Large Language Model ทำงานยังไง · เบื้องหลังคือการเดาคำถัดไปซ้ำๆ ของ GPT-3 ที่มี 175 พันล้านพารามิเตอร์
Large Language Model หรือ LLM คือเครื่องจักรเบื้องหลังแชตบอต AI ที่ตอบโต้กับเราได้เหมือนคนเขียน เบื้องหลังไม่มีเวทมนตร์ มีแค่การเดาคำถัดไปแล้วแก้ให้แม่นขึ้นซ้ำๆ และบทความนี้จะพาไปดูทีละชิ้นว่าเกิดอะไรขึ้นข้างใน

Large Language Model หรือ LLM คือเครื่องจักรเบื้องหลังแชตบอต AI ที่พิมพ์โต้ตอบกับเราได้ราวกับคนเขียนจริงๆ แต่ตอนเริ่มฝึกใหม่ๆ มันไม่ได้ฉลาดอย่างที่เห็นเลย ถ้าให้เดาคำถัดไปจากประโยค "ท้องฟ้าเป็นสี..." คำแรกที่มันเดาออกมาคือ "บั๊ก" ซึ่งไม่ใช่สีอะไรทั้งนั้น
จากคำเดามั่วๆ ในวันแรก โมเดลกลายมาตอบได้ลื่นไหลแบบวันนี้ได้ยังไง คำตอบอยู่ที่สิ่งเดียวที่มันทำซ้ำนับล้านครั้ง นั่นคือเดาคำถัดไป เทียบกับคำจริง แล้วค่อยๆ แก้ตัวเองให้ผิดน้อยลง
เบื้องหลังความฉลาดที่ดูเหมือนเวทมนตร์ไม่มีเวทมนตร์อะไรเลย มีแค่การเดาแล้วแก้ซ้ำไปเรื่อยๆ ถ้าลองถอด LLM ออกมาดูข้างใน จะเห็นว่ามันประกอบขึ้นจากสามชิ้นส่วนเท่านั้น คือ ข้อมูล สถาปัตยกรรม และการฝึก
รากฐานของ LLM คือ foundation model
ถ้าจะเข้าใจ LLM ต้องเริ่มจากคำว่า foundation model ก่อน เพราะ LLM เป็น foundation model ประเภทหนึ่ง
foundation model คือโมเดลที่ผ่านการฝึกล่วงหน้า หรือ pre-train ด้วยข้อมูลจำนวนมหาศาลแบบที่ไม่ต้องมีคนมานั่งติดป้ายกำกับให้ทีละชิ้น มันเรียนรู้จากรูปแบบในข้อมูลด้วยตัวเอง แล้วกลายเป็นโมเดลอเนกประสงค์ที่เอาไปปรับใช้กับงานได้หลายแบบ
