Kimi K2.7 Code · โมเดลเขียนโค้ดตัวใหม่จาก Moonshot เปิด weights ให้โหลดไปรันเองได้ เรียก API ฟรี
Kimi K2.7 Code คือโมเดล AI เขียนโค้ดตัวใหม่ของ Moonshot ที่เปิด weights ให้โหลดไปรันบนเครื่องตัวเองได้ และมี API ฟรีให้เรียกใช้ สำหรับคนที่อยากสั่ง AI สร้างเกมหรือแอปเล็กๆ จากศูนย์ นี่คือตัวเลือกฟรีที่ไม่ต้องผูกกับโมเดลเดียวหรือจ่ายรายเดือน

Kimi K2.7 Code คือโมเดล AI เขียนโค้ดตัวใหม่จาก Moonshot บริษัท AI ผู้สร้างผู้ช่วย Kimi จุดที่น่าสนใจคือ Moonshot เปิด weights หรือไฟล์ตัวโมเดลให้ทุกคนโหลดไปรันบนเครื่องตัวเองได้ พร้อมมี API ฟรีให้เรียกใช้ ไม่ใช่โมเดลปิดที่ต้องสมัครจ่ายรายเดือนถึงจะแตะได้ ภายในเดือนเดียวมีคนโหลดไปแล้วกว่า 56,000 ครั้ง
สำหรับคนที่กำลังสั่ง AI ให้เขียนโค้ดสร้างของจริง ไม่ว่าจะเป็นเกมเล็กๆ แอปสั้นๆ หรือสคริปต์ที่อยากได้ นี่คือตัวเลือกฟรีอีกตัวที่เก่งขึ้นจากรุ่นก่อนพอสมควร และช่วยให้ไม่ต้องผูกงานไว้กับโมเดลเจ้าใหญ่เพียงตัวเดียว บทความนี้จะเล่าว่ามันคืออะไร เก่งแค่ไหนเมื่อเทียบกับตัวที่หลายคนใช้กันอยู่ และจะเริ่มลองยังไงให้เร็วที่สุด
โมเดลที่สร้างมาเพื่อ "ทำงานโค้ดให้จบ" ไม่ใช่แค่ตอบ
Kimi K2.7 Code ต่อยอดมาจากรุ่นก่อนหน้าคือ Kimi K2.6 โดยจูนมาให้เน้นงานเขียนโค้ดแบบ agentic เป็นพิเศษ คำว่า agentic ในที่นี้หมายถึงโมเดลที่ทำงานโค้ดต่อเนื่องหลายขั้นได้เอง · อ่านโครงโปรเจกต์ · แก้ไฟล์ · รันคำสั่ง · แล้ววนกลับมาแก้ต่อ ไม่ใช่แค่พ่นโค้ดออกมาก้อนเดียวแล้วจบ
จุดที่ทำให้มันทำงานยาวๆ ได้ดีคือ รุ่นนี้ทำงานในโหมดคิด (Thinking mode) ตลอดเวลาและปิดไม่ได้ อีกทั้งยังเก็บสิ่งที่คิดไว้ข้ามรอบคำสั่ง พอเจองานที่ต้องไล่แก้หลายไฟล์หรือแก้หลายรอบ มันจึงยังจำได้ว่ากำลังทำอะไรค้างอยู่ ไม่หลุดบริบทกลางทาง ที่น่าสนใจคือถึงจะคิดเยอะ แต่รุ่นนี้ใช้ token ในการคิดน้อยลงราว 30% เทียบกับรุ่นก่อน แปลว่าทำงานยาวๆ ได้ด้วยต้นทุนที่ต่ำลง
