/watch: skill ฟรีที่ทำให้ Claude Code ดูวิดีโอความยาว 1 ชั่วโมงจบในไม่กี่นาที ด้วยต้นทุนราว $1
สรุปจากคลิปของช่อง Brad | AI & Automation ที่ปล่อย skill ฟรีบน GitHub ให้ Claude Code ดูวิดีโอ YouTube, Loom, Instagram Reels หรือไฟล์ MP4 ได้ทุกแหล่ง โดยใช้ ffmpeg + caption ฟรี + Whisper บน Groq จนต้นทุนต่อคลิปเหลือราว 1 ดอลลาร์

Claude Code ย่อยวิดีโอความยาว 45 นาทีจาก Y Combinator ที่ Sam Altman เล่าวิธีเริ่มต้น startup ได้ภายในเวลาไม่ถึง 2 นาที พร้อมโครงสรุปผู้พูด หัวข้อหลัก และจังหวะ visual บนสไลด์ครบทุกจุด ทั้งหมดนี้มาจาก skill ตัวเดียวชื่อ /watch ที่ช่อง Brad | AI & Automation ปล่อยให้โหลดฟรีบน GitHub โดยรวมเครื่องมือเก่าแก่อย่าง yt-dlp และ FFmpeg เข้ากับ caption ฟรีของ YouTube และ Whisper ที่รันผ่าน Groq จนต้นทุนต่อคลิปเหลือราว 1 ดอลลาร์ ไม่ว่าวิดีโอจะยาว 30 นาทีหรือ 1 ชั่วโมง
Brad ระบุในคลิปว่าเครื่องมือสรุปวิดีโอที่มีอยู่เดิมมักพลาดอยู่ 2 จุด คือราคาแพงเกินไป หรืออ่านเฉพาะ transcript จนพลาดสิ่งที่เกิดบนหน้าจอไปครึ่งหนึ่ง skill /watch จึงออกแบบมาให้ป้อนทั้ง เฟรมภาพ + เสียงที่ถอดเป็นข้อความ ให้ Claude พร้อมกัน เพื่อให้โมเดล "เห็น" สิ่งที่เกิดบนจอจริง ๆ แทนที่จะเดาจาก subtitle อย่างเดียว
TL;DR: /watch skill ทำอะไรได้บ้าง
- ใส่คำสั่ง
/watch <url>ใน Claude Code แล้วระบบจะดึง subtitle ฟรีของ YouTube + ตัดเฟรมด้วย FFmpeg + ส่งให้ Claude ประมวลผลในครั้งเดียว - รองรับทุกเว็บที่ yt-dlp รองรับ ซึ่ง Brad ระบุว่ามีกว่า 1,000 เว็บ ครอบคลุม YouTube, Loom, Instagram Reels รวมถึงไฟล์วิดีโอที่ดาวน์โหลดมาเก็บไว้ในเครื่อง
- จำกัดจำนวนเฟรมไว้ที่ 100 เฟรมสำหรับวิดีโอที่ยาวเกิน 30 นาที ทำให้ต้นทุนต่อคลิปอยู่ที่ราว 1 ดอลลาร์ไม่ว่าวิดีโอจะยาวเท่าไร
- ถ้าวิดีโอไม่มี subtitle ระบบจะ fallback ไปใช้ Whisper บน Groq ซึ่ง Brad ชี้ว่า free tier ของ Groq ให้โควต้าถอดเสียง 2 ชั่วโมงต่อชั่วโมง เพียงพอสำหรับการใช้รายวัน
