กังวลเรื่องการใช้สร้าง deepfake ในช่วงที่กฎหมายและบรรทัดฐานยังไม่ชัด
ในมุมของครีเอเตอร์ไทย ข้อจำกัดนี้กลับเป็นข้อดี เพราะกฎหมายเกี่ยวกับ deepfake ในไทยยังไม่ตกตะกอน Google บล็อกฟีเจอร์เสี่ยงตั้งแต่ต้นและฝัง SynthID watermark ในทุกคลิปแบบลบไม่ได้ จึงช่วยให้ครีเอเตอร์มีหลักฐานพิสูจน์ที่มาของคลิปได้ หากถูก clone หน้าหรือเสียง การมี SynthID ฝังไว้ในไฟล์โดยมองไม่เห็นแต่ตรวจสอบกลับได้ผ่าน Gemini app, Chrome หรือ Google Search จึงเป็น safety net สำคัญสำหรับครีเอเตอร์ที่ต้องเผยแพร่ตัวเองในวงกว้าง
Note: คลิปทุกอันที่ออกจาก Omni ติด SynthID แบบปิดไม่ได้ จึงช่วยแยก content ที่สร้างจาก AI ออกจาก content จริงได้ แม้ลายน้ำที่มุมจะถูกครอบตัดทิ้ง
อีกฟีเจอร์ที่ Google ยังไม่ปล่อยคือ Gemini Omni Pro ที่จะแก้ข้อจำกัด 10 วินาที ตอนนี้มีแค่ teaser และยังไม่มีกำหนดวันเปิดตัว ส่วน API สำหรับนักพัฒนา Google ระบุว่าจะเปิด "ในไม่กี่สัปดาห์" ตามที่ WaveSpeed สรุปไว้ นักพัฒนาที่อยาก integrate Omni เข้า product ของตัวเองจึงยังต้องรอ และช่วงนี้ยังใช้ Veo 3 API ที่เปิดอยู่แล้วบน Vertex AI ไปก่อนได้
ใช้กับงานจริงในไทยได้อย่างไร
เมื่อรู้แล้วว่า Omni ทำอะไรได้และไม่ได้ ขั้นต่อไปคือการ map ฟีเจอร์เหล่านี้กับงานจริง โดยมี 4 use case ที่เห็นภาพชัดในตลาดไทย
ครีเอเตอร์ TikTok และ YouTube Shorts สามารถใช้ Omni สร้าง B-roll และ visual cutaway สั้น 10 วินาทีแทนการถ่ายเอง เช่น ฉากเดินในปารีส ฉากใต้น้ำ หรือฉากแฟนตาซีที่ถ่ายจริงไม่ได้ด้วยงบที่มี การมี avatar ของตัวเองทำให้ insert ตัวเองในซีนเหล่านั้นได้โดยไม่ต้องทำ green screen และเพราะ Omni อยู่ใน YouTube Shorts โดยตรง ขั้นตอน publish จึงสั้นกว่าการ render นอกแอปแล้วอัปเข้า ส่วนข้อระวังคือถ้าทำ content รีวิวสินค้าหรือ collaboration กับแบรนด์ ต้องระวัง drift ที่ทำให้สินค้าหรือโลโก้แบรนด์ไม่ตรงรายละเอียด ซึ่งเป็นปัญหาที่โมเดล generative ทุกตัวยังเจอ
นักการตลาดและ SME ในไทยน่าจะได้ประโยชน์มากที่สุดจาก iteration speed ของ Omni เพราะการทำคลิปโฆษณา 10 วินาทีสำหรับยิง Meta Ads หรือ TikTok Ads มักต้อง A/B test หลาย creative workflow ใหม่คือพิมพ์ prompt หลัก generate version แรก จากนั้นสั่งแก้แบบ chat ทีละ attribute เช่น "เปลี่ยนสีโปรดักต์เป็นแดง" หรือ "เปลี่ยนพื้นหลังเป็นชายหาดภูเก็ต" ก็จะได้ 5-10 variant ภายในครึ่งชั่วโมง เร็วกว่าจ้าง production house หลายเท่าตัว ส่วนข้อระวังคือลูกค้าในกลุ่ม financial, healthcare และ political ส่วนใหญ่มี brand safety guideline ที่ไม่อนุญาตให้ใช้ video ที่มี AI watermark ติด ดังนั้นต้องเช็คข้อตกลงก่อนรับงาน
