GLM 5.2 Fast โมเดลเขียนโค้ดตอบเร็วระดับ 120-250 โทเคนต่อวินาที เรียกใช้ได้แล้วบน Vercel AI Gateway
GLM 5.2 Fast คือโมเดลเขียนโค้ดจาก Z.AI ที่เน้นทั้งเก่งและเร็ว ตอบได้ระดับ 120-250 โทเคนต่อวินาที ตอนนี้เรียกใช้ได้แล้วบน Vercel AI Gateway ด้วย model id เดียว โดยไม่ต้องผูกกับผู้ให้บริการเจ้าใดเจ้าหนึ่ง

GLM 5.2 Fast คือโมเดลเขียนโค้ด (code model) ตัวใหม่จาก Z.AI บริษัทผู้สร้างโมเดลตระกูล GLM ที่เพิ่งเปิดให้เรียกใช้ผ่าน Vercel AI Gateway ซึ่งเป็นชั้นกลางสำหรับเรียกโมเดล AI จากผู้ให้บริการหลายเจ้าผ่าน API เดียว จุดที่ทำให้มันน่าจับตาไม่ใช่แค่เขียนโค้ดเก่ง แต่มัน ตอบเร็ว ระดับ 120-250 โทเคนต่อวินาที ความเร็วช่วงนี้ทำให้ผู้ช่วยเขียนโค้ดหรือ coding agent ตอบกลับได้แทบจะทันทีที่พิมพ์ และยังรับบริบทยาวได้ถึง 1 ล้านโทเคน
สำหรับคนที่ทำแอป AI · เขียน coding agent · หรือใช้ผู้ช่วยเขียนโค้ดเป็นประจำ เรื่องนี้โดนจุดเจ็บพอดี เพราะโมเดลที่เขียนโค้ดได้ดีหลายตัวมักจะ ช้า พอเอามาต่อกับ agent ที่ต้องเรียกซ้ำหลายรอบ ความช้าก็สะสมจนน่ารำคาญ GLM 5.2 Fast เข้ามาอุดช่องว่างนี้ โดยพยายามให้ได้ทั้งคุณภาพและความเร็วในตัวเดียว แล้วยังเรียกใช้ได้ทันทีด้วย model id เดียวคือ zai/glm-5.2-fast
เร็วแค่ไหน ถึงเรียกว่า "เร็วพอจะใช้งานจริง"

ตัวเลขที่ Z.AI ประกาศไว้คือ throughput ระดับ 120-250 โทเคนต่อวินาที ซึ่งวัดจากทราฟิกจริงบน AI Gateway ไม่ใช่ตัวเลขในห้องทดลอง
ความเร็วระดับนี้สำคัญกับงานบางแบบเป็นพิเศษ ถ้าใช้โมเดลแชทถามตอบทีละครั้ง ความเร็วอาจไม่ใช่คอขวด เพราะคนพิมพ์ช้ากว่าโมเดลตอบอยู่แล้ว แต่พอเป็น coding agent ที่ต้องคิด · เขียนโค้ด · รันเทสต์ · แก้ · วนซ้ำหลายรอบในงานเดียว ความช้าทุกขั้นจะสะสมจนกลายเป็นการรอที่ยาวเกินทน โมเดลที่ตอบเร็วจึงเปลี่ยนประสบการณ์ตรงนี้ได้มาก จากเดิมที่ต้องนั่งรอเป็นนาที งานก็ไหลลื่นพอที่จะทำต่อเนื่องได้