- ใช้คู่กับ flag
start,end, และzoomเพื่อโฟกัสเฉพาะช่วง 10 วินาทีในวิดีโอ 2 ชั่วโมงได้ โดยไม่ต้องเผา context window ทิ้ง
Note: ตัว skill เปิดให้โหลดฟรีบน GitHub โดย Brad ฝากลิงก์ติดตั้งไว้ในคำอธิบายคลิปต้นฉบับ ผู้สนใจสามารถดูคลิปเต็มเพื่อรับลิงก์ install ล่าสุดได้
ปัญหาที่ skill ตัวนี้แก้: Claude ยังไม่มีโมเดลดูวิดีโอ
Brad ย้ำในคลิปว่า Anthropic ยังไม่มีโมเดล video ของตัวเอง ถ้าต้องการให้ Claude เข้าใจวิดีโอ ทางออกที่นิยมคือเรียกใช้โมเดลของ Google Gemini ซึ่งรองรับ input แบบ video โดยตรง แต่มีต้นทุนต่อ minute สูงและไม่ได้ผูกกับ Claude อย่างลื่นไหล สำหรับคนที่ดูคอนเทนต์วันละหลายคลิป บิลจะวิ่งเร็วมาก
ช่อง Brad | AI & Automation จึงเลือกอีกเส้นทาง โดยมองว่าวิดีโอจริง ๆ แล้วมีแค่ 2 ส่วน คือ กองเฟรมภาพ กับ transcript ดังนั้นแทนที่จะจ่ายให้โมเดล video ราคาแพง ก็แยกวิดีโอออกเป็นสองส่วนนี้ แล้วป้อนให้ Claude ในรูปแบบที่โมเดลถนัดอยู่แล้วอย่าง "รูปภาพ + ข้อความ" วิธีนี้ใช้ความสามารถที่ Claude ทำได้ดีอยู่แล้ว โดยไม่ต้องรอโมเดล video version ใหม่
Brad ระบุในคลิปว่าเครื่องมือ transcript ตัวอื่นที่เคยลองก่อนหน้านี้ มักผูกทุกอย่างไว้กับ subtitle อย่างเดียว ผลคือเมื่อสิ่งสำคัญเกิดบนหน้าจอแต่ไม่มีใครพูดออกมา Claude จะมองไม่เห็นเลย ตัวอย่างที่ Brad ยกคือเลคเชอร์ของ Sam Altman ที่มีกราฟสำคัญหลายชุด ถ้าอ่านแค่ transcript จะได้ข้อมูลแค่ครึ่งเดียว เพราะอีกครึ่งหนึ่งของสาระสำคัญในวิดีโออยู่บนภาพ ไม่ได้อยู่ในเสียง
กลไกข้างใน: yt-dlp + FFmpeg + caption ฟรี + Whisper บน Groq
จุดที่ Brad ชอบที่สุดในการออกแบบ skill /watch คือไม่มี MCP ไม่มี wrapper ใหม่ และไม่มี third-party service ตัวกลาง skill นี้อาศัยเครื่องมือ command-line สองตัวที่ใช้กันมานานกว่าทศวรรษ ติดตั้งครั้งเดียวก็รันบนเครื่องตัวเองได้ทันที
- yt-dlp ทำหน้าที่เป็น downloader เทียบได้กับการ "Save Video" บนเบราว์เซอร์ และรองรับเว็บกว่า 1,000 แห่ง