พอเอาแนวคิดเดียวกันนี้มาใช้กับข้อมูลที่เป็น "ข้อความ" โดยเฉพาะ ทั้งบทความ หนังสือ บทสนทนา รวมถึงโค้ดโปรแกรมที่มีโครงสร้างคล้ายภาษา เราก็จะได้สิ่งที่เรียกว่า Large Language Model ส่วนคำว่า Large หรือ "ใหญ่" ก็มาจากปริมาณข้อความที่มันอ่านเข้าไป ซึ่งมากจนเกินจินตนาการ
ใหญ่แค่ไหนถึงเรียกว่า Large
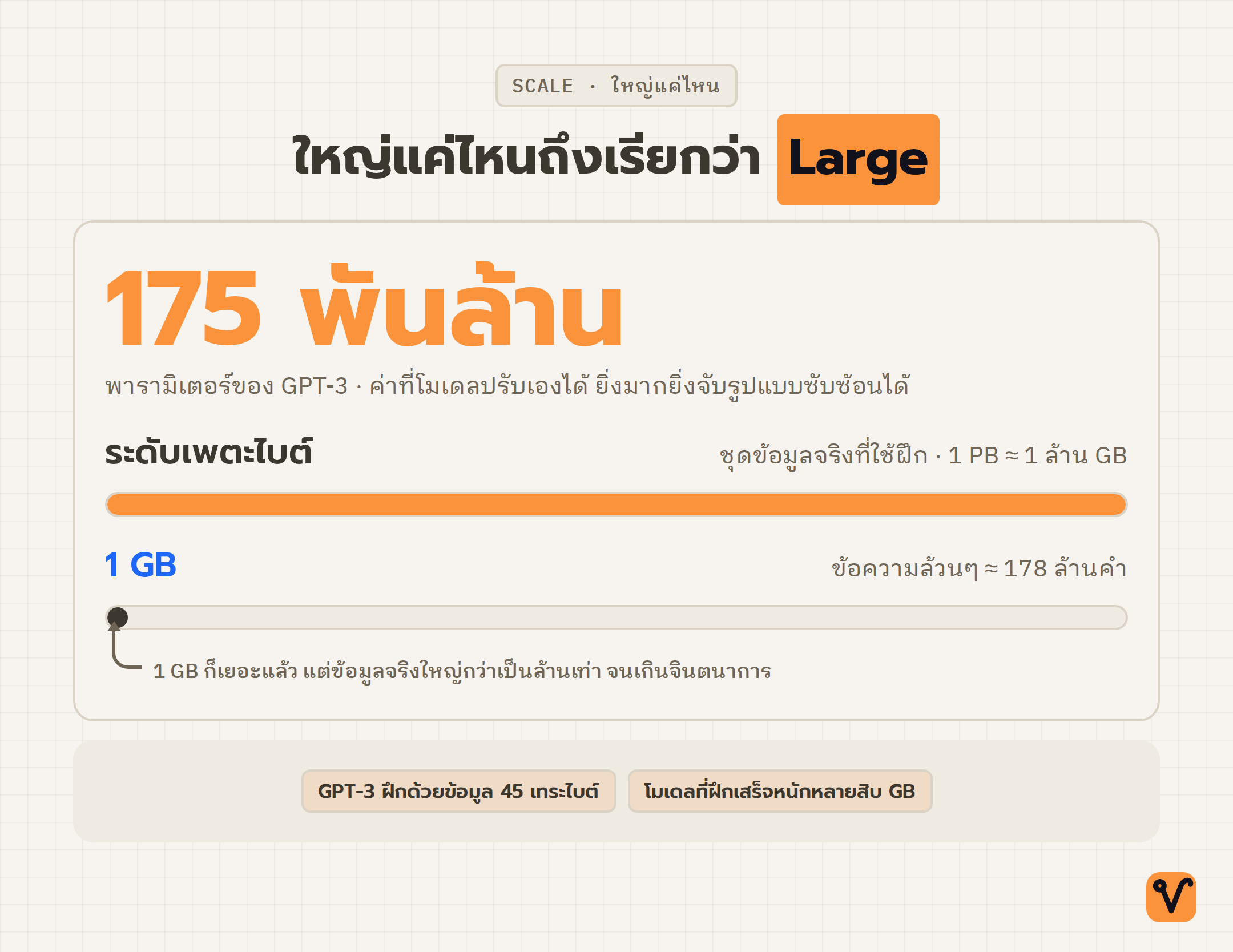
ลองนึกภาพขนาดของข้อความที่ใช้ฝึกดู ข้อความล้วนๆ ขนาด 1 กิกะไบต์เทียบเท่าคำประมาณ 178 ล้านคำ ฟังดูเยอะแล้วใช่ไหม แต่ชุดข้อมูลที่ใช้ฝึกจริงใหญ่ได้ถึงระดับเพตะไบต์ โดย 1 เพตะไบต์เท่ากับประมาณ 1 ล้านกิกะไบต์ ส่วนตัวโมเดลที่ฝึกเสร็จแล้วก็มีขนาดหลายสิบกิกะไบต์เช่นกัน
อีกตัวเลขที่บอกความใหญ่คือ "พารามิเตอร์" มันคือค่าที่โมเดลปรับเองได้อย่างอิสระในระหว่างที่เรียนรู้ ยิ่งมีพารามิเตอร์มากเท่าไร โมเดลก็ยิ่งจับรูปแบบที่ซับซ้อนได้มากขึ้นเท่านั้น
ยกตัวอย่างที่เห็นภาพชัดคือ GPT-3 ซึ่งย่อมาจาก Generative Pre-trained Transformer มันผ่านการฝึกล่วงหน้าด้วยข้อมูลถึง 45 เทระไบต์ และมีพารามิเตอร์มากถึง 175 พันล้านตัว
หัวใจอยู่ที่การชั่งน้ำหนักทุกคำ
ชิ้นส่วนที่สองคือสถาปัตยกรรม หรือโครงสร้างภายในของโมเดล สำหรับ GPT ส่วนนี้เป็นโครงข่ายประสาทเทียมแบบหนึ่งที่มีชื่อเรียกเฉพาะว่า transformer
