AI เขียนโค้ดเร็วขึ้น 10 เท่า แล้วอะไรจะพังก่อน? วิศวกร Google ขึ้นเวที I/O ชี้ว่าสิ่งที่พังไม่ใช่โค้ด แต่คือทั้งระบบรอบๆ และทางรอดคือมองให้เป็นระบบนิเวศ
Adam Bender วิศวกรของ Google และผู้ร่วมเขียนหนังสือ Software Engineering at Google ขึ้นเวที Google I/O เพื่อชี้ว่า AI ทำให้ "เครื่องผลิตโค้ด" เร็วขึ้นหลายเท่า แต่สิ่งที่จะพังก่อนไม่ใช่การเขียนโค้ด มันคือทุกอย่างรอบๆ โค้ด ทั้ง code review ที่กลายเป็นคอขวด เทสต์ที่โตแบบยกกำลังสอง version control ที่ scale ไม่ทัน และ API ภายในที่กลายเป็นเหมือน public ทันที บทความนี้สรุปทอล์กทั้งคลิปเป็นภาษาไทย พร้อมแกนคิดสำคัญที่ว่า AI เป็นเครื่องขยาย ไม่ใช่ทิศทาง

งานของนักพัฒนาในปี 2026 ไม่เหมือนภาพที่หลายคนวาดไว้เมื่อปี 2020 และ AI coding ก็เร่งความเปลี่ยนแปลงนี้ให้มาถึงเร็วกว่าที่คิด ในทอล์ก Software Engineering at the Tipping Point บนเวที Google I/O ที่เผยแพร่ผ่านช่อง Google for Developers Adam Bender วิศวกรของ Google และหนึ่งในผู้ร่วมเขียนหนังสือ Software Engineering at Google วางกรอบคิดที่หลายคนมองข้าม: AI ทำให้ "เครื่องผลิตโค้ด" เร็วขึ้นหลายเท่าก็จริง แต่สิ่งที่จะพังก่อนไม่ใช่การเขียนโค้ดเอง แต่เป็นทุกอย่างที่อยู่รอบๆ โค้ด ทั้งการรีวิว เทสต์ ระบบเก็บเวอร์ชัน การปล่อยซอฟต์แวร์ และตัวคน บทความนี้สรุปเนื้อหาทั้งคลิปเป็นภาษาไทย เพื่อให้นักพัฒนา ทีมลีด และผู้นำสายเทคที่ทีมเริ่มใช้ AI เห็นภาพว่า ทำไมการมองซอฟต์แวร์เป็น "ระบบนิเวศทั้งผืนป่า" จึงสำคัญกว่าการมองเป็น "ต้นไม้ทีละต้น"
งานปี 2026 ไม่เหมือนที่ปี 2020 คิด และ "software ecology" คือเลนส์ที่ใช้มองช่วงนี้
Adam Bender เปิดทอล์กด้วยศัพท์ที่คนส่วนใหญ่ไม่คุ้น: software ecology (นิเวศวิทยาของซอฟต์แวร์) เขานิยามว่าเป็น "การศึกษาแบบองค์รวมของระบบนิเวศเชิงสังคม-เทคนิคที่ผลิตซอฟต์แวร์ออกมา" พูดให้เข้าใจง่าย ซอฟต์แวร์ไม่ได้เกิดจากโค้ดอย่างเดียว แต่เกิดจาก "คน + เครื่องมือ + วัฒนธรรม" ที่ทำงานพันกันเป็นระบบ สำหรับ Adam นี่คือเลนส์ที่ดีที่สุดในการมองหัวเลี้ยวหัวต่อที่อุตสาหกรรมกำลังเจออยู่
ก่อนจะไปไกล Adam ให้ภาพพื้นฐานของคำว่า "ระบบ (system)" ด้วยตัวอย่างที่จับต้องได้อย่างเครื่องปรับอากาศ ระบบนี้มีเทอร์โมสตัทที่รู้ว่าอุณหภูมิควรเป็นเท่าไร ตัวเครื่องที่ปรับร้อนปรับเย็น และห้องที่ระบบควบคุมอยู่ ทั้งสามส่วนทำงานเชื่อมกันจนกลายเป็นองค์รวม จากนั้นเขาขยับไปสู่คำว่า ecosystem (ระบบนิเวศ) ซึ่งเป็นระบบชนิดพิเศษ: เครือข่ายของผู้เล่นที่พึ่งพากันและวิวัฒน์ไปพร้อมสภาพแวดล้อม มีพฤติกรรมที่ "โผล่ขึ้นมาเอง" และกระจายอำนาจการตัดสินใจ ตามที่ Adam ชี้ สภาพแวดล้อมการพัฒนาภายในของแต่ละองค์กรก็คือระบบนิเวศแบบหนึ่ง เพราะมีทั้งเครื่องมือ บริการ คนที่มีความเห็นและงานที่อยากทำให้เสร็จ รวมถึงข้อจำกัดทางธุรกิจปนอยู่ด้วยกัน
Note: Adam เรียกระบบที่ทำจาก "คน + เทคโนโลยี" ปนกันว่า socio-technical system ซึ่งเขาบอกว่าซับซ้อนเป็นพิเศษ เพราะเริ่มจากเทคโนโลยีที่ซับซ้อนอยู่แล้ว พอเติมคนที่มีความคิดความรู้สึกเข้าไปก็ยิ่งซับซ้อนขึ้นไปอีก
ในระบบ ทุกอย่างเชื่อมโยงกัน และ Conway's Law ก็พิสูจน์เรื่องนี้