ครูและคอนเทนต์ครีเอเตอร์การศึกษามีโอกาสใช้ Omni สร้างภาพประกอบบทเรียนวิทยาศาสตร์และประวัติศาสตร์ที่ถ่ายจริงไม่ได้ เช่น จำลองการระเบิดของภูเขาไฟ การโคจรของดาวเคราะห์ หรือเหตุการณ์ประวัติศาสตร์ที่ต้องการ visualization ในเดโม่ของ Google มีตัวอย่าง claymation อธิบาย protein folding ที่ใช้เวลา generate ไม่นาน แต่ครูที่นำไปใช้ต้อง fact-check เนื้อหาเองทุกครั้ง เพราะ Omni สร้าง "ภาพที่ดูสมจริง" ไม่ได้การันตี "ความถูกต้องทางวิชาการ" 100% จึงควรใช้เป็น visual aid ประกอบการสอน ไม่ใช่ source of truth
agency ที่ทำงาน pitch ลูกค้าจะใช้ Omni ทำ mockup คอนเซ็ปต์ก่อนถ่ายจริงได้ การสร้าง storyboard ที่เคลื่อนไหวแทน static slide ทำให้ลูกค้าเห็นภาพคอนเซ็ปต์ชัดขึ้นในห้องประชุม และเมื่อมี feedback ก็แก้ในแชทได้เลย ไม่ต้องกลับไปจ้าง animator ทำใหม่ แต่สำหรับ avatar voice clone กับภาษาไทย ตอนนี้สาธิตที่เห็นเกือบทั้งหมดเป็นภาษาอังกฤษ แม้ Gemini Live เพิ่งเปิดรองรับไทย และ Gemini 3 ระบุว่าเข้าใจไทยทั้ง formal และ informal แต่คุณภาพของ avatar voice clone ในภาษาไทยยังไม่มี source ทางการยืนยัน จึงควรทดสอบจริงในงาน internal ก่อนใช้กับงาน production
วิธีเริ่มใช้ตั้งแต่วันนี้
Google AI Plus เป็นแพลนที่บรรจุ Gemini, Nano Banana Pro, Flow และ Omni Flash ไว้ในชุดเดียว และเปิดให้บริการในไทยแล้ว ตามที่ระบุใน ประกาศของ Google ซึ่งกล่าวถึงการขยายไป 35 ประเทศใหม่และมีรายชื่อ "ประเทศไทย" อยู่ในรอบนี้ ราคาในไทยยังต้องเปิดดูจากหน้า Google One ผ่าน IP ไทยอีกครั้ง ส่วน baseline ของแพลนนี้ในตลาดอเมริกาอยู่ที่ 7.99 ดอลลาร์ต่อเดือน
สำหรับการเริ่มต้นโดยไม่จ่ายเลย ผู้ใช้สามารถเข้าแอป Gemini แล้วกดไอคอน + ที่หน้าแชท หาก account นั้นมีสิทธิ์เข้า Omni จะเห็นปุ่ม Avatars สำหรับ setup ครั้งแรก ส่วนบน YouTube ให้เข้า YouTube Shorts กด create แล้วเลือก AI tools หาก Omni เปิดให้บัญชีนั้นแล้วก็จะปรากฏเป็นหนึ่งในตัวเลือก Google ยังไม่ได้ระบุว่า rollout ในประเทศไทยจะเสร็จสมบูรณ์เมื่อใด ดังนั้นหากยังไม่เห็นปุ่ม ให้รอประมาณหนึ่งถึงสองสัปดาห์ตามรอบที่ Google ทยอยปล่อยตามภูมิภาค
คำแนะนำสำหรับการลองครั้งแรกคือเริ่มจาก preset templates อย่าง Metallic, Meme Me หรือ Indie Pastel ก่อน เพราะให้ผลลัพธ์นิ่งกว่าและไม่ต้องเขียน prompt ยาว เมื่อชินกับ output ของโมเดลแล้วค่อยขยับไปเขียน custom prompt และทดลอง video-in/video-out กับคลิปจริงของตัวเอง ฟีเจอร์ continuation ยังใช้ขยายเรื่องให้ยาวเกิน 10 วินาทีได้ โดยสั่ง "pick up from the last frame" ต่อกันเป็น chain หลายคลิป
สรุปคือ Gemini Omni Flash ไม่ใช่โมเดลที่ชนะคู่แข่งทุกแกน คุณภาพภาพยังไม่ได้นำตลาด ความยาวคลิปก็สั้นกว่า Sora 2 Pro และ resolution ที่ creator ทดสอบเห็นที่ 720p ยังไม่ใช่ระดับ broadcast แต่จุดที่ Omni ทำได้ดีคือ workflow การแก้ต่อในแชท การรวม input หลาย modality และการอยู่ในเครื่องมือฟรีที่คนไทยใช้อยู่แล้ว สำหรับครีเอเตอร์ นักการตลาด ครู และ agency ในไทย การลองภายในสองสัปดาห์นี้น่าจะคุ้มเวลา เพื่อดูว่าควรปรับ workflow ส่วนไหนให้เร็วขึ้น ก่อนที่ Omni Pro และ API จะมาเปิดประตูชุดต่อไป



