Ornith-1.0 โมเดลเขียนโค้ดโอเพนซอร์สที่วางแผนงานให้ตัวเองก่อนลงมือ · รุ่น 9B โหลดมารันในเครื่องเองได้ฟรี
Ornith-1.0 คือโมเดลเขียนโค้ดโอเพนซอร์สตัวแรกของค่าย DeepReinforce ที่ฝึกมาให้วางแผนงานให้ตัวเองเป็นขั้นๆ ก่อนลงมือเขียนจริง รุ่นเล็ก 9B โหลดมารันในเครื่องตัวเองได้ฟรีโดยไม่ต้องจ่ายค่า API รายเดือน และไลเซนส์ MIT ยังเปิดให้เอาไปใช้เชิงพาณิชย์ได้

Ornith-1.0 คือโมเดลภาษาโอเพนซอร์สที่ฝึกมาเพื่อเขียนโค้ดโดยเฉพาะ และเล็กพอจะโหลดมารันในเครื่องตัวเองได้โดยไม่ต้องจ่ายค่า API รายเดือน นี่คือโมเดลตัวแรกที่ค่าย DeepReinforce ปล่อยสู่สาธารณะ โดยเปิดให้ทุกคนโหลดตัวโมเดลไปรันเองได้ (open weights) ภายใต้ไลเซนส์ MIT ที่อนุญาตให้นำไปใช้ ดัดแปลง และต่อยอดในเชิงพาณิชย์ได้อย่างอิสระ ไม่ว่าอยู่ประเทศไหนก็โหลดไปใช้ได้เหมือนกัน
สิ่งที่ทำให้มันต่างจากโมเดลเขียนโค้ดตัวอื่นไม่ได้อยู่ที่ความเร็วหรือขนาด แต่อยู่ที่วิธีคิดงาน ก่อนจะลงมือเขียนโค้ดจริง Ornith-1.0 จะวางแผนงานให้ตัวเองเป็นขั้นๆ ก่อน แล้วค่อยทำตามแผนนั้นทีละขั้น เทคนิคนี้ทีมผู้สร้างเรียกว่า self-scaffolding และเป็นหัวใจที่ทำให้โมเดลขนาดเล็กตัวนี้สู้กับโมเดลที่ใหญ่กว่าหลายเท่าในงานเขียนโค้ดได้ ทั้งหมดนี้เพิ่งเปิดตัวได้ราววันเดียว ยังใหม่จนแทบไม่มีใครพูดถึงในไทย
วางแผนงานให้ตัวเองก่อนลงมือ

โมเดลเขียนโค้ดส่วนใหญ่ทำงานแบบเห็นโจทย์แล้วพุ่งเข้าหาคำตอบทันที แต่ Ornith-1.0 ไม่ทำแบบนั้น ทีมผู้สร้างฝึกมันด้วยวิธี reinforcement learning ให้ร่างแผนงานหรือลำดับขั้นตอนที่จะพาไปสู่คำตอบขึ้นมาก่อน แล้วจึงเขียนคำตอบจริงตามแผนนั้น คำว่า scaffold ในชื่อเทคนิคก็มาจากนั่งร้านที่ช่างตั้งขึ้นก่อนจะสร้างตัวอาคารจริงนั่นเอง