ประโยคที่ Adam ย้ำหลายรอบตลอดทอล์กคือ "ในระบบ ทุกอย่างเชื่อมโยงกันหมด" เพื่อให้เห็นภาพ เขาหยิบ Conway's Law ขึ้นมาอธิบายว่า "องค์กรมักสร้างเทคโนโลยีที่สะท้อนโครงสร้างการสื่อสารภายในของตัวเอง" ตัวอย่างแบบติดตลกคือ ถ้ามีทีมสี่ทีมช่วยกันทำคอมไพเลอร์ ผลที่ได้ก็มักออกมาเป็นคอมไพเลอร์สี่พาส แก่นของเรื่องนี้คือ วิธีที่เราสร้างเทคโนโลยีแยกไม่ออกจากโครงสร้างขององค์กรที่สร้างมัน
ที่สำคัญกว่านั้น Adam ชี้ว่าไม่ใช่แค่โครงสร้างองค์กรที่ฝังตัวลงไปในของที่สร้าง แต่ "ค่านิยมและวัฒนธรรม" ขององค์กรก็ฝังลงไปด้วย เพราะระบบนิเวศจะสร้างสิ่งที่องค์กรให้รางวัล ทีมจึงผลิตงานแบบที่วัฒนธรรมของตัวเองสนับสนุน เมื่อเข้าใจมุมนี้ Adam บอกว่าจะเริ่มเห็น socio-technical system อยู่ทุกที่ในงานพัฒนา ตั้งแต่สถาปัตยกรรมของระบบ วัฒนธรรมการทำ postmortem (การทบทวนหลังเกิดปัญหา) ไปจนถึง code review (การตรวจทานโค้ดของเพื่อนร่วมทีม) และนโยบายความปลอดภัย
บทเรียนจากระบบนิเวศของ Google และคำเตือนว่า "อย่าก๊อปปี้ Google"
เพื่อให้แนวคิดที่ค่อนข้างนามธรรมจับต้องได้ Adam ยกตัวอย่างจากระบบนิเวศนักพัฒนาของ Google ซึ่งเป็นพื้นที่ที่เขารู้จักดีที่สุด แต่เขาย้ำคำเตือนตั้งแต่ต้นว่าอย่าลอก Google ไปใช้ตรงๆ เพราะแต่ละบริษัทอยู่คนละจุดและมี trade-off (สิ่งที่ต้องแลกกัน) ต่างกัน เขาเล่าว่าเมื่อหลายปีก่อน ทีมของเขาเขียนหนังสือ Software Engineering at Google ขึ้นมา ภายในเรียกกันเล่นๆ ว่า "Flamingo Book" และครึ่งแรกของหนังสือพูดเรื่องวัฒนธรรมวิศวกรรมทั้งหมด ไม่ใช่เรื่องเทคนิค เหตุผลตามที่ Adam อธิบายคือ ถ้าไม่เข้าใจวัฒนธรรมของ Google ก็จะไม่เข้าใจว่าทำไมถึงเลือกทางเทคนิคแบบนั้น สองอย่างนี้พันกันจนแยกไม่ออก
ในฝั่งเทคนิค Adam เล่าว่า Google ใช้ monorepo (การเก็บโค้ดเกือบทั้งบริษัทไว้ในที่เดียว) และทำงานแบบ trunk-based คือทุก change ลงที่จุดเดียวกัน ไม่มี branch ไม่มีเวอร์ชันแยก อีกอย่างคือแพลตฟอร์มเทสต์กลางที่เขาบอกว่ารันเทสต์หลัก "พันล้านครั้งต่อวัน" จากนั้นเขาหยิบหลักการหนึ่งที่คอยนำทาง Google โดยปริยายขึ้นมา นั่นคือ shared fate (ชะตาร่วม) หรือระดับที่ระบบนิเวศกับชิ้นส่วนของมันผูกชะตากันแน่นแค่ไหน Adam ยกพลังของ monorepo ว่า การแก้โค้ดเพียง 10 บรรทัดในจุดที่ถูกต้องสามารถ patch ความปลอดภัยให้แอปทั้งบริษัทภายในหนึ่งสัปดาห์ หรือพูดอีกแบบคือ "10 บรรทัด patch โค้ดได้หมื่นล้านบรรทัด"
แต่ Adam ย้ำว่า shared fate ไม่ได้ดีเสมอไป เพราะในระบบ production เราไม่อยากให้บริการตัวเดียวล้มแล้วลากทั้งระบบล้มตาม (cascading failure หรือความล้มเหลวที่ลามต่อกันเป็นทอด) Google จึงทำงานหนักมากเพื่อตัด shared fate ชนิดอันตรายออกไป สรุปคือ shared fate เป็น trade-off ที่ต้องเลือกวางให้ถูกที่ ส่วนความสามารถอย่าง Large Scale Changes หรือ LSC ที่ Google ทำได้—ให้นักพัฒนาคนเดียวแก้โค้ดทีละหลายล้านบรรทัด—ก็ไม่ได้เกิดจากเครื่องมือตัวใดตัวหนึ่ง แต่เกิดจาก "ทั้งระบบนิเวศ" ที่ประกอบกัน ทั้งวัฒนธรรมการเขียนเทสต์ทั้งบริษัท แพลตฟอร์มเทสต์กลาง build tool ร่วม และความโปร่งใสของ monorepo ตามที่ Adam สรุปไว้ ไม่มีใครชี้ไปที่จุดเดียวแล้วบอกว่า "นี่คือเหตุผล" ได้ เพราะมันคือทุกอย่างที่พันกัน
คำถาม "code red" ถ้าระบบต้องโต 10-15 เท่าใน 18 เดือน อะไรจะพังก่อน?
