Sakana Fugu Ultra เคลมว่าเก่งกว่า Opus 4.8 เพราะไม่ได้เป็นโมเดลเดี่ยว แต่เป็น 'ทีมโมเดล'
Sakana Fugu คือระบบ AI ตัวใหม่จากญี่ปุ่นที่ผู้สร้างเคลมว่าทำงานหลายอย่างได้ดีกว่าโมเดลเดี่ยวที่เก่งสุดอย่าง Opus 4.8 ความน่าสนใจไม่ได้อยู่ที่ตัวเลข แต่อยู่ที่วิธีคิดที่ต่างออกไป เพราะมันไม่ได้สู้ด้วยโมเดลใหญ่ตัวเดียว แต่จัดทีมโมเดลผู้เชี่ยวชาญหลายตัวให้ช่วยกันทำงาน

Sakana Fugu คือระบบ AI ตัวใหม่จากบริษัท Sakana AI ของญี่ปุ่น เพิ่งเปิดให้ใช้ทั่วไปเมื่อ 22 มิถุนายน 2026 และมาพร้อมคำเคลมที่ฟังดูเกินจริงว่า ทำงานหลายอย่างได้ดีกว่าโมเดลเดี่ยวที่หลายคนยกให้เก่งสุดในตอนนี้อย่าง Opus 4.8 รวมถึง Gemini 3.1 Pro และ GPT 5.5 ด้วย
จุดที่ต้องพูดให้ชัดตั้งแต่ต้นคือ คำว่า "เก่งกว่า" นี้เป็นคำของผู้สร้างเอง ไม่ใช่คำตัดสินจากรีวิวอิสระ แต่สิ่งที่ทำให้เรื่องนี้น่าตามไม่ใช่ตัวเลข แต่อยู่ที่วิธีคิดเบื้องหลัง เพราะ Fugu ไม่ได้พยายามชนะด้วยการสร้างโมเดลที่ใหญ่กว่าหรือฉลาดกว่าตัวเดียว แต่เปลี่ยนเกมไปเล่นอีกแบบหนึ่ง
ดาวเดี่ยวที่เก่งสุด กับทีมที่จัดงานเป็น

ลองนึกภาพการแก้โจทย์ยากสักข้อหนึ่ง วิธีที่เราคุ้นเคยคือถามโมเดลที่เก่งที่สุดตัวเดียว แล้วหวังว่ามันจะเก่งพอจะตอบได้ครบทุกมุม นี่คือแนวคิด "ดาวเดี่ยวที่เก่งสุด" ที่วงการ AI วิ่งตามกันมาตลอด ใครมีโมเดลใหญ่กว่า ฉลาดกว่า ก็ชนะ
Sakana Fugu เลือกอีกทาง แทนที่จะเป็นดาวเดี่ยว มันทำตัวเป็น "หัวหน้าทีม" ที่คอยจัดทีมผู้เชี่ยวชาญหลายคนมาช่วยกันแก้โจทย์ ตัว Fugu เองก็เป็น LLM เหมือนกัน แต่ฝึกมาเพื่อทำงานเดียวโดยเฉพาะ คือการประสานงาน หรือที่เรียกกันว่า orchestration