ที่ต้องเข้าใจคือ GLM 5.2 Fast เป็น "เวอร์ชันเร็ว" ของ GLM 5.2 มันแลกบางอย่างเพื่อความเร็ว ไม่ใช่ได้มาฟรีๆ ถ้างานต้องใช้การคิดวิเคราะห์ละเอียดที่สุด GLM 5.2 ตัวมาตรฐาน (model id zai/glm-5.2) อาจเหมาะกว่า แต่ถ้าอยากได้คำตอบที่ดีในเวลาที่สั้นลง ตัว Fast คือคำตอบ
บริบทยาว 1 ล้านโทเคน หมายความว่าอะไรกับงานจริง
อีกตัวเลขที่สะดุดตาคือ context window ที่ยาวถึง 1 ล้านโทเคน อัปเกรดจาก 200,000 โทเคนใน GLM 5.1 พูดง่ายๆ คือขนาดบริบทที่โมเดลเก็บไว้ใช้พร้อมกันในงานหนึ่งครั้งขยายขึ้นห้าเท่า
ในงานจริง ตัวเลขนี้หมายความว่า ยิ่ง context ยาว โมเดลก็ยิ่งเก็บโครงสร้างของโปรเจกต์ทั้งก้อนไว้ในหัวได้พร้อมกัน ไม่ใช่แค่ไฟล์เดียวที่กำลังแก้ ทำให้เข้าใจว่าโค้ดส่วนนี้เชื่อมกับส่วนไหน ฟังก์ชันนี้เรียกใช้จากไหน และทำตามมาตรฐานการเขียนโค้ดของโปรเจกต์ได้สม่ำเสมอกว่าเดิม Z.AI วางตำแหน่งมันไว้สำหรับงานยาวที่ต้องรันต่อเนื่องหลายขั้น และต้องแบกบริบทระดับโปรเจกต์ไว้ตลอดทั้งงาน
ความสามารถหลักของโมเดล
หน้าโมเดลระบุความสามารถหลักไว้สามอย่าง และทั้งสามมีผลกับการเอาไปต่อเป็น agent โดยตรง
- Reasoning ให้เหตุผลเป็นขั้นเป็นตอน ไม่ใช่ตอบแบบเดาคำถัดไป เหมาะกับงานที่ต้องวางตรรกะก่อนเขียนโค้ด
- Tool Use เรียกเครื่องมือภายนอกได้ เช่น รันคำสั่ง · ค้นไฟล์ · เรียก API ซึ่งเป็นหัวใจของการทำ coding agent
- Implicit Caching จำส่วนที่ซ้ำกันไว้เองโดยอัตโนมัติ ช่วยให้คำขอที่มีบริบทเดิมซ้ำๆ เร็วขึ้นและประหยัดขึ้น
สามอย่างนี้รวมกันคือเหตุผลที่มันถูกเรียกว่า code model ไม่ใช่แค่โมเดลแชททั่วไป เพราะมันถูกออกแบบมาให้ต่อเข้ากับเวิร์กโฟลว์การเขียนโค้ดจริง ไม่ใช่แค่ตอบเป็นข้อความ
เริ่มเรียกใช้ยังไง
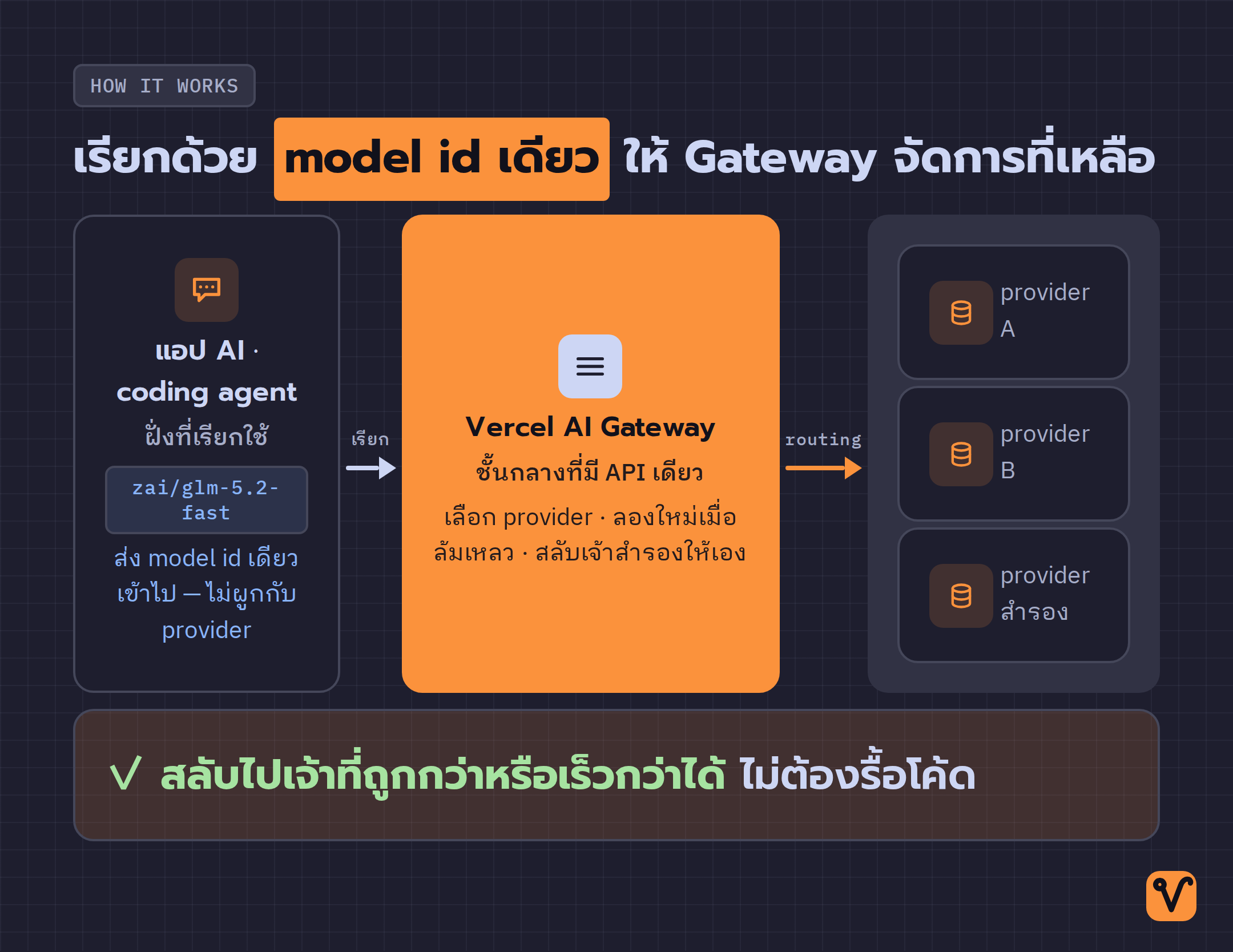
ส่วนที่ทำให้ของใหม่ตัวนี้ลองได้ง่ายคือมันมาอยู่บน Vercel AI Gateway ซึ่งเป็นชั้นกลางที่ให้เรียกโมเดลจากหลายเจ้าผ่าน API เดียว แทนที่จะต้องเขียนโค้ดผูกกับผู้ให้บริการแต่ละรายเอง
ตัวอย่างโค้ดสั้นมาก เขียนผ่าน Vercel AI SDK ซึ่งเป็นชุดเครื่องมือสำหรับเรียกใช้โมเดล AI ในแอปด้วย JavaScript/TypeScript ขั้นตอนเริ่มต้นมีสามข้อ