หลังวางพื้นเรื่องระบบนิเวศแล้ว Adam ก็มาถึงคำถามที่เขาบอกว่าทุกคนต้องตอบให้ได้เร็วๆ นี้: "ถ้าระบบนิเวศนักพัฒนาของคุณต้องโตขึ้น 10-15 เท่าภายใน 18 เดือน คุณรู้ไหมว่าอะไรจะพังก่อน?" เขาชี้ว่านี่ไม่ใช่แบบฝึกคิดอีกต่อไป แต่เป็น "code red moment" หรือช่วงเวลาฉุกเฉินที่ทุกบริษัทต้องเจอ เพราะระบบนิเวศการพัฒนาทุกที่บนโลกกำลังเปลี่ยนถึงราก เรื่องนี้ยากขึ้นไปอีก เพราะเราไม่มีทางสร้างระบบใหม่จากศูนย์ (greenfield) ได้ แต่ต้องเปลี่ยนทุกชิ้นส่วนระหว่างที่ยังส่งงานให้ลูกค้า โดยไม่ทำให้อะไรพัง
ประเด็นที่ Adam ย้ำหนักที่สุดในช่วงนี้คือความต่างระหว่าง "การสร้างโค้ด (generating code) เร็วขึ้น 10 เท่า" กับ "การทำวิศวกรรม (engineering) เร็วขึ้น 10 เท่า" เขาบอกว่าสองอย่างนี้เป็นคนละเรื่องกัน ที่ Google มักพูดกันว่า engineering คือ "การเขียนโปรแกรมที่อินทิเกรตข้ามเวลา" หมายถึงไม่ใช่แค่เขียนโค้ดให้รันได้วันนี้ แต่รวมถึงการดูแลรักษามันไปอีกหลายปี ตามที่ Adam อธิบาย สิ่งที่ AI กำลังเร่งให้เร็วขึ้นคือ "เครื่องผลิตโค้ด" เท่านั้น โจทย์ที่เหลือจึงเป็นการทำวิศวกรรมรอบๆ เครื่องนั้นให้ทัน และเขาก็พูดตรงๆ ว่า "สิ่งที่เราทำกันอยู่ทุกวันนี้ มันไม่เวิร์กที่ 10 เท่า ผมพนันด้วยเงินก้อนโตได้เลย"
หัวใจของทอล์ก คูณ 10 เข้าไปทุก node แล้วถามว่า "ดีขึ้นหรือพัง?"
นี่คือส่วนที่ใช้ได้จริงที่สุดของทอล์ก Adam ชวนมองระบบนิเวศการพัฒนาเป็น flow ง่ายๆ ตั้งแต่การเขียน source code ไป build ไป code review ไป test ไป version control แล้วต่อด้วย release และ rollback จากนั้นเขาเดินไล่ทีละ node แล้วถามคำถามเดียวกันทุกจุดว่า ถ้า node นี้ต้องทำงานมากขึ้น 10 เท่า มันจะดีขึ้นหรือพัง ผลที่ได้คือพังแทบทุกจุด
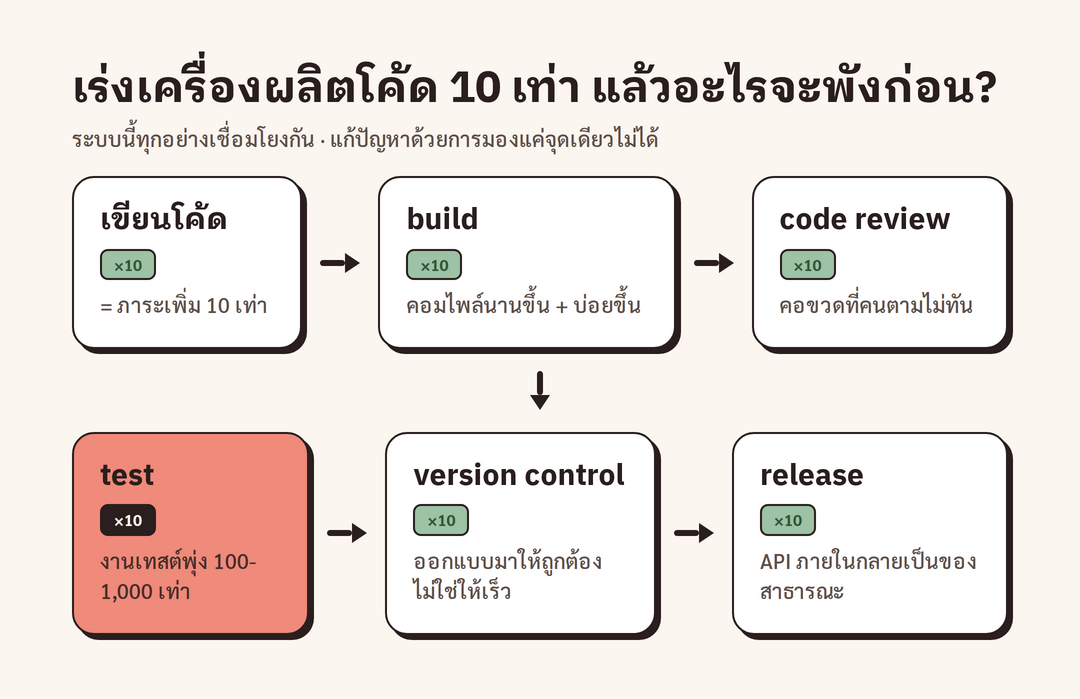
เริ่มจากการเขียนโค้ด ตามที่ Adam ชี้ ถ้าทุกคนเขียนโค้ดเร็วขึ้นมาก ก็จะมีโค้ดมากขึ้น 10 เท่า เขาเตือนความจำด้วยคำคลาสสิกของ Jeff Atwood ที่ว่า "software is a liability" หรือซอฟต์แวร์คือภาระ ไม่ใช่ทรัพย์สิน ดังนั้นโค้ดที่เพิ่มขึ้น 10 เท่าจึงแปลว่าภาระเพิ่มขึ้น 10 เท่าตั้งแต่ต้นทาง ถัดมาคือ build system ที่ Adam บอกว่า เมื่อโค้ดเยอะขึ้นก็ใช้เวลา compile นานขึ้น และเมื่อ agent (ตัวช่วยอัตโนมัติ) เป็นคนสั่ง build มันก็สั่งบ่อยขึ้นด้วย กลายเป็นทั้ง "ใหญ่ขึ้น" และ "บ่อยขึ้น" พร้อมกัน ส่วนเรื่องขนาด binary นั้น Adam เล่าว่า Google ชนเพดานนี้มาแล้วในบางจุด คือบาง binary ใหญ่จนคอมไพล์ไม่ได้ ถ้าเป็นสายที่ทำ microservice ก็หนีไม่พ้นเช่นกัน เพราะบริการมากขึ้น 10 เท่าก็แปลว่า traffic ในเครือข่ายมากขึ้น 10 เท่า ตามที่เขาสรุปว่า "ไม่มีใครรอดจาก scale ได้ มันมีผลทุกที่"
จุดที่ Adam ให้น้ำหนักมากคือ code review ซึ่งกลายเป็นคอขวดของคน เพราะโค้ดมากขึ้น 10 เท่าแปลว่า change ใหญ่ขึ้น 10 เท่าหรือเยอะขึ้น 10 เท่า tech lead จึงรีวิวไม่ทันแน่นอน เขาตั้งข้อสังเกตว่า "คนไม่ชอบเป็นคอขวด พอโดนกดดันก็จะเริ่มตัดมุม" หรือหาทางลัดเพื่อไม่ให้ตัวเองไปขวางใคร ต่อให้เอา AI มาช่วยรีวิวได้บางส่วน Adam ก็ชี้ปัญหาที่ลึกกว่านั้นว่า ถ้าคนในทีมไม่ได้เขียนโค้ดเองอีกแล้ว พวกเขาจะเจอโค้ดแค่ตอนรีวิว และตอนรีวิวก็ไม่ได้ตั้งใจอ่านเท่าตอนเขียนเอง สุดท้ายจึงนำไปสู่สภาพที่เขาเตือนว่า "ไม่มีใครเข้าใจ codebase อีกต่อไป มันจะกลายเป็นกองที่ไม่มีใครเข้าใจ"
เรื่อง testing และ version control นั้น Adam แยกออกมาพูดเป็นพิเศษ ในฝั่งเทสต์ เขาชี้ว่า agent ชอบรันเทสต์มาก เพราะเทสต์เป็นตัวบอก agent ว่าทำงานถูกหรือยัง เขายกข้อมูลจาก Google ว่ากราฟความเชื่อมโยงของโค้ด หรือ dependency graph โตแบบ "ยกกำลังสอง (quadratic)" ไม่ใช่แบบเชิงเส้น เมื่อเทียบกับขนาดของ codebase พูดง่ายๆ คือ codebase ที่ใหญ่ขึ้น 10 เท่า อาจต้องรันเทสต์มากถึง 100 เท่า หรือถึง 1,000 เท่า ซึ่งจะกลายเป็นต้นทุนก้อนใหญ่ในงบประมาณ Adam ถึงกับบอกว่า "ถ้าคุณไม่กังวลเรื่องค่า test compute ผมยิ่งกังวลแทน เพราะนั่นแปลว่าคุณมีเทสต์น้อยเกินไป และ agent กำลังไล่แก้ทั่ว codebase โดยไม่รู้ว่าอะไรเวิร์ก" ส่วน version control นั้น Adam ชี้ว่าระบบส่วนใหญ่ออกแบบมาเพื่อความถูกต้องและลำดับที่แม่นยำ ไม่ใช่เพื่อความเร็ว จึง scale ตามความเร็วระดับ 10 เท่าไม่ทัน เขาถามแบบกระแทกว่า "ระบบของคุณรับได้กี่ commit ต่อนาที น้อยกว่าที่คิดแน่นอน" และเตือนว่าทางออกแบบซอยเป็น repo เล็กๆ นับพันตัวไม่ได้ง่ายขึ้นเพราะ AI แต่กลับเป็นปัญหาชุดใหม่ทั้งชุด