- FFmpeg ทำหน้าที่เป็น engine ตัดวิดีโอออกเป็น 2 ก้อน ก้อนแรกคือสกรีนช็อตที่ถ่ายทุก ๆ ไม่กี่วินาทีตลอดทั้งคลิป ส่วนก้อนที่สองคือไฟล์เสียงสะอาด ๆ ที่พร้อมป้อนเข้า Whisper เพื่อแปลงเป็นข้อความพร้อม timestamp
หลังจากนั้น Claude จะได้ข้อมูลสองอย่างพร้อมกัน คือเฟรมภาพที่เรียงเหมือน flipbook กับ transcript ที่ลำดับเวลาตรงกับภาพ ทำให้โมเดลรู้ว่าขณะมีเสียงพูดแต่ละประโยค บนจอกำลังแสดงอะไรอยู่ ตามที่ Brad นำเสนอ การออกแบบ pipeline แบบนี้ไม่ใช่เรื่องใหม่ แต่เป็นวิธีที่เครื่องมือวิดีโอแทบทุกตัวบนอินเทอร์เน็ตใช้กันอยู่แล้วใต้ฮูด
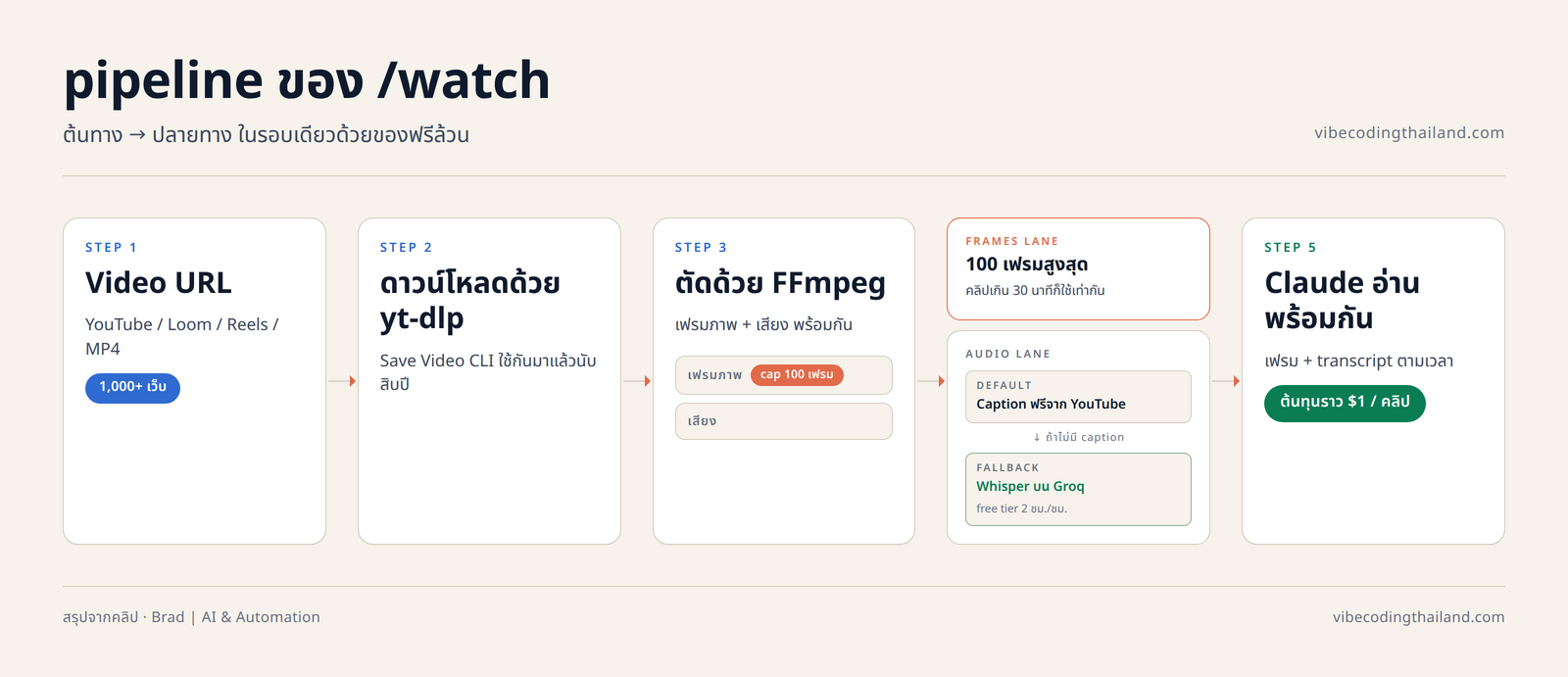
ส่วน transcript ระบบจะลองดึง caption ฟรีจาก YouTube ก่อนเสมอ เพราะแทบทุกวิดีโอ YouTube มี caption ที่ทำไว้ให้ใช้ฟรี ถ้าเจอวิดีโอที่ไม่มี caption เช่นไฟล์ MP4 ดิบ ๆ ที่บันทึกจาก Loom หรือ Instagram Reel ระบบจะ fallback ไปเรียก Whisper ที่ host อยู่บน Groq โดย Brad บอกว่าเลือก Groq เพราะเร็วมาก และ free tier ครอบคลุมการใช้งานรายวันได้สบาย
ต้นทุนต่อคลิป: ประมาณ $1 ไม่ว่ายาวเท่าไร
ข้อมูลจากคลิปของ Brad ทำให้เห็นว่าหลายคนกังวลเรื่อง token budget เพราะ skill ที่ป้อนทั้งภาพและข้อความให้ Claude ฟังดูเปลือง แต่ Brad ยกตัวเลขจากการทดสอบจริงว่า skill นี้ปรับจำนวนเฟรมตามความยาวของวิดีโอ และมีเพดานสูงสุดที่ 100 เฟรมสำหรับคลิปที่ยาวเกิน 30 นาที
ผลลัพธ์คือวิดีโอ 30 นาทีกับวิดีโอ 1 ชั่วโมงมีต้นทุน Claude usage ใกล้เคียงกัน อยู่ที่ราว 1 ดอลลาร์ต่อรอบ Brad รันทดสอบทุกซีนในคลิปต้นฉบับซ้ำคลิปละ 3 รอบขนานกัน แต่ใช้ session quota ไปไม่ถึง 10% รวมแล้วเทียบเท่าวิดีโอกว่า 5 ชั่วโมงที่ Claude ดูสด ๆ พร้อมถอดเสียงครบ
สำหรับการถอดเสียง Brad ระบุว่าถ้าเป็นวิดีโอ YouTube จะใช้ caption ที่ทำมาให้ฟรี ไม่ต้องเรียก Whisper หรือเสีย API ใด ๆ ระบบจะเรียก Whisper เฉพาะกรณีไฟล์ไม่มี caption เช่น MP4 ดิบ ไฟล์ Loom หรือ Instagram Reel โดย Groq free tier ให้โควต้าถอดเสียง 2 ชั่วโมงต่อ 1 ชั่วโมงตามนาฬิกาจริง ซึ่ง Brad ใช้ skill นี้ทุกวันมา 2 สัปดาห์โดยยังอยู่บน free tier
