Headroom เครื่องมือโอเพนซอร์สจากวิศวกร Netflix ที่บีบ token ของ AI agent ลง 60–95%
Headroom คือ proxy โอเพนซอร์สที่บีบข้อมูลที่ AI agent ต้องอ่านให้สั้นลงก่อนส่งต่อให้ LLM จึงลด token ได้ 60–95% โดยคำตอบยังถูกต้องอยู่ บทความนี้อธิบายว่ามันทำงานยังไง และเริ่มใช้วันนี้ได้แบบไหน

ค่า token ของ AI agent ส่วนใหญ่ไม่ได้หมดไปกับการ "คิด" แต่หมดไปกับการ "อ่าน" Headroom คือเครื่องมือโอเพนซอร์สที่เกิดมาเพื่อแก้ตรงนี้โดยเฉพาะ มันเป็นตัวกลางเล็กๆ ที่คั่นระหว่างแอป AI agent กับ API ของโมเดลภาษา แล้วบีบสิ่งที่ agent ต้องอ่านให้สั้นลงก่อนถึงโมเดล ไม่ว่าจะเป็นผลลัพธ์จากการเรียกเครื่องมือ ไฟล์ code หรือข้อมูลที่ดึงมาจากฐานความรู้ ตัวเลขที่มันเคลมคือลด token ได้ 60–95% โดยที่คำตอบยังถูกต้องเหมือนเดิม
คนสร้างคือ Tejas Chopra วิศวกรอาวุโสจาก Netflix และเขาเปิดให้ใช้ฟรีแบบโอเพนซอร์ส มีชุดเครื่องมือสำหรับนักพัฒนาให้เลือกทั้งฝั่งภาษา Python และภาษา TypeScript ส่วนตัวเลขที่ฟังดูเกินจริงแต่เป็นจุดที่ทำให้คนสนใจคือ Headroom เคลมว่าช่วยผู้ใช้ประหยัดค่า token ไปแล้วรวมราว $700,000
agent ไม่ได้แพงเพราะคิดเยอะ แต่เพราะอ่านเยอะ
ลองนึกภาพตอน agent ทำงานจริง มันเรียกเครื่องมือแล้วได้ JSON ก้อนใหญ่กลับมา เปิดไฟล์ code ทั้งโปรเจกต์ขึ้นมาอ่าน หรือรัน test แล้วได้ build log ยาวเหยียด ข้อมูลทั้งหมดนี้ถูกนับเป็น token ที่ต้องจ่าย ทั้งที่จริงๆ แล้วโมเดลอาจต้องการแค่ส่วนสำคัญไม่กี่บรรทัด
ปัญหาคือข้อมูลพวกนี้มีส่วนที่ไม่จำเป็นปนอยู่เยอะมาก JSON ยาวเป็นพันแถวอาจมีจุดสำคัญจริงๆ แค่ไม่กี่แถว build log ที่ยาวเต็มหน้าจออาจมีบรรทัดที่ "fail" แค่บรรทัดเดียว ที่เหลือคือ test ที่ผ่านหมดและไม่ช่วยให้ตัดสินใจ แต่ agent ก็ยังต้องส่งทั้งก้อนไปให้โมเดลอ่านอยู่ดี เพราะมันไม่รู้ว่าส่วนไหนสำคัญจนกว่าจะอ่านจบ