ยังมีจุดที่ลึกและคาดไม่ถึงอีกหลายเรื่องที่ Adam ไล่ให้ดู หนึ่งในเรื่องสำคัญมากคือ API ภายใน เขาเล่าว่าได้บอกเพื่อนร่วมงานว่า "API ภายในทุกตัวของคุณ เพิ่งกลายเป็น public ไปแล้ว" และต้องทำให้แข็งแรงเหมือน API ที่เปิดออกสู่อินเทอร์เน็ตสาธารณะ เหตุผลตามที่ Adam อธิบายคือ "agent ไม่ต่อรองกับคุณ มันจะหา API เจอแล้วเรียกเลย ถ้ามันเข้าถึงข้อมูลได้ มันก็จะเอา" ในเรื่อง release Adam ชี้ว่าการปล่อยซอฟต์แวร์ถี่ขึ้นเป็นเรื่องดีที่ DORA สนับสนุน แต่ก็มีจุดที่ผลตอบแทนเริ่มลดลง และถ้าปล่อยไม่ถี่พอ change แต่ละก้อนก็จะใหญ่ขึ้นจนน่ากลัว ส่วนเรื่อง rollback (การย้อนกลับไปเวอร์ชันก่อนเมื่อเจอปัญหา) Adam อธิบายว่า rollback ยังใช้ได้ทุกวันนี้ เพราะเราปล่อยซอฟต์แวร์ช้ากว่าเวลาที่ใช้ตรวจเจอปัญหาอยู่นิดหน่อย แต่ถ้าปล่อยเร็วกว่าที่จะตรวจเจอ ทุก rollback ก็ต้องไปสู้กับ change ที่ขัดกันหลายตัวที่ลงมาทับ
สุดท้าย Adam ปิดส่วนนี้ด้วยเรื่อง "คน" ที่เขาบอกว่าน่ากังวลที่สุด เริ่มจากสิ่งที่เขาเรียกว่า "การลัดขั้นเป็นผู้นำเชิงเทคนิค" ของจูเนียร์ ตามปกติ การจะเป็นทีมลีดได้ต้องใช้เวลาสั่งสมสัญชาตญาณและวิจารณญาณ เพราะการนำทีมมีผลกระทบเป็นวงกว้างกว่าการลงมือทำเอง แต่ Adam ตั้งคำถามว่า เด็กจบใหม่ที่มี agent อยู่ในมือ 50 ตัวแต่ยังไม่มีวิจารณญาณเลย จะเกิดอะไรขึ้น เขายอมรับตรงๆ ว่า "ผมจะสอนประสบการณ์ 10 ปีให้ได้ใน 6 เดือนยังไง ผมก็ยังไม่รู้" อีกเรื่องที่เขาเน้นคือ ความสนใจของมนุษย์ (human attention) ซึ่งกลายเป็นทรัพยากรล้ำค่าที่สุด เพราะเมื่อมี agent เยอะ ก็มีเสียงรบกวนเยอะที่คอยแย่งความสนใจ ตามที่ Adam สรุปไว้ "เมื่อก่อนเราได้ประโยชน์จากข้อจำกัดที่ว่า เราสร้างปัญหาให้ตัวเองได้ไม่เกินกว่าที่เราจะดูแลไหว แต่ตอนนี้ไม่ใช่แบบนั้นแล้ว"
Warning: ข้อสรุปสำคัญของส่วนนี้ตามที่ Adam ย้ำคือ ปัญหาทั้งหมดข้างต้นแก้ไม่ได้ด้วยการมองแค่ node เดียวในระบบ เพราะในระบบทุกอย่างเชื่อมโยงกัน การจะรับมือกับการพัฒนาแบบ agentic จึงต้องเริ่มฝึกคิดเป็นระบบตลอดเวลา
AI เป็น "เครื่องขยาย" ไม่ใช่ "ทิศทาง"
หลังจากไล่ให้เห็นว่าอะไรจะพังบ้าง Adam ก็เข้าสู่แก่นที่ทรงพลังที่สุดของทอล์ก: AI ทำหน้าที่เป็น "เครื่องขยาย (amplifier)" เขาให้เครดิตแนวคิดนี้กับ DORA ทีมที่ทำรายงานเรื่องการพัฒนาด้วย AI ตามที่ Adam เล่า รายงานของ DORA เมื่อปีก่อนพบว่าทีมที่ "เก็ตแล้ว" คือทีมที่ทำให้ AI กลายเป็นเครื่องขยายได้สำเร็จ