วิธีติดตั้งใน Claude Code: ทำได้ในไม่ถึง 5 นาที
ในคลิปต้นฉบับ Brad สาธิตการติดตั้งจริงตามลำดับขั้นดังนี้
- โหลด skill ฟรีจาก GitHub โดยลิงก์อยู่ในคำอธิบายของคลิปต้นฉบับ
- รันคำสั่งติดตั้งตามที่ระบุใน README ของ repository ซึ่ง Brad ระบุว่ามีไม่กี่บรรทัด
- Claude Code จะเรียก setup script ของ skill เพื่อตรวจและติดตั้ง dependency ที่ยังไม่มี เช่น yt-dlp และ FFmpeg ให้อัตโนมัติ
- ระบบจะ authenticate กับ transcription API ที่ Brad เลือกไว้คือ Groq ซึ่ง free tier เพียงพอสำหรับงานรายวัน
- หลังติดตั้งเสร็จ พิมพ์คำสั่ง
/watch <url>ใน Claude Code แล้วระบบจะเริ่ม pipeline ทันที
ในการใช้งานจริง Brad โชว์ flow สั้น ๆ คือเปิด YouTube ในแท็บข้าง ๆ กดเล่นเลคเชอร์ของ Sam Altman จากนั้น copy URL ไป paste หลังคำสั่ง /watch ในหน้าต่าง Claude Code เพียงเท่านี้ Claude ก็จะดึง subtitle จาก YouTube ตัดเฟรมด้วย FFmpeg และวิเคราะห์ทั้งหมดพร้อมกัน ก่อนตอบกลับเป็นสรุปแบบมีโครงสร้าง ตามที่ Brad นำเสนอ ขั้นตอนนี้เสร็จก่อนผู้ใช้จะดูเนื้อหา 2 นาทีแรกของคลิปต้นฉบับจบด้วยซ้ำ
Tip: skill รองรับ flag
start,end, และzoomทำให้ระบุช่วงเวลาที่ต้องการให้ Claude โฟกัสเฉพาะส่วนได้ เช่น ถ้าต้องการให้วิเคราะห์เฉพาะ 10 วินาทีในคลิปยาว 2 ชั่วโมง ก็สามารถกำหนด start/end ของช่วงนั้นแทนการป้อนทั้งคลิป ซึ่งช่วยประหยัด context window อย่างมาก
3 use case ของจริงที่ Brad ใช้ทุกวัน
1. แกะ hook ของวิดีโอ viral เพื่อทำ content research
ในคลิป Brad ยกตัวอย่างการทำ content research โดยหยิบวิดีโอที่ทำตัวเลขดีบนอินเทอร์เน็ตมาให้ Claude ช่วยแกะ hook Claude จะอ่านได้ตั้งแต่ visual setup ในช่วงเปิด คำพูดที่ใช้ จุดที่ pattern interrupt เกิดขึ้น ไปจนถึงสิ่งที่ปรากฏบนหน้าจอในจังหวะที่ hook ลงพอดี ตามที่ Brad นำเสนอ งานที่เคยใช้เวลาราว 10 นาทีต่อคลิปในการ pause และ scrub กลับไปดูซ้ำ ตอนนี้เหลือแค่ paste URL เข้าไปครั้งเดียว