Headroom เข้ามาแก้ตรงรอยต่อนี้ แทนที่จะปล่อยให้ข้อมูลก้อนใหญ่ไหลเข้าโมเดลตรงๆ มันดักไว้ก่อน บีบให้เหลือส่วนสำคัญ แล้วค่อยส่งต่อ ผลคือโมเดลได้อ่านเฉพาะสิ่งที่สำคัญจริงๆ ด้วยจำนวน token ที่น้อยลงมาก
ตัวกลางที่คั่นอยู่ระหว่างทาง
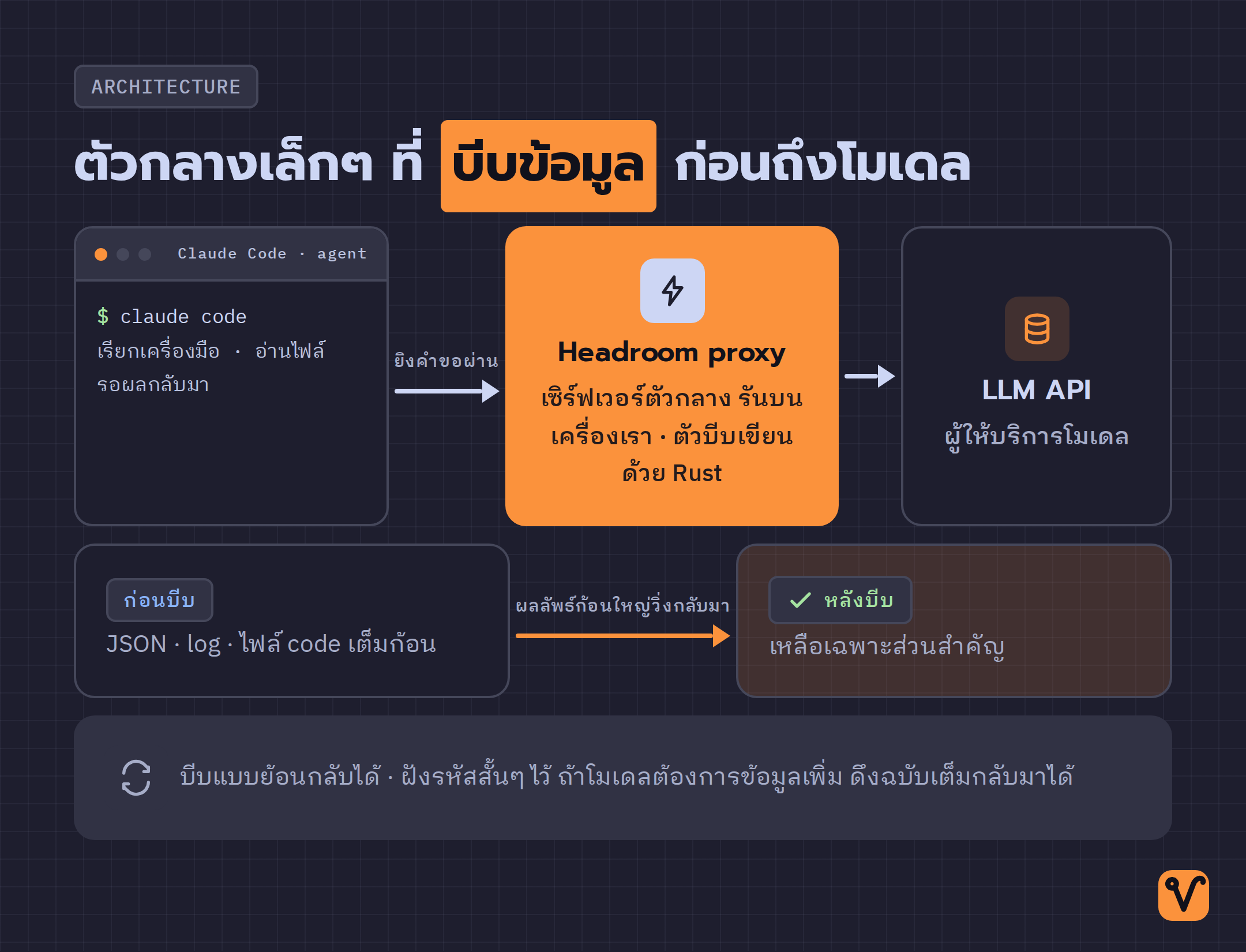
กลไกของ Headroom ตรงไปตรงมากว่าที่คิด มันคือเซิร์ฟเวอร์ตัวกลางที่เขียนด้วยภาษา Python เรารันไว้บนเครื่องตัวเอง แล้วตั้งค่าแอป AI agent ของเรา เช่น Claude Code เครื่องมือเขียน code ด้วย AI ของบริษัท Anthropic ให้ส่งคำขอผ่าน Headroom ก่อน แทนที่จะยิงตรงเข้าเซิร์ฟเวอร์ของผู้ให้บริการโมเดล
พอผลลัพธ์จากการเรียกเครื่องมือวิ่งกลับมา Headroom จะคว้าไว้ แล้วบีบด้วยตัวประมวลผลที่เขียนด้วยภาษา Rust อยู่เบื้องหลัง จึงเร็วพอที่จะไม่หน่วงงาน จากนั้นส่งเฉพาะเวอร์ชั่นที่บีบแล้วต่อให้โมเดล จุดที่ฉลาดคือการบีบนี้ย้อนกลับได้ Headroom ฝังรหัสสั้นๆ ไว้ในข้อความที่บีบแล้ว เหมือนทิ้งร่องรอยไว้ ถ้าโมเดลรู้สึกว่าข้อมูลที่ได้ไม่พอ ก็ใช้รหัสนั้นดึงข้อมูลฉบับเต็มกลับมาได้ ไม่ใช่การตัดทิ้งถาวรแบบกู้คืนไม่ได้
บีบไม่เหมือนกันตามชนิดของข้อมูล

หัวใจที่ทำให้ Headroom บีบได้แรงโดยไม่ทำให้คำตอบเพี้ยน คือมันไม่ได้ใช้วิธีบีบแบบเดียวกับทุกอย่าง แต่ดูก่อนว่าข้อมูลที่อ่านเป็นชนิดไหน แล้วเลือกตัวบีบที่เข้าใจชนิดนั้นโดยเฉพาะ
- ข้อมูล JSON ตัวบีบจะเก็บแถวที่ผิดปกติหรือเป็นกรณีพิเศษเอาไว้ แล้วตัดส่วนที่ซ้ำๆ ออก เพราะจุดผิดปกตินี่แหละคือสิ่งที่โมเดลต้องเห็น
- ไฟล์ code ตัวบีบอ่านโครงสร้างจริงของ code ไม่ใช่มองเป็นข้อความเฉยๆ จึงรู้ว่าส่วนไหนสำคัญและตัดส่วนไหนได้โดยไม่ทำให้ความหมายของ code หาย
- build log เก็บเฉพาะบรรทัดที่ fail ทิ้ง test ที่ผ่านหมด เพราะ log ที่ผ่านไม่ได้ช่วยให้โมเดลแก้ปัญหา