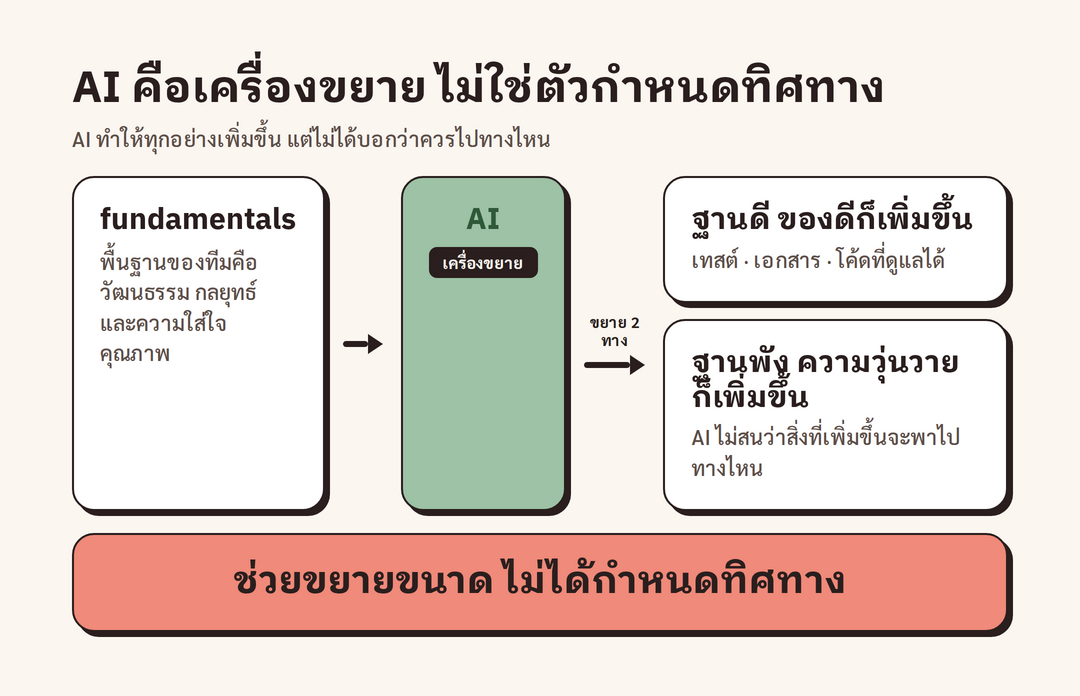
ประโยคที่เป็นหัวใจคือ "การขยายคือเรื่องของขนาด (magnitude) ไม่ใช่ทิศทาง (direction)" ตามที่ Adam อธิบาย AI ให้เรา "มากขึ้น" ได้ทุกอย่าง ทั้งเทสต์มากขึ้น เอกสารมากขึ้น โค้ดมากขึ้น และความสับสนมากขึ้นด้วย เพราะ AI ไม่ได้สนใจว่าของพวกนั้นจะไปทางไหน มันแค่ทำให้มีมากขึ้นเท่านั้น สิ่งที่ DORA พบตามที่ Adam ยกมาคือ ทีมที่มี "พื้นฐาน (fundamentals) ที่ดี" จะนำการขยายนี้ไปในทิศทางที่มีประโยชน์ได้ คำถามจึงย้อนกลับมาที่ทุกทีมว่า "พื้นฐานของคุณเป็นอย่างไร" Adam ลิสต์ตัวอย่างของพื้นฐานที่ควรสำรวจไว้หลายด้าน ทั้งวัฒนธรรมการตัดสินใจ กลยุทธ์เชิงเทคนิค การที่มีใครดูแล developer productivity ไหม การทำงานร่วมกัน ความปลอดภัย สุขภาพของโค้ด และความน่าเชื่อถือของระบบ
ข้อสรุปที่ Adam เน้นย้ำคือ "AI ไม่ได้แก้ปัญหาเหล่านี้ให้คุณโดยอัตโนมัติ มันแค่ขยายสิ่งที่คุณมีอยู่แล้ว ถ้าดีก็ยิ่งดี ถ้าไม่ดีก็ยิ่งสร้างปัญหา" นี่คือเหตุผลว่าทำไมการเร่งให้เขียนโค้ดเร็วขึ้นเพียงอย่างเดียวจึงไม่ใช่คำตอบ เพราะถ้าพื้นฐานยังอ่อน การเร่งความเร็วก็เท่ากับเร่งความวุ่นวายให้มาถึงเร็วขึ้น
ทางเดินต่อ 4 สิ่งที่ต้องลงทุน และความต่างของหลักการกับวิธีปฏิบัติ
เมื่อมาถึงคำถามว่าแล้วต้องทำอะไรต่อ Adam เสนอสี่เรื่องที่ควรลงทุน ควบคู่ไปกับการสร้างพื้นฐานที่ดี
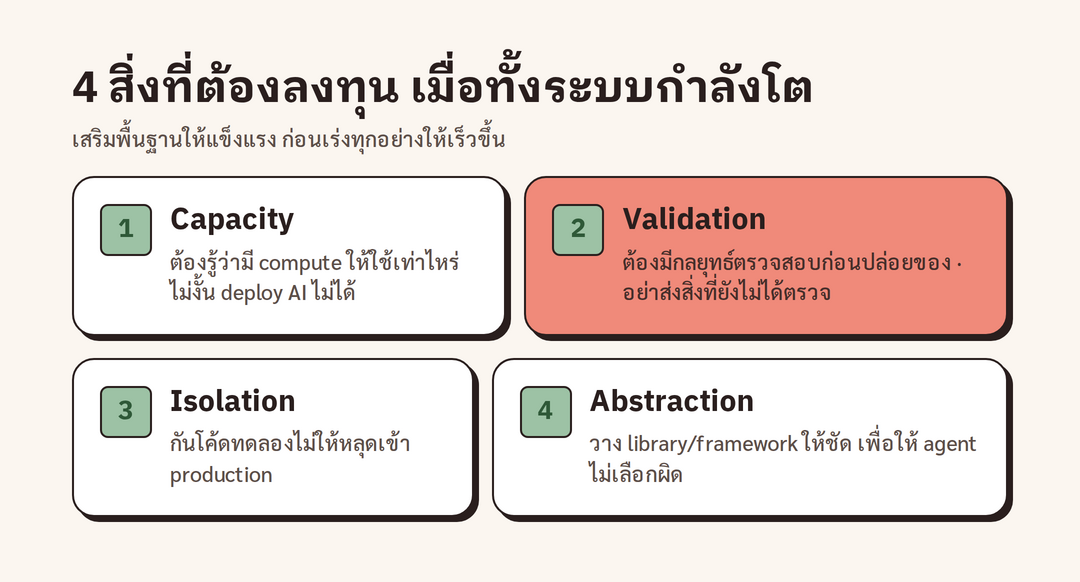
สิ่งแรกคือ infrastructure capacity หรือกำลังของโครงสร้างพื้นฐาน ตามที่ Adam ชี้ ถ้าไม่รู้ว่ามีทรัพยากร compute เท่าไรให้ใช้ ก็จะ deploy AI หรือ compute ไม่ได้ จึงต้องมีวิธีติดตามเรื่องนี้ที่ดี สิ่งที่สองคือ validation หรือการตรวจสอบ เพราะไม่ควรส่งของที่ยังไม่ได้ตรวจสอบ และวิธีตรวจสอบก็กำลังจะเปลี่ยนไป จึงต้องมี "กลยุทธ์ validation" ตั้งแต่ตอนนี้ สิ่งที่สามคือ isolation หรือการแยกส่วน เพราะต่อไปจะมีโค้ดจากหลายวัตถุประสงค์ รวมถึงงานที่เมื่อก่อนไม่ได้ใช้โค้ดเลย Adam เปรียบว่าต้องกันไม่ให้ "โค้ด prototype สนุกๆ" หลุดเข้าไปกระทบส่วนที่ทำเงินจริงใน production สิ่งที่สี่คือ abstraction หรือการวางชั้นนามธรรม ตามที่ Adam อธิบาย เราสร้าง abstraction อย่าง library และ framework ขึ้นมาเพื่อกันไม่ให้คนเลือกผิด และเมื่อให้ agent ตัดสินใจเยอะๆ ก็เจอผลแบบเดียวกัน จึงต้องมี abstraction ดีๆ ให้ agent ยึด หรืออย่างที่เขาบอกว่า "อย่าให้ทางเลือกแย่ๆ กับมัน"