เก่งขึ้นจริง แต่ยังตามเจ้าใหญ่อยู่หนึ่งช่วงตัว

ส่วนนี้ต้องพูดกันตรงๆ ทั้งสองด้าน Moonshot วัดผล Kimi K2.7 Code เทียบกับ GPT-5.5 และ Claude Opus 4.8 ในชุดทดสอบงานเขียนโค้ดหลายตัว ภาพรวมคือมันเก่งขึ้นชัดเจนจากรุ่นก่อน แต่ยังไม่ถึงขั้นล้มสองเจ้าใหญ่
ยกตัวอย่างชุดทดสอบหลักของ Moonshot เองอย่าง Kimi Code Bench v2 รุ่นก่อน (K2.6) ทำได้ 50.9 คะแนน ส่วนรุ่นใหม่นี้ขยับขึ้นเป็น 62.0 ขณะที่ GPT-5.5 อยู่ที่ 69.0 และ Claude Opus 4.8 อยู่ที่ 67.4 จะเห็นว่ารุ่นใหม่ไล่เข้ามาใกล้มากขึ้น แต่ยังตามอยู่ราวหนึ่งช่วงตัว ผลลักษณะนี้เจอซ้ำในชุดทดสอบอื่นเกือบทั้งหมด · ดีขึ้นจากตัวเอง แต่ยังไม่แซงตัวท็อปของตลาด
| ชุดทดสอบ | K2.6 | K2.7 Code | GPT-5.5 | Claude Opus 4.8 |
|---|---|---|---|---|
| Kimi Code Bench v2 | 50.9 | 62.0 | 69.0 | 67.4 |
| ProgramBench | 48.3 | 53.6 | 69.1 | 63.8 |
| MCP Atlas | 69.4 | 76.0 | 79.4 | 81.3 |
ตัวเลขพวกนี้ไม่ได้แปลว่าโมเดลฟรีตัวนี้แทน Claude หรือ GPT ได้ทุกงาน แต่มันบอกอย่างหนึ่งที่สำคัญ · สำหรับงานเขียนโค้ดทั่วไปที่ไม่ได้ยากที่สุดในโลก ช่องว่างระหว่างของฟรีกับของเสียเงินกำลังแคบลงเรื่อยๆ และนั่นคือเหตุผลที่มันคุ้มจะลอง
ของฟรีที่จับต้องได้จริง ไม่ใช่แค่ปล่อยไฟล์ทิ้งไว้
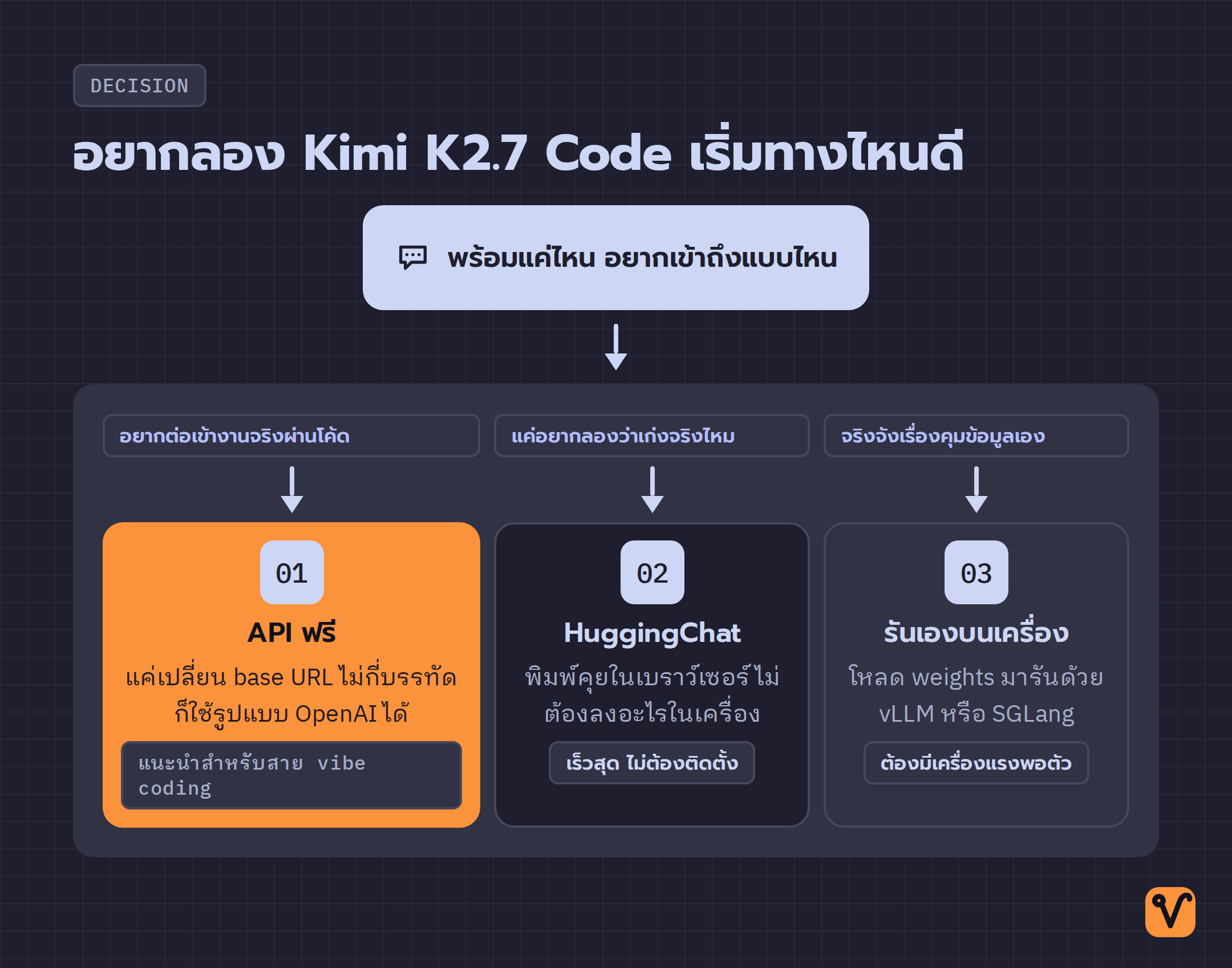
คำว่าเปิด weights ของหลายโมเดลมักจบที่ "โหลดได้นะ แต่จะรันเองต้องมีเครื่องแรงมากๆ" สำหรับ Kimi K2.7 Code ข้อจำกัดเรื่องเครื่องยังมีอยู่จริงเพราะตัวโมเดลใหญ่มาก แต่ Moonshot เปิดทางให้เข้าถึงได้หลายระดับ ไม่ได้บังคับว่าต้องมีการ์ดจอระดับเทพถึงจะแตะได้