2. Debug ไฟล์ screen recording ของ UI bug
สำหรับนักพัฒนา Brad ชี้ว่าเมื่อเจอ UI bug ที่ reproduce ยาก สามารถบันทึก screen recording สั้น ๆ ราว 30 วินาที drop ลงใน Claude พร้อมคำสั่ง /watch แล้วถามว่า "เกิดอะไรขึ้นก่อน crash" Claude จะอ่าน frame รอบจังหวะที่เกิดปัญหา ระบุ state change ที่เปลี่ยนไป และตอบกลับมาว่าเฟรมไหนคือจุดที่ bug เริ่มแสดงอาการ Brad บอกว่าวิธีนี้ช่วยประหยัดเวลา debug ไปได้หลายชั่วโมง โดยเฉพาะกับ bug ที่เกิดเป็นช่วงสั้น ๆ และต้อง replay หลายรอบเพื่อตามเก็บรายละเอียด
3. ป้อน second brain ใน Obsidian อัตโนมัติ
use case ที่ Brad ระบุว่าเปลี่ยนวิธีบริโภค content ของตัวเอง คือการป้อน knowledge base ใน Obsidian โดยอัตโนมัติ Brad เก็บ note, snippet, และไอเดียคอนเทนต์ไว้ใน Obsidian มาตลอด คอขวดเดิมคือมีคอนเทนต์ดี ๆ จาก creator จำนวนมาก แต่ไม่มีเวลาดูและจดสรุปทุกคลิป
solution ที่ Brad ใช้คือกำหนดรายการช่องคู่แข่งที่อยากตาม จากนั้นปล่อยให้ Claude ใช้ /watch ดูแต่ละคลิปอัตโนมัติ แล้วเขียน note แบบมีโครงสร้างกลับเข้า second brain Claude จะอ่านทั้งเฟรมและเสียง สรุปว่าคลิปนั้น work เพราะอะไร แล้ววางเข้า Obsidian ในรูปแบบที่ค้นหาได้ ตามที่ Brad นำเสนอ ระบบนี้เริ่ม compound เมื่อ skill ดูคลิปมากขึ้น เพราะ second brain ของผู้ใช้ก็จะรู้ pattern คอนเทนต์มากขึ้นตามไปด้วย

ข้อจำกัดที่ควรรู้ก่อนเริ่มใช้
Brad ระบุชัดในคลิปว่า skill ตัวนี้ไม่ใช่ silver bullet และยังมีจุดที่ optimize เพิ่มได้อีก ผู้สนใจควรรู้ข้อจำกัดต่อไปนี้ก่อนรันบน workflow จริง
- การจำกัด 100 เฟรมสำหรับคลิปยาวเกิน 30 นาที หมายความว่าเหตุการณ์สำคัญที่กินเวลาแค่ไม่กี่วินาทีอาจถูกเฉลี่ยทิ้งระหว่างเฟรม ถ้าต้องการรายละเอียดระดับวินาที ควรใช้ flag