พูดง่าย ๆ Fugu คือโมเดลที่ฝึกมาให้เรียกใช้โมเดลอื่นได้เป็น มันรู้ว่าโจทย์แบบไหนควรส่งให้ใคร งานไหนควรให้ใครมาช่วย แล้วเอาคำตอบจากหลายตัวมารวมเป็นคำตอบเดียว เหมือนหัวหน้าทีมที่ไม่ต้องเก่งทุกเรื่องเอง แต่เก่งเรื่องการเลือกคนและแบ่งงาน
ส่งงานเข้าประตูเดียว แต่ข้างในจัดทีมกันเอง
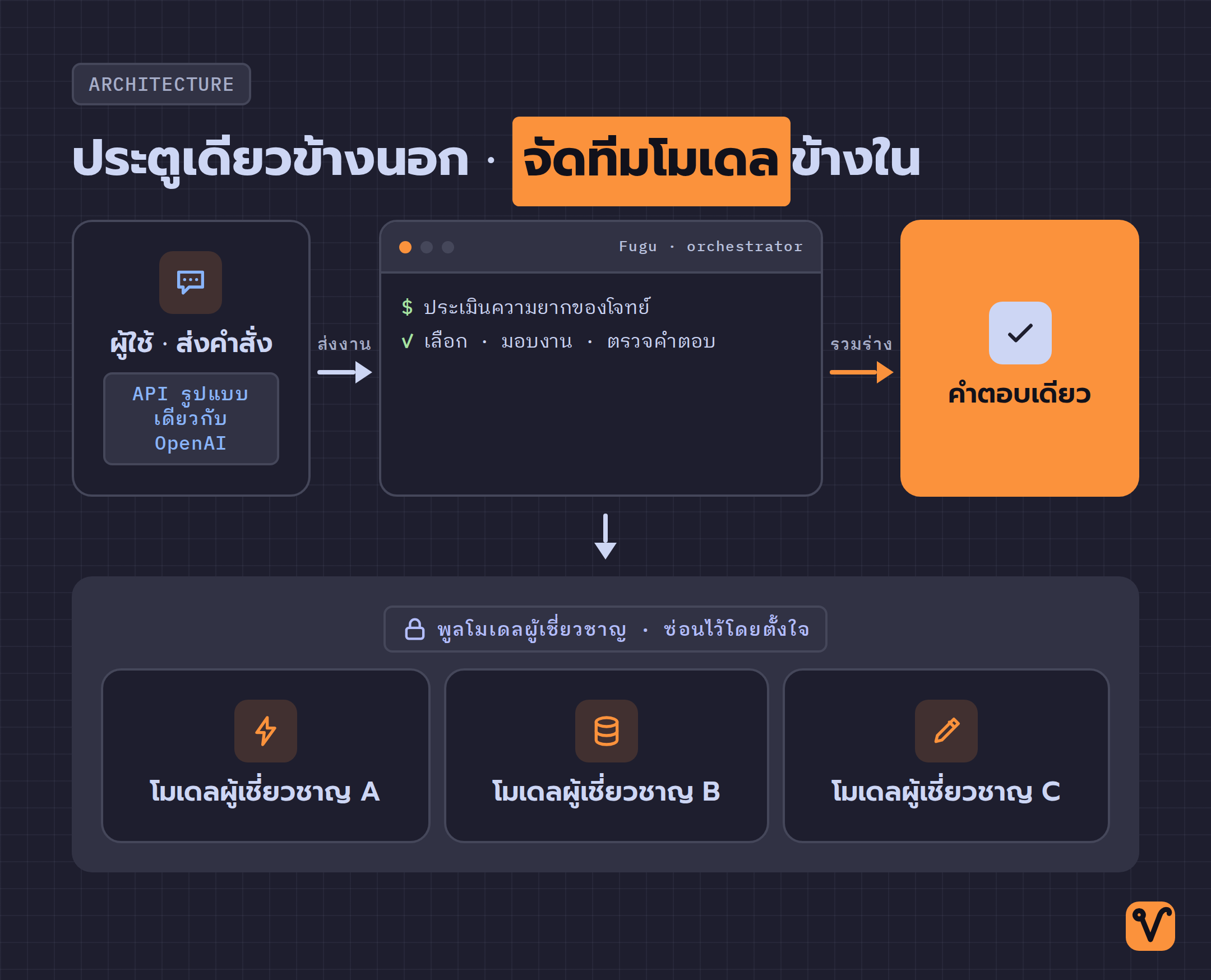
ในมุมของคนใช้ Fugu ดูเรียบง่ายมาก เราส่งคำสั่งเข้าไปที่ปลายทางเดียว ผ่าน API ที่ออกแบบให้เข้ากับรูปแบบของ OpenAI ได้ แปลว่าถ้าใครเขียนโค้ดเรียกใช้ AI อยู่แล้ว ก็แทบไม่ต้องแก้อะไรเลย เปลี่ยนปลายทางมาที่ Fugu ก็ใช้ได้
แต่ข้างในประตูบานนั้น มีกระบวนการที่ซ่อนอยู่ พอ Fugu รับงานมา มันจะประเมินก่อนว่าโจทย์ยากแค่ไหน
- ถ้าเป็นงานง่าย Fugu ตอบเองได้เลย ไม่ต้องเรียกใคร
- ถ้าเป็นงานซับซ้อนหลายขั้น มันจะเริ่มจัดทีม คือเลือกโมเดลผู้เชี่ยวชาญจากพูล มอบงานให้แต่ละตัว ตรวจคำตอบที่ได้กลับมา แล้วรวมทุกอย่างเป็นคำตอบเดียวก่อนส่งกลับมาหาเรา
ที่น่าสนใจคือ ในฐานะคนใช้ เรามองไม่เห็นกระบวนการทั้งหมดนี้เลย เห็นแค่คำตอบสุดท้าย Fugu ตั้งใจปิดบังไว้ว่าข้างในใช้โมเดลตัวไหนบ้าง เป็นการออกแบบโดยตั้งใจ ไม่ใช่ความบังเอิญ ข้อดีคือโค้ดของเราสะอาด ไม่ต้องไปนั่งเขียน fallback เองว่างานนี้ลองตัวนี้ก่อน ถ้าไม่ได้ค่อยเปลี่ยนตัว ข้อแลกเปลี่ยนคือเราต้องเชื่อใจการตัดสินใจของมัน เพราะมันไม่บอกเรา
มี 2 รุ่น เลือกตัวไหนเมื่อไหร่
Fugu มีสองรุ่น เรียกผ่าน API เดียวกัน แต่จัดทีมลึกต่างกัน
- Fugu รุ่นเร็วและสมดุล จัดทีมแบบพอเหมาะ เหมาะกับงานประจำวัน งานโค้ดทั่วไป และงานแชตที่ต้องการคำตอบไว
- Fugu Ultra รุ่นที่จัดทีมลึกกว่า เรียกผู้เชี่ยวชาญมาช่วยมากขึ้นและตรวจทานละเอียดกว่า เน้นคุณภาพของงานยากที่มีหลายขั้นตอน แลกมาด้วยความเร็วที่ช้าลง