ความต่างอยู่ตรงที่โมเดลไม่ได้เรียนสองอย่างนี้แยกกัน ทีมผู้สร้างไม่ได้ฝึกให้มันแยกคิดแผนกับเขียนคำตอบ แต่ฝึกให้ทำสองอย่างนี้ไปพร้อมกัน โดยจะได้รางวัลก็ต่อเมื่อแผนนั้นพาไปสู่โค้ดที่ใช้งานได้จริง พอฝึกแบบนี้ โมเดลจึงค่อยๆ ค้นเจอวิธีแก้ปัญหาที่ดีกว่า และให้คำตอบที่มีคุณภาพสูงกว่าการเดาคำตอบตรงๆ
ถ้าลองใช้จริงจะเห็นภาพชัดขึ้น รุ่น 9B เป็นโมเดลสายให้เหตุผล (reasoning model) ที่ก่อนจะตอบอะไรออกมา จะแสดงบล็อก <think>...</think> ซึ่งเป็นกระบวนการคิดของตัวเองออกมาก่อนเสมอ แล้วส่งส่วนความคิด (chain-of-thought) นี้กลับมาแยกจากคำตอบสุดท้าย ทำให้เห็นได้ว่ามันวางแผนมายังไงกว่าจะกลายเป็นโค้ดที่ส่งกลับมา
ความเก่งของมันไม่ได้อยู่ที่ตอบเร็ว แต่อยู่ที่วางแผนงานให้ตัวเองเป็นก่อนจะลงมือ
มีให้เลือกสี่ไซซ์ รันเองควรเริ่มที่ตัวไหน
Ornith-1.0 ไม่ได้มาตัวเดียว แต่มาเป็นชุดสี่ขนาดให้เลือกตามแรงเครื่องและงานที่ต้องการ ทุกตัวต่อยอด (post-train) มาจากโมเดลพื้นฐานอย่าง Gemma 4 และ Qwen 3.5 ซึ่งทั้งคู่ใช้ไลเซนส์ Apache 2.0 จึงไม่ติดเงื่อนไขการใช้งานที่เคยเป็นปัญหาในโมเดลบางรุ่นก่อนหน้านี้
- 9B Dense · รุ่นเล็กสุด เหมาะกับคนที่อยากรันในเครื่องตัวเอง ขนาดไฟล์เต็มราว 19 GB และยังมีเวอร์ชัน GGUF ที่บีบให้เล็กลงเพื่อรันบนเครื่องทั่วไปได้
- 31B Dense · รุ่นกลางค่อนใหญ่ ต้องการเครื่องแรงขึ้น แลกกับคุณภาพคำตอบที่สูงขึ้น
- 35B MoE · รุ่นแบบ Mixture-of-Experts ที่เรียกใช้เฉพาะส่วนจำเป็นต่อแต่ละงาน ทำให้รันเบากว่าขนาดที่เห็น ไฟล์ GGUF แบบบีบอัดเหลือราว 20 GB พอจะรันบนเครื่องเดสก์ท็อปแรงๆ ได้
- 397B MoE · รุ่นยักษ์สำหรับงานระดับเซิร์ฟเวอร์ ไม่ใช่สำหรับรันในเครื่องส่วนตัว
ถ้าเป้าหมายคือรันเองในเครื่องโดยไม่จ่ายค่าโทเคน เริ่มที่ 9B แบบ GGUF ตรงโจทย์ที่สุด เพราะเล็ก โหลดง่าย และแรงพอสำหรับงานเขียนโค้ดทั่วไป ส่วนรุ่นใหญ่ขึ้นไปค่อยขยับเมื่อมีการ์ดจอแรงพอหรือย้ายขึ้นเซิร์ฟเวอร์ รุ่น 9B ยังมาพร้อม context window ขนาด 262,144 โทเคน (ราว 256K) มากพอจะป้อนโค้ดทั้งโปรเจกต์เข้าไปให้มันอ่านพร้อมกันได้