นอกจากสี่สิ่งนี้ Adam ยังเน้นความต่างระหว่าง "หลักการ (principle)" กับ "วิธีปฏิบัติ (practice)" เขาบอกว่าวิธีปฏิบัติเปลี่ยนได้ตลอด สิ่งที่สำคัญจริงคือหลักการที่อยู่เบื้องหลัง ความยากคือบางหลักการดูเผินๆ เหมือนเป็นแค่วิธีปฏิบัติ อย่างเช่นการทำเทสต์ Adam ชี้ว่า "ถ้าคุณไม่เคยถามว่าทำไมทีมถึงเทสต์แบบที่ทำอยู่ หรือทำไม release process ถึงเป็นแบบนี้ คุณก็จะวิวัฒน์มันไม่ได้" เพราะการเข้าใจหลักการจะให้ทั้งพลังและความมั่นใจในการเปลี่ยนแปลง สำหรับวิธีคิดเชิงระบบ Adam บอกว่าจริงๆ แล้วต้องการแค่สองคำถามเท่านั้น ดังตารางด้านล่าง
| คำถาม | บทบาท | ตัวอย่างที่ Adam ยก |
|---|---|---|
| ทำไม (why) | สว่านที่เจาะเข้าไปดูว่าระบบทำงานอย่างไร | "ทำไมเราถึงมี integration test น้อยจัง" |
| จะเป็นอย่างไรถ้า (what if) | ใช้ท้าทายสิ่งที่เจอ และต้องใช้จินตนาการ | "จะเป็นอย่างไรถ้าเรามี integration test มากกว่า unit test" |
ตามที่ Adam สังเกต ทุกคนถาม "ทำไม" กันเก่งอยู่แล้ว แต่ "จะเป็นอย่างไรถ้า" ยากกว่ามาก เพราะมันน่ากลัวตรงที่อาจต้องยอมทิ้งวิธีปฏิบัติที่เคยคิดว่าออกแบบมาดีแล้ว แต่ถ้ายอมเปิดใจ มันก็น่าตื่นเต้นได้เช่นกัน
เรื่องสุดท้ายในส่วนนี้ที่ Adam บอกว่าทำให้เขานอนไม่หลับคือ intellectual control ซึ่งเขานิยามง่ายๆ ว่า "มนุษย์ยังใช้เหตุผลทำความเข้าใจสิ่งที่อยู่ตรงหน้าได้อยู่ไหม" เขายอมรับว่า "เราแพ้สงครามนี้มาอย่างน้อย 15 ปีแล้ว เพราะระบบที่ใหญ่ที่สุดของเราใหญ่เกินกว่าที่ใครจะคิดถึงได้ทั้งหมด" Adam แนะนำแบบฝึกหัดง่ายๆ ว่า ให้ลองกลับไปขอให้ทุกคนในทีมวาดแผนภาพสถาปัตยกรรมของระบบเดียวกัน แล้วดูว่าจะได้ภาพต่างกันกี่แบบ ภาพเหล่านั้นจะพิสูจน์เองว่าเราแพ้สงครามนี้มานานแล้ว แต่จุดที่ Adam ตื่นเต้นคือ AI อ่านข้อมูลก้อนใหญ่ได้ จึงอาจช่วยให้เรามี "แผนที่สถาปัตยกรรมแบบอัปเดตตลอดที่ถามคำถามได้" เช่น ถ้าย้าย capacity จากจุดนี้ไปอีกที่หนึ่งจะเกิดอะไรขึ้น หรือถ้าผู้ใช้โตขึ้น 40% ทันทีจะเป็นอย่างไร วันนี้คำถามแบบนี้แทบทำไม่ได้แม้กับระบบขนาดกลาง ตามที่ Adam สรุป สิ่งที่เขาชอบคือเราไม่ได้โฟกัสแค่การเร่งเครื่องผลิตโค้ด แต่กำลังถามว่าจะเข้าใจสิ่งที่เราสร้างให้ลึกขึ้นได้อย่างไร