ถ้าจะเลือกให้ตรงงาน ให้ใช้ Fugu กับงานที่ต้องการความเร็วและทำบ่อย ๆ ส่วนงานยากที่ยอมรอได้เพื่อคำตอบที่ดีกว่า เช่น งานวิจัยหรืองานวิเคราะห์ที่ซับซ้อน ให้ใช้ Fugu Ultra ตัวเลขที่ Sakana เคลมว่าชนะ Opus 4.8 และเพื่อน ๆ นั้นมาจากรุ่น Ultra เป็นหลัก
ตัวเลขที่ผู้สร้างยกมา และตัวเลขที่ขาดหายไป
นี่คือส่วนที่ต้องอ่านอย่างมีสติ เพราะตัวเลขทุกตัวที่ Sakana ยกมาเป็นตัวเลขที่ Sakana วัดเอง ส่วนตัวเลขของโมเดลคู่แข่งแต่ละตัว ก็เป็นค่าที่แต่ละค่ายรายงานเอง ไม่ใช่การวัดในสนามเดียวกันโดยคนกลาง
เท่าที่ Sakana เปิดเผยในหน้าผลิตภัณฑ์ Fugu Ultra ทำคะแนนได้น่าสนใจในหลายงาน
- งานวิจัยอัตโนมัติ วัดด้วยค่า BPB ที่ยิ่งต่ำยิ่งดี Fugu Ultra ได้ 0.9774 เอาชนะคู่เทียบทุกตัวที่ทำได้ 0.978 ถึง 0.982
- การอ่านลำดับตัวอักษรคานะ วัดด้วยค่าที่ยิ่งสูงยิ่งดี Fugu Ultra ได้ 0.80 ขณะที่คู่เทียบได้ราว 0.24 และบางตัวสร้างผลลัพธ์ไม่ได้เลย
- การแก้ลูกบาศก์รูบิค 300 ลูก Fugu Ultra แก้ได้ครบทั้ง 300 ลูก เฉลี่ย 19.72 ท่าต่อลูก ขณะที่คู่เทียบบางตัวระบบล่ม แก้ไม่ได้สักลูก
มีอีกเคสที่ต้องระวังเป็นพิเศษ คือการทดสอบเทรดหุ้นจำลอง 50 สัปดาห์ Fugu Ultra ทำผลตอบแทนได้ +19.43% ขณะที่โมเดลอื่นทุกตัวต่ำกว่า +15%
นอกจากนี้ยังมีเสียงจากผู้ทดสอบจริงในช่วงเบต้าที่มีคนร่วมเกือบ 500 คน วิศวกรซอฟต์แวร์คนหนึ่งเล่าว่า ตอนให้ Fugu ช่วยรีวิวโค้ด มันเจอปัญหามากกว่า 20 จุด ขณะที่เครื่องมืออื่นเจอราว 3 จุด แต่ต้องย้ำว่านี่เป็นคำบอกเล่าจากผู้ใช้ ไม่ใช่ผลทดสอบมาตรฐาน
แล้วตัวเลขที่ "ขาดหายไป" ล่ะ ที่มาไม่ได้บอกว่าในพูลของ Fugu มีโมเดลตัวไหนบ้าง ไม่ได้บอกด้วยซ้ำว่า Opus 4.8 อยู่ในพูลหรือไม่ ส่วนโมเดลระดับสูงอย่าง Fable 5 และ Mythos Preview นั้น Sakana ระบุชัดว่าไม่ได้อยู่ในพูล เพราะยังไม่เปิดให้ใช้ทั่วไป แต่ถูกหยิบมาใช้เป็นตัวเทียบในด้านวิศวกรรม วิทยาศาสตร์ และการให้เหตุผล