เก่งแค่ไหน และตรงไหนที่ต้องเผื่อใจ
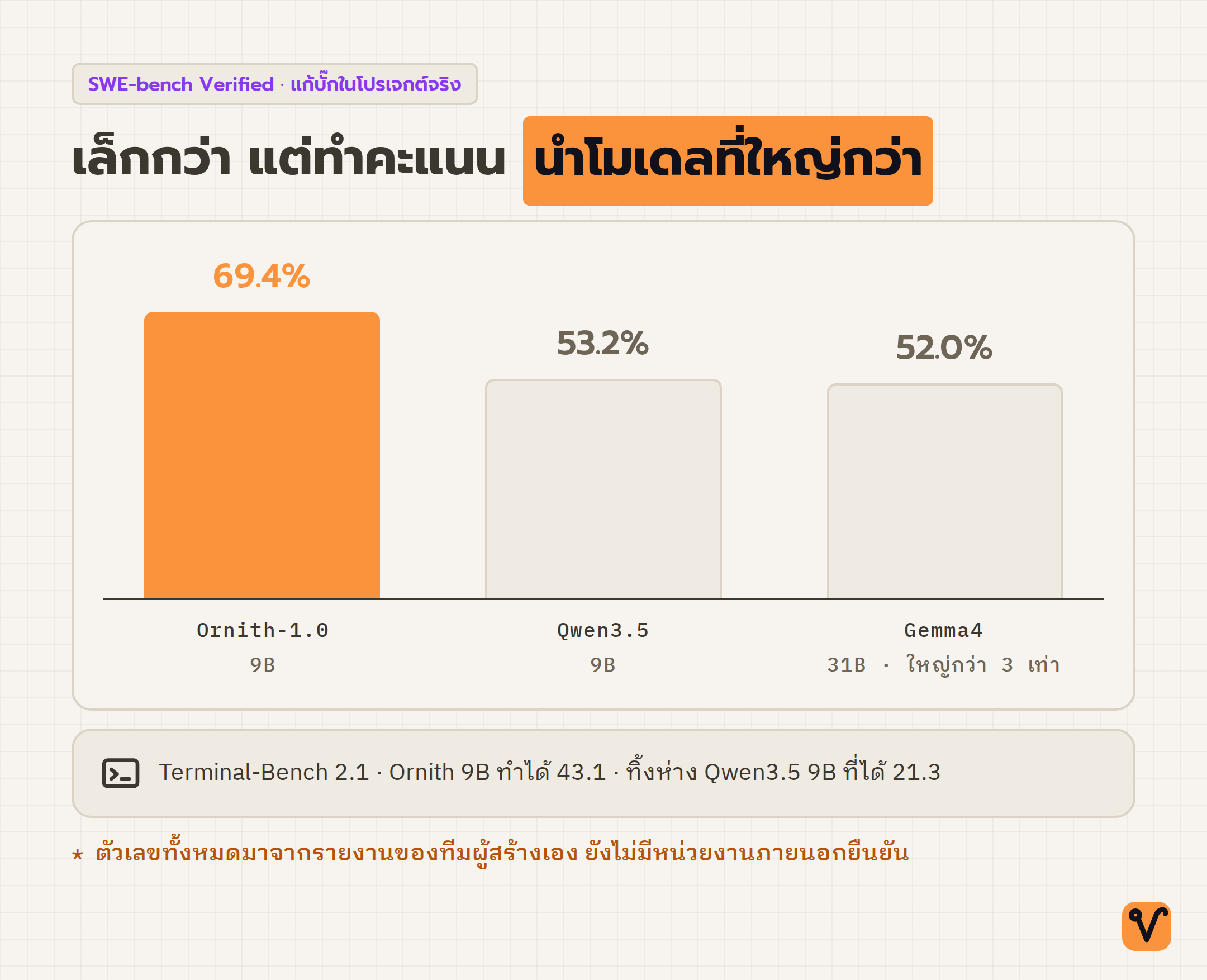
ตัวเลขที่น่าสะดุดตาที่สุดคือรุ่นเล็ก 9B ทำคะแนนเบนช์มาร์กด้านเขียนโค้ดได้สูงกว่าโมเดลที่ใหญ่กว่าตัวเองหลายตัว ในชุดทดสอบ SWE-bench Verified ที่วัดการแก้บั๊กในโปรเจกต์จริง 9B ทำได้ 69.4% ขณะที่ Qwen3.5 รุ่น 9B เท่ากันทำได้ 53.2% และ Gemma4 รุ่น 31B ที่ใหญ่กว่าสามเท่ายังได้แค่ 52% ส่วนชุด Terminal-Bench 2.1 ที่จำลองการสั่งงานผ่านเทอร์มินัล 9B ก็ทำได้ 43.1 ทิ้งห่างรุ่น 9B ของ Qwen3.5 ที่ได้ 21.3 เกือบเท่าตัว
แต่ตรงนี้ต้องเผื่อใจไว้นิดหนึ่ง เพราะตัวเลขเบนช์มาร์กทั้งหมดนี้ทีม DeepReinforce รายงานเอง ยังไม่มีหน่วยงานภายนอกมายืนยันอย่างเป็นทางการ และแต่ละชุดทดสอบก็ใช้เงื่อนไขต่างกัน การจะเอาไปเทียบกันตรงๆ จึงต้องอ่านเงื่อนไขประกอบเสมอ
เสียงจากคนนอกที่ได้ลองของจริงก็ออกมาดี นักพัฒนาอิสระ Simon Willison ทดลองรันรุ่น 35B บนเครื่องตัวเองผ่าน LM Studio แล้วให้ความเห็นว่าความรู้สึกแรกดีมาก มันสั่งงานผ่านเครื่องมือ (tool calls) หลายต่อหลายรอบได้อย่างคล่องแคล่ว เขายังลองให้มันไปไล่หาโค้ดในโปรเจกต์จริง ทั้งส่วนที่ถอดข้อมูลในคุกกี้ และโค้ดที่เปิดหน้าต่างขึ้นมาตอนกดปุ่ม ซึ่งมันจัดการได้สบายๆ ส่วนความสนใจก็มาไว หน้าโมเดลแสดงยอดดาวน์โหลดในเดือนล่าสุดอยู่ที่ราว 26,000 ครั้ง ทั้งที่เพิ่งเปิดตัวได้ไม่นาน
เริ่มลองในเครื่องตัวเองวันนี้
ข้อดีของโมเดลเปิดคือไม่ต้องสมัครหรือรอคิวอะไร โหลดมารันได้เลย ทุกไฟล์อยู่บนหน้า Ornith-1.0 บน Hugging Face และถ้าจะรันในเครื่องตัวเองให้มองหาเวอร์ชัน Ornith-1.0-9B GGUF ที่บีบขนาดมาให้รันบนเครื่องทั่วไปได้