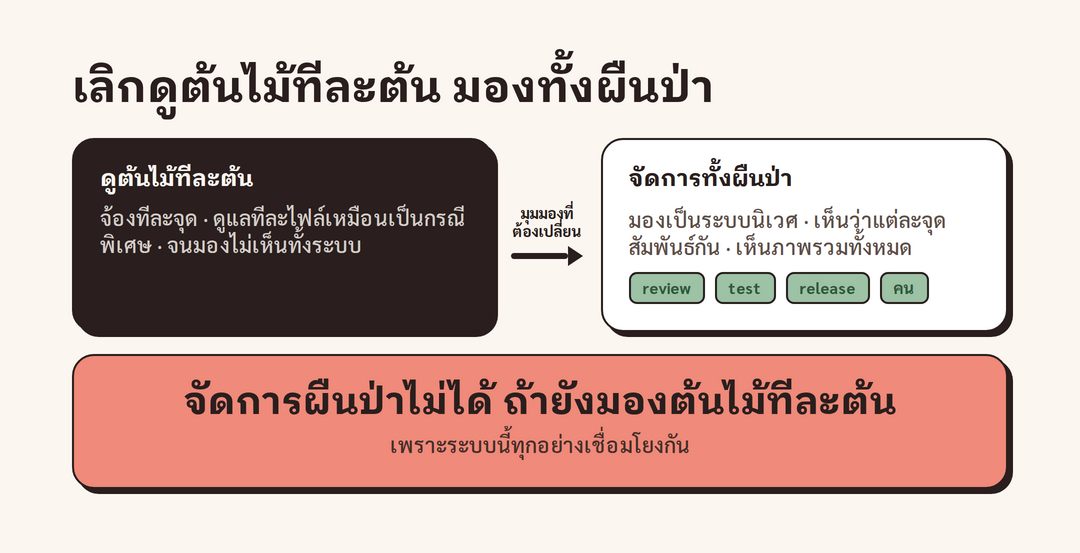
ปิดท้าย มองทั้งผืนป่า ไม่ใช่ต้นไม้ทีละต้น
Adam ปิดทอล์กด้วยภาพเปรียบเทียบที่จับใจ เขาบอกว่าที่ผ่านมาเราคุ้นกับการจ้องดูใบไม้แต่ละใบ กิ่งแต่ละกิ่ง และดูแลต้นไม้แต่ละต้นเหมือนมันเป็นสิ่งพิเศษ แต่อีกไม่นานเราจะไม่ได้ดูแลแค่ "ต้นไม้" อีกต่อไป เราต้องดูแล "ทั้งผืนป่า" ประโยคที่เขาทิ้งท้ายคือ "คุณจัดการผืนป่าด้วยการมองต้นไม้ทีละต้นไม่ได้ คุณต้องมองมันเป็นระบบนิเวศ"
ที่สำคัญ Adam ไม่ได้จบทอล์กด้วยการขู่ให้กลัว AI แต่จบด้วยการให้กำลังใจ เขายอมรับว่าการเปลี่ยนแปลงตอนนี้เกิดขึ้นกับทุกอย่างทุกที่พร้อมกัน จนรู้สึกใหญ่เกินกว่าที่ใครคนเดียวจะมีอิทธิพลได้ แต่เขาก็ย้ำประโยคเดิมที่พูดมาตลอดทอล์กว่า ในระบบทุกอย่างเชื่อมโยงกัน ดังนั้น "การกระทำเล็กๆ ก็มีผลใหญ่ได้" สิ่งที่ Adam แนะนำให้ทำได้เลยคือ ยื่นมือช่วยคนที่ยังตามไม่ทัน วิศวกรอาวุโสควรเป็น mentor หาคนที่ติดแล้วช่วย ถ้าใครเจอ workflow การทำงานกับ AI ที่เวิร์กแล้ว เขาบอกว่า "มันไม่ใช่ความลับล้ำค่า เอาไปแบ่งปันกัน" ส่วนทีมลีดก็ต้องลงมาช่วยกำหนดทิศทาง และถ้าใครแคร์เรื่องคุณภาพหรือดีไซน์ของซอฟต์แวร์ ก็ต้องใช้เสียงของตัวเองผลักดัน เพราะตามที่ Adam บอก คนหน้างานนี่แหละที่จะเป็นคนทำ
ประโยคปิดของ Adam ที่สรุปทั้งทอล์กได้ดีที่สุดคือ การเปลี่ยนผ่านสู่ AI ไม่ใช่เรื่องของผู้นำบริษัทเพียงฝ่ายเดียว แต่วิศวกรหน้างานในช่วงหัวเลี้ยวหัวต่อนี้คือคนที่ตัดสินว่า software engineering จะเป็นอย่างไรต่อไป ตั้งแต่เครื่องมือ workflow ไปจนถึงวิธีปฏิบัติและวัฒนธรรมวิศวกรรม ถ้ามองเห็นระบบที่ทำงานอยู่ ก็จะมองหาจุดที่งัดได้เจอ
Adam Bender ทิ้งท้ายไว้ว่า "คุณมีอำนาจตัดสินใจมากกว่าที่คิด ใช้มันสร้างอนาคตให้องค์กร ทีม และตัวคุณเอง"
เนื้อหาทั้งหมดในบทความนี้สรุปจากทอล์ก Software Engineering at the Tipping Point โดย Adam Bender บนเวที Google I/O เผยแพร่ผ่านช่อง Google for Developers