ก่อนจะเชื่อพาดหัว ต้องรู้อะไรบ้าง
Fugu ไม่ใช่โมเดลโอเพนซอร์สที่โหลดมารันบนเครื่องตัวเองได้ฟรี แต่เป็นบริการที่ต้องสมัครใช้ผ่าน console.sakana.ai มีทั้งแบบจ่ายรายเดือนสำหรับการใช้ทั่วไป และแบบจ่ายตามการใช้งานจริงสำหรับงานหนักระดับองค์กร
เรื่องราคาต่อการใช้งาน ค่าสมัคร และข้อจำกัดเรื่องภูมิภาค ว่าประเทศไหนใช้ได้บ้าง ที่มาไม่ได้ระบุไว้ ใครสนใจจริงต้องเข้าไปเช็กรายละเอียดที่ console เอง อย่าเพิ่งเชื่อตัวเลขราคาจากที่อื่นก่อนเห็นข้อมูลจริง
จุดที่ Sakana พยายามขายอีกอย่างคือเรื่องการไม่ผูกกับเจ้าใดเจ้าหนึ่ง เพราะ Fugu ออกแบบมาให้สลับโมเดลในพูลได้ ถ้าผู้ให้บริการรายไหนปิดการเข้าถึง ระบบก็ปรับตัวตามสถานการณ์นั้นได้อัตโนมัติ และทีมที่มีข้อกำหนดเรื่องความเป็นส่วนตัวของข้อมูล ก็เลือกตัดบางโมเดลออกจากพูลได้
บทพิสูจน์จริงยังมาไม่ถึง
แนวคิด "ทีมเอาชนะดาวเดี่ยว" เป็นวิธีคิดที่น่าสนใจ และถ้ามันได้ผลจริงตามที่เคลม ก็จะเปลี่ยนวิธีที่เราเลือกใช้ AI ไปพอสมควร เพราะแทนที่จะมานั่งเปรียบเทียบว่าโมเดลไหนเก่งสุดในเดือนนี้ เราแค่ส่งงานเข้าทีมแล้วให้มันจัดการเอง
แต่ตอนนี้ทุกอย่างยังเป็นคำเคลมของผู้สร้าง พร้อมตัวเลขที่ผู้สร้างวัดเอง บทพิสูจน์ที่แท้จริงจะมาเมื่อคนนอกได้ลองใช้และวัดผลอย่างอิสระ ว่าทีมที่จัดมาดีจะชนะดาวเดี่ยวที่เก่งสุดได้จริงไหม จนกว่าจะถึงตอนนั้น สิ่งที่น่าจับตาไม่ใช่ว่ามันชนะ Opus 4.8 หรือเปล่า แต่เป็นว่าการประสานทีมโมเดลกำลังกลายเป็นสนามแข่งใหม่ที่อาจสำคัญกว่าการแข่งสร้างโมเดลให้ใหญ่ขึ้นเรื่อย ๆ
ที่มา:
- บทความ Sakana AI (Fugu release announcement) จาก Sakana AI
- หน้าผลิตภัณฑ์ Sakana Fugu — Multi-agent System as A Model จาก Sakana AI