วิธีที่ง่ายที่สุดสำหรับมือใหม่คือใช้ Ollama ติดตั้งโปรแกรมแล้วพิมพ์คำสั่งเดียว:
ollama run hf.co/deepreinforce-ai/Ornith-1.0-9B-GGUFแค่นี้ก็คุยกับมันได้เลย ไม่ต้องตั้งค่าอะไรเพิ่ม ถ้าชอบแบบมีหน้าจอคลิกง่ายๆ LM Studio เป็นอีกทางที่เปิดไฟล์ GGUF มารันได้ตรงๆ เหมาะกับคนที่ไม่อยากแตะคอมมานด์ไลน์ ส่วนสายที่อยากปรับแต่งลึกหรือรันเป็นเซิร์ฟเวอร์ก็มี llama.cpp ให้เลือก ทีมผู้สร้างแนะนำค่า sampling ที่ temperature 0.6, top_p 0.95 และ top_k 20 เพื่อให้ได้ผลที่ดีที่สุด
ถ้าอยากให้มันทำงานแบบ agentic coding จริงๆ คือปล่อยให้มันไล่อ่านโค้ด แก้ไฟล์ และรันคำสั่งเป็นขั้นๆ เอง คุณต่อมันเข้ากับ agent harness อย่าง OpenHands ได้ทันที เพราะ Ornith-1.0 มี API ที่เข้ากันได้กับมาตรฐานของ OpenAI (เรียกผ่าน /v1/chat/completions) และรองรับการเรียกใช้เครื่องมือ (tool calling) มาในตัวอยู่แล้ว
สรุปลำดับเริ่มต้นแบบเร็วๆ สำหรับรุ่น 9B:
- ติดตั้ง Ollama ลงในเครื่อง
- รัน
ollama run hf.co/deepreinforce-ai/Ornith-1.0-9B-GGUFแล้วรอโหลดโมเดลรอบแรกให้เสร็จ - พิมพ์โจทย์เขียนโค้ดเข้าไปคุยได้เลย หรือต่อเข้า OpenHands ถ้าจะให้มันลงมือทำงานเองทั้งกระบวนการ
เมื่อก่อน โมเดลที่ฉลาดพอจะวางแผนงานเขียนโค้ดให้ตัวเองได้มักซ่อนอยู่หลังบริการที่คิดเงินตามจำนวนโทเคน แต่ความเปลี่ยนแปลงที่ Ornith-1.0 ทำให้เห็น ไม่ใช่ว่ามันฉลาดกว่าทุกตัวในตลาด แต่คือความสามารถแบบนั้นมาอยู่ในเครื่องเราในรูปไฟล์ได้แล้ว คำถามจึงไม่ใช่ "เดือนนี้จ่ายค่า AI ไปเท่าไร" อีกต่อไป แต่เป็น "จะเอาเครื่องที่มีอยู่ไปลองอะไรก่อนดี"
ที่มา:
- model card Ornith-1.0 (deepreinforce-ai) จาก Hugging Face
- บทความ Ornith-1.0: Self-Scaffolding LLMs for Agentic Coding จาก Simon Willison