จุดเด่นของ transformer คือมันมองข้อความเป็น "ลำดับ" ทั้งประโยคหรือทั้งบรรทัดโค้ด ไม่ได้อ่านทีละคำแบบแยกขาดจากกัน เมื่อเจอคำหนึ่ง มันจะชั่งน้ำหนักคำนั้นเทียบกับคำที่เหลือในประโยคทุกคำ เพื่อดูว่าคำนี้เกี่ยวข้องกับคำไหนมากน้อยแค่ไหน
การชั่งน้ำหนักแบบนี้ทำให้โมเดลเข้าใจทั้งโครงสร้างประโยคและความหมายของคำไปพร้อมกัน คำเดียวกันที่อยู่คนละประโยคจึงมีความหมายต่างกันได้ตามบริบทรอบข้าง
ฝึกด้วยการเดาคำถัดไป แล้วแก้ให้ตรงขึ้น
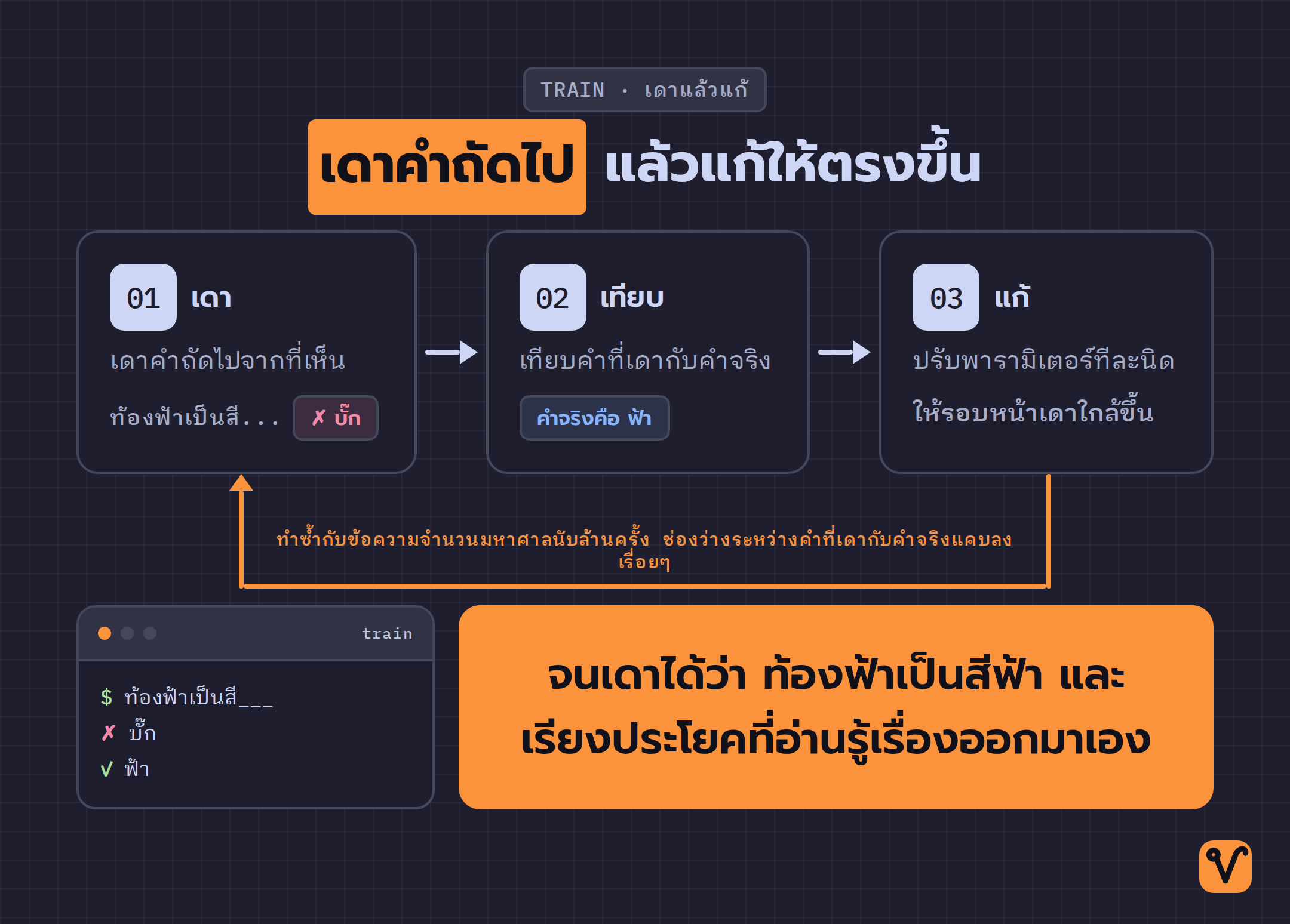
ชิ้นส่วนที่สามคือการฝึก และนี่คือหัวใจของทั้งหมด วิธีฝึกเรียบง่ายอย่างน่าประหลาด คือให้โมเดลเดาว่าคำถัดไปในประโยคควรเป็นอะไร
ย้อนกลับไปที่ประโยค "ท้องฟ้าเป็นสี..." ครั้งแรกโมเดลเดาแบบสุ่มว่า "บั๊ก" ซึ่งผิดแบบไม่เข้าเรื่อง จากนั้นมันจะเทียบคำที่เดากับคำตอบจริง แล้วปรับค่าพารามิเตอร์ภายในทีละเล็กน้อย เพื่อให้รอบหน้าเดาได้ใกล้เคียงขึ้น
ทำแบบนี้ซ้ำครั้งแล้วครั้งเล่ากับข้อความมหาศาล ช่องว่างระหว่างคำที่เดากับคำที่ถูกก็แคบลงเรื่อยๆ จนสุดท้ายโมเดลเดาได้ว่า "ท้องฟ้าเป็นสีฟ้า" และเริ่มร้อยประโยคที่ฟังรู้เรื่องออกมาได้เอง
พูดง่ายๆ คือความสามารถทั้งหมดที่เราทึ่ง ไม่ได้มาจากการที่โมเดลเข้าใจโลกเหมือนคน แต่มาจากการเดาผิดแล้วแก้ทีละนิดนับไม่ถ้วน
ฝึกต่อให้เก่งเฉพาะทาง
หลังผ่านการฝึกทั่วไปจนพูดจารู้เรื่องแล้ว ยังเอาโมเดลไปฝึกต่อได้อีกขั้น เรียกว่า fine-tuning หรือการปรับจูน