- ข้อความทั่วไป ใช้โมเดลขนาดเล็กชื่อ Compress Base ที่ Tejas เทรนเอง และรันบนเครื่องของเราเอง การบีบจึงไม่กิน token เพิ่ม และ code หรือข้อมูลไม่ต้องวิ่งออกไปข้างนอก
วิธีคิดง่ายๆ คือถ้าข้อมูลเป็น log ให้สนใจที่บรรทัดที่ fail · ถ้าเป็น code ให้สนใจที่โครงสร้าง · ถ้าเป็น JSON ให้สนใจที่ของแปลก ตัวบีบแต่ละแบบทำหน้าที่นั้นแทนเราโดยอัตโนมัติ
ตัวเลขที่เห็นจริง
ในการทดสอบให้ Claude Code อ่านไฟล์ TypeScript ทั้งโปรเจกต์ มี Headroom คั่นกลางทำให้งานนั้นจบที่ราว 89,100 token ส่วนในอีกตัวอย่างที่เป็นการวิเคราะห์ log file Headroom บีบลงได้ถึง 98% หรือประหยัดไปกว่า 17,000 token ในงานเดียว
แต่มีรายละเอียดที่ควรรู้ การประหยัดไม่ได้เกิดทุกสถานการณ์ บน Opus ซึ่งเป็นโมเดลตัวแรงที่สุดของ Claude เมื่อตั้งให้คิดแบบเบาๆ แทบไม่เห็นผล จะเริ่มเห็นความต่างชัดตั้งแต่ตั้งให้คิดระดับปานกลางขึ้นไป ยิ่ง agent ทำงานหนักและอ่านเยอะ Headroom ยิ่งมีของให้บีบ
ราคาที่ต้องจ่ายของการบีบ
เครื่องมือฟรีที่ดีแค่ไหนก็ยังมีจุดที่ต้องระวัง และ Headroom ก็ไม่ต่างกัน ปัญหาหลักมาจากตัวมันเองนั่นแหละ เวลาบีบแรงเกินไปจนโมเดลได้ข้อมูลไม่พอ โมเดลจะขอข้อมูลฉบับเต็มกลับมา ทำให้ต้องวิ่งไปขอข้อมูลอีกรอบ และบางกรณีรอบนี้ทำให้ใช้ token รวมมากกว่าตอนไม่ใช้ Headroom เสียอีก
ข่าวดีคือ Headroom พยายามเรียนรู้จากความผิดพลาดนี้ผ่านฟีเจอร์ชื่อ Headroom Learn มันจะไล่ดู session ที่เคยพลาดว่า บีบหนักเกินไปตรงไหนจนต้องขอข้อมูลกลับ แล้วจำไว้ไม่ทำซ้ำในครั้งถัดไป อีกฟีเจอร์ที่น่าสนใจคือการให้เครื่องมือต่างๆ แชร์ข้อมูลที่จำไว้ร่วมกัน ทำให้ AI agent หลายตัว เช่น Claude และ Codex ซึ่งเป็นผู้ช่วยเขียน code ของ OpenAI ใช้ข้อมูลที่บีบแล้วก้อนเดียวกันได้ แทนที่แต่ละตัวจะบีบข้อมูลซ้ำกันเอง