- ติดตั้งและ import จาก Vercel AI SDK ด้วย
import { streamText } from 'ai' - ตั้งค่า model เป็น
'zai/glm-5.2-fast'ในฟังก์ชันstreamText() - เรียกใช้ได้เลย AI Gateway จะเลือกส่งคำขอไปยัง provider ที่เหมาะให้เองโดยอัตโนมัติ
จุดที่เป็นข้อได้เปรียบจริงคือ model id เดียวนี้ไม่ผูกกับ provider เจ้าใดเจ้าหนึ่ง ถ้าวันหนึ่งอยากสลับไปใช้ผู้ให้บริการอื่นที่ถูกกว่าหรือเร็วกว่า ก็ไม่ต้องรื้อโค้ด เพราะ AI Gateway ทำหน้าที่เป็นตัวกลางจัดการ routing · ลองเรียกใหม่เมื่อล้มเหลว · และสลับไปเจ้าสำรองให้เอง
ราคากับเรื่องที่ต้องชั่งใจ
เรื่องราคามีจุดที่น่าสนใจ Vercel AI Gateway ไม่คิดค่าธรรมเนียมแพลตฟอร์มเพิ่มจากราคาของ provider ต้นทาง รวมถึงกรณีที่ใช้คีย์ของตัวเอง (BYOK · Bring Your Own Key) แปลว่าจ่ายเท่าราคา provider โดยตรง แล้วได้ระบบจัดการค่าใช้จ่ายเพิ่มมา ทั้งการติดตามค่าใช้จ่าย · ตั้งงบต่อ API key · และรายงานการใช้งาน
แต่ก็ต้องชั่งใจอีกด้านเหมือนกัน เพราะการมีชั้นกลางคั่นย่อมหมายความว่าทราฟิกวิ่งผ่านระบบของ Vercel ก่อนถึง provider ใครที่ต้องการคุมเส้นทางข้อมูลเองทุกขั้น หรืออยากเรียก provider ตรงๆ ก็ต้องชั่งน้ำหนักระหว่างความสะดวกของ API เดียวกับการควบคุมที่ละเอียดกว่า ส่วนเรื่องความเป็นส่วนตัวของข้อมูล AI Gateway มีตัวเลือก Zero Data Retention มาให้สำหรับงานที่ห้ามเก็บข้อมูล
GLM 5.2 Fast เพิ่งจะเปิดให้ใช้งานในวันนี้ และยังเป็นชื่อที่คนไทยไม่ค่อยพูดถึง สำหรับใครที่กำลังหาโมเดลเขียนโค้ดมาต่อกับ agent ของตัวเอง นี่คือจังหวะที่ได้ลองก่อนคนอื่น โดยมีข้อมูลจาก Vercel AI Gateway ให้ดูตั้งแต่ต้น
โมเดลที่เขียนโค้ดเก่งไม่ใช่ของหายากอีกต่อไป แต่โมเดลที่เก่งแล้วยัง เร็วพอ ให้เอาไปวนซ้ำในงานจริงได้โดยไม่ต้องนั่งรอ ต่างหากที่เพิ่งจะเริ่มมีให้เลือก
ที่มา:
- บทความ GLM 5.2 Fast Playground & API on Vercel AI Gateway จาก Vercel AI Gateway
- บทความ GLM 5.2 now available on AI Gateway จาก Vercel AI Gateway