fine-tuning คือการเอาโมเดลที่เก่งรอบด้านอยู่แล้ว มาฝึกเพิ่มด้วยชุดข้อมูลที่เล็กลงแต่เจาะจงกว่าเดิม เพื่อให้มันทำงานเรื่องใดเรื่องหนึ่งได้แม่นยำเป็นพิเศษ
ขั้นตอนนี้เองที่เปลี่ยนโมเดลอเนกประสงค์ตัวหนึ่ง ให้กลายเป็นผู้เชี่ยวชาญเฉพาะงานที่ตอบได้ตรงจุดกว่าเดิม
เอาไปใช้ทำอะไรได้บ้าง
เมื่อเข้าใจกลไกแล้ว ก็จะเห็นภาพว่าทำไมถึงนำ LLM ไปใช้กับงานจริงได้หลากหลาย ตัวอย่างที่เห็นชัดมีอยู่สามกลุ่ม
- งานบริการลูกค้า · แชตบอตที่ใช้ LLM รับมือคำถามลูกค้าได้หลายรูปแบบ ช่วยแบ่งเบางานให้พนักงานไปโฟกัสเรื่องที่ซับซ้อนกว่า
- งานสร้างคอนเทนต์ · ช่วยร่างบทความ อีเมล โพสต์โซเชียล ไปจนถึงสคริปต์วิดีโอ
- งานพัฒนาซอฟต์แวร์ · ช่วยเขียนและตรวจทานโค้ด
และนี่เป็นเพียงส่วนเล็กๆ เท่านั้น ยิ่ง LLM พัฒนาไปไกลขึ้น งานที่มันเข้าไปช่วยได้ก็จะยิ่งมากขึ้นตาม
แต่ก็มีอีกด้านที่ต้องรู้ไว้ กลไกจริงๆ ของมันคือการเดาคำที่น่าจะตามมามากที่สุดจากรูปแบบที่เคยเห็น ไม่ใช่การเข้าใจความหมายแบบคน ผลลัพธ์ที่ออกมาลื่นไหลจึงไม่ได้แปลว่าถูกเสมอไป สิ่งที่มันเขียนออกมายังต้องมีคนคอยตรวจ โดยเฉพาะงานที่ผิดพลาดไม่ได้
มองทะลุแล้วจะใช้เป็น
พอมองทะลุว่าเบื้องหลังคือการเดาแล้วแก้ ไม่ใช่การรู้จริง ความทึ่งก็จะเปลี่ยนเป็นความเข้าใจ และความเข้าใจนี่เองที่ทำให้เราใช้มันเป็น รู้ว่าเมื่อไรควรเชื่อ และเมื่อไรควรตรวจซ้ำ