เริ่มลองวันนี้ได้ยังไง
ถ้าอยากลองจริง ให้เริ่มสั้นๆ สามขั้นตอนนี้ ก่อนอื่นเตรียม Python เวอร์ชั่น 3.12 ให้พร้อม จุดนี้สำคัญเพราะ Headroom ยังไม่รองรับเวอร์ชั่นที่ใหม่กว่า 3.12 ถ้าเครื่องเป็น 3.13 ขึ้นไปจะติดตั้งไม่ผ่าน
- ติดตั้งตัวกลางด้วยคำสั่ง
pip install headroom(หรือจะใช้ UV ตัวจัดการแพ็กเกจของ Python ก็ได้) - เปิดมันขึ้นมาด้วยคำสั่ง
headroom proxy - ตั้งค่าที่อยู่ของเซิร์ฟเวอร์ในแอป AI agent ของเราให้ชี้มาที่ Headroom แทนที่จะชี้ตรงไปหาผู้ให้บริการโมเดลเหมือนเดิม
แค่นั้นก็เริ่มใช้ได้แล้ว แอปอย่าง Claude Code ไม่ต้องเปลี่ยนวิธีทำงานเลย เพราะมันยังคุยกับโมเดลเหมือนเดิม แค่มี Headroom มาคั่นกลางช่วยบีบให้ ใครอยากดู code หรืออ่านวิธีตั้งค่าแบบละเอียด ดูได้ที่ repo ของ Headroom บน GitHub
ภาพรวมที่ Better Stack สรุปไว้ในคลิปคือ Headroom แก้ปัญหาเดียวกับเวลาเราเปิด Claude Code โหมดแรงๆ แล้วให้ตัวช่วยย่อยหลายตัวทำงานพร้อมกันจน token พุ่งไม่หยุด Headroom ไม่ได้ห้าม agent ทำงานหนัก แต่ทำให้ทุกครั้งที่มันอ่าน มันอ่านเฉพาะของที่จำเป็น
เพราะสุดท้ายแล้ว ค่าใช้จ่าย AI ที่ถูกลงไม่ได้มาจากการให้ agent คิดน้อยลง แต่มาจากการให้มันอ่านเฉพาะสิ่งที่ต้องอ่านจริงๆ
ที่มา: คลิป Headroom: The Netflix Tool That Makes AI Agents 10x Cheaper จากช่อง Better Stack
ชอบเรื่องแนวนี้ มีอีบุ๊คฟรีให้อ่านต่อ
สร้าง Claude Skill แบบไม่ต้องรู้โค้ด คู่มือสร้าง Claude Skill ของคุณเองด้วยการคุยกับ Claude Code เป็นภาษาไทย
กดสมัครแล้วเราจะส่งเทคนิค AI และของแจกใหม่ๆ ให้ทางอีเมล เลิกรับได้ตลอด
Claude Cowork · The Business Playbook

ฉบับภาษาไทย 15 บท เรียนรู้ผ่านโปรเจกต์จำลองต่อเนื่องทั้งเล่ม ตั้งแต่ตั้งค่า Workspace จัดการไฟล์ เชื่อมแอป ตั้งระบบอัตโนมัติ จนถึงสร้าง Plugin