start,endหรือzoomเพื่อโฟกัสช่วงเวลานั้นแทนการรันทั้งคลิป - caption ของ YouTube มีคุณภาพแตกต่างกัน บางคลิปเป็น auto caption ที่สะกดคำเฉพาะทางผิด ผลลัพธ์สรุปจึงอ้างอิงข้อมูลที่ถอดเสียงผิดพลาดได้ ถ้าเนื้อหามีคำเฉพาะทางมาก ควรตรวจสอบ transcript ที่ Whisper ดึงมาก่อนนำสรุปไปใช้ต่อ
- skill ผูกกับ yt-dlp และ FFmpeg ซึ่งต้องอัปเดตเป็นระยะตาม API ของแต่ละเว็บ ถ้า YouTube หรือ Loom เปลี่ยน schema อาจต้อง upgrade dependency เอง
- Groq free tier มีโควต้าจำกัด หากใช้ skill แบบ batch ดูคลิปทีละหลายชั่วโมงพร้อมกัน อาจต้องสมัครแผนที่สูงกว่า free tier เพื่อรองรับ workload
Brad ทิ้งท้ายว่าถ้าใครมีไอเดียที่ทำให้ pipeline เร็วขึ้นหรือถูกลง สามารถไป comment ใต้คลิปต้นฉบับ เพื่อให้ community ช่วยกันพัฒนา repo ต่อได้
สรุป
skill /watch ที่ช่อง Brad | AI & Automation ปล่อยฟรีบน GitHub สะท้อนแนวคิดที่ใช้ได้ดีกับงาน AI tooling จำนวนมาก คือเมื่อโมเดลที่ต้องการยังไม่มีหรือยังแพง เราสามารถถอยกลับมาดูก่อนว่า input เดิมประกอบด้วยอะไรบ้าง แล้วใช้เครื่องมือที่ rock solid อยู่แล้ว เช่น yt-dlp และ FFmpeg แปลง input ให้อยู่ในฟอร์แมตที่โมเดลปัจจุบันถนัด ผลคือต้นทุนลดลง ความเร็วเพิ่มขึ้น และยังใช้กับแหล่งวิดีโอกว่า 1,000 เว็บได้พร้อมกัน
สำหรับนักพัฒนาและคนทำคอนเทนต์ที่ใช้ Claude Code อยู่แล้ว skill /watch ทำให้การดูคลิปกลายเป็น input pipeline ที่ผูกเข้ากับงานประจำได้ ไม่ว่าจะเป็น content research, การ debug UI bug จาก screen recording, หรือการป้อน second brain ใน Obsidian ทั้งหมดทำได้ในต้นทุนไม่กี่ดอลลาร์ต่อสัปดาห์ ตามที่ Brad นำเสนอ สิ่งนี้ทำให้ Claude เปลี่ยนสถานะจาก "ผู้ช่วยเขียนโค้ด" เป็น "ผู้ช่วยดูคอนเทนต์" ที่ขยับเข้าใกล้ workflow ของ creator และ developer มากขึ้นอีกขั้น
เนื้อหานี้สรุปจากคลิปของช่อง Brad | AI & Automation: "My Claude Code Can INSTANTLY Watch Any Video (Here's How)" ผู้สนใจสามารถดูคลิปต้นฉบับเพื่อรับลิงก์ติดตั้ง skill ฟรีจาก GitHub ได้ที่ youtube.com/watch?v=QZMljuD10sU