- อยากลองเร็วสุด ไม่ต้องติดตั้งอะไร · เปิด HuggingChat ซึ่งเป็นเว็บแชตสำหรับลองโมเดลโดยตรง แล้วพิมพ์คุยได้เลยในเบราว์เซอร์ ไม่ต้องลงอะไรในเครื่อง
- อยากต่อเข้างานจริงผ่านโค้ด · มี API ฟรีที่ Kimi API Platform ซึ่งใช้รูปแบบการเชื่อมต่อแบบเดียวกับของ OpenAI และ Anthropic สองเจ้าใหญ่ที่หลายคนคุ้นอยู่แล้ว · โค้ดเดิมที่เขียนไว้จึงแทบไม่ต้องแก้
- อยากรันเองบนเครื่องตัวเอง · โหลดไฟล์โมเดลจาก Hugging Face มารันเป็นบริการในเครื่องด้วยเครื่องมืออย่าง vLLM หรือ SGLang (โปรแกรมสำหรับรันโมเดลภาษาขนาดใหญ่บนเซิร์ฟเวอร์ของตัวเอง) เหมาะกับคนที่มีเครื่องแรงและอยากคุมข้อมูลเองทั้งหมด
วิธีเลือกไม่ซับซ้อน · ถ้าแค่อยากลองว่ามันเก่งจริงไหมให้เปิด HuggingChat · ถ้าอยากเอาไปต่อกับโปรเจกต์ที่มีอยู่ให้ใช้ API ฟรี · ส่วนการรันเองเก็บไว้ตอนที่จริงจังเรื่องความเป็นส่วนตัวของข้อมูลและมีเครื่องพร้อมแล้วค่อยทำ
เริ่มลองวันนี้แบบไม่ต้องลงทุนอะไร
วิธีที่เร็วและถูกที่สุดสำหรับสาย vibe coding คือต่อ API ฟรีเข้ากับเครื่องมือที่คุณใช้สั่ง AI เขียนโค้ดอยู่แล้ว เพราะ API ของ Kimi ใช้รูปแบบเดียวกับ OpenAI ขั้นตอนเริ่มต้นจึงสั้นมาก
- สมัครและขอ API key ที่ Kimi API Platform
- ในเครื่องมือเขียนโค้ดที่ใช้อยู่ ให้ไปที่ช่องตั้งค่าที่อยู่เซิร์ฟเวอร์ (มักเขียนว่า base URL) แล้วเปลี่ยนไปชี้ที่อยู่ของ Kimi แทนของเดิม จากนั้นวางคีย์ที่เพิ่งได้มา
- ตั้งชื่อโมเดลเป็น
moonshotai/Kimi-K2.7-Codeแล้วลองสั่งงานแรกได้เลย
ลองเริ่มจากโจทย์เล็กๆ ที่วัดผลได้ทันที เช่นสั่งตรงๆ ว่า "สร้างเกมงูเล่นในเบราว์เซอร์ด้วย HTML กับ JavaScript ไฟล์เดียว" แล้วดูว่ามันเขียนงานทั้งก้อนออกมาได้ใกล้เคียงที่ต้องการแค่ไหน ถ้าอยากได้เครื่องมือฝั่ง agent ที่ Moonshot ทำมาคู่กันโดยเฉพาะ ก็มี Kimi Code CLI ซึ่งเป็นโปรแกรมสำหรับสั่งให้โมเดลเขียนและแก้โค้ดผ่านหน้าจอบรรทัดคำสั่งบนเครื่องได้อีกทาง
ทำไมการมีตัวเลือกฟรีที่เก่งขึ้นถึงสำคัญ
สิ่งที่ Kimi K2.7 Code สะท้อนไม่ใช่แค่โมเดลตัวเดียวที่เก่งขึ้น แต่คือทิศทางที่โมเดลฟรีแบบเปิด weights กำลังไล่ตามของเสียเงินได้ใกล้กว่าเดิม สำหรับคนไทยที่อยากหัดสั่ง AI สร้างของจริง การมีโมเดลฟรีที่พอใช้งานได้จริงหมายความว่าได้ลองเล่น ลองพังโปรเจกต์ และลองสร้างใหม่ได้เต็มที่โดยไม่ต้องกังวลค่าใช้จ่ายรายเดือน
แน่นอนว่าของฟรีก็มีต้นทุนของมัน · โมเดลตัวใหญ่แบบนี้ถ้าจะรันเองต้องใช้เครื่องที่แรงพอตัว และถ้าใช้ API ฟรีก็ต้องยอมรับว่าข้อมูลที่ส่งเข้าไปวิ่งผ่านเซิร์ฟเวอร์ของผู้ให้บริการ งานที่อ่อนไหวจริงๆ ต้องคิดเรื่องนี้ก่อนเสมอ
แต่สำหรับช่วงเริ่มต้นและการเรียนรู้ ข้อจำกัดพวกนี้แทบไม่ใช่อุปสรรค ที่ผ่านมาคนมักคิดว่าต้องจ่ายแพงก่อนถึงจะได้ AI เขียนโค้ดที่ใช้ได้ · ยิ่งของฟรีไล่เข้าใกล้ของเสียเงินมากขึ้นเท่าไร คำถามสำคัญก็ยิ่งเปลี่ยนจาก "จะใช้ตัวไหนดี" ไปเป็น "จะเริ่มลองวันนี้ด้วยอะไรดี"
ที่มา: model card moonshotai/Kimi-K2.7-Code จาก Hugging Face
ชอบเรื่องแนวนี้ มีอีบุ๊คฟรีให้อ่านต่อ
Local LLM ฉบับเข้าใจง่าย รัน AI ไว้ในเครื่องตัวเอง ติดตั้ง อัปเดต จัดการ ลบ ครบวงจรด้วย Ollama
กดสมัครแล้วเราจะส่งเทคนิค AI และของแจกใหม่ๆ ให้ทางอีเมล เลิกรับได้ตลอด
Claude Cowork · The Business Playbook

ฉบับภาษาไทย 15 บท เรียนรู้ผ่านโปรเจกต์จำลองต่อเนื่องทั้งเล่ม ตั้งแต่ตั้งค่า Workspace จัดการไฟล์ เชื่อมแอป ตั้งระบบอัตโนมัติ จนถึงสร้าง Plugin


