lucidml โมเดล AI ที่เปลี่ยนภาพนิ่งหนึ่งภาพเป็นเกมเดินเล่นได้บนการ์ดจอในเครื่องที่บ้าน
lucidml คือโครงข่ายประสาทขนาดเล็กที่รับภาพนิ่งหนึ่งภาพ แล้วเปลี่ยนให้เป็นเกมที่กดปุ่มเดินเล่นได้แบบเรียลไทม์ จุดที่น่าสนใจคือมันตั้งใจออกแบบให้รันบนการ์ดจอเครื่องเล่นเกมในบ้าน ไม่ต้องพึ่ง datacenter

มีงานวิจัยอิสระชิ้นหนึ่งชื่อ lucidml ที่เพิ่งถูกแชร์ในชุมชน r/LocalLLaMA และทำเอาคนแห่กันเข้าไปดู สิ่งที่มันทำคือรับภาพนิ่ง 1 ภาพเป็นจุดเริ่ม แล้วเปลี่ยนภาพนั้นให้เป็นวิดีโอเกมที่กดแป้นพิมพ์เดินเล่นได้จริงแบบเรียลไทม์ ลองนึกภาพว่าเอารูปถ่ายทะเลทรายหนึ่งใบส่งให้มัน แล้วกดปุ่ม W เดินหน้าเข้าไปในรูปนั้นได้ ฉากเลื่อนเปลี่ยนตามปุ่มที่กด เหมือนกำลังเล่นเกม ทั้งที่ตอนแรกมันเป็นแค่ภาพนิ่งใบเดียว
จุดที่ทำให้คนหยุดอ่านไม่ใช่แค่ "AI สร้างเกมจากภาพ" เพราะงานสร้างโลกเสมือนแบบนี้มีมาก่อนแล้ว แต่ของพวกนั้นตัวใหญ่จนต้องรันบนเครื่องระดับ datacenter ส่วน lucidml กลับตั้งใจออกแบบมาให้รันบนการ์ดจอเครื่องเล่นเกมในบ้านอย่าง RTX 5090 และคนทำก็ไม่ใช่บริษัทใหญ่ แต่เป็นนิสิตปีสุดท้ายคนหนึ่งที่ฝึกโมเดลขึ้นมาจากศูนย์ด้วยตัวเอง
ภาพนิ่งใบเดียว เดินเข้าไปได้จริง
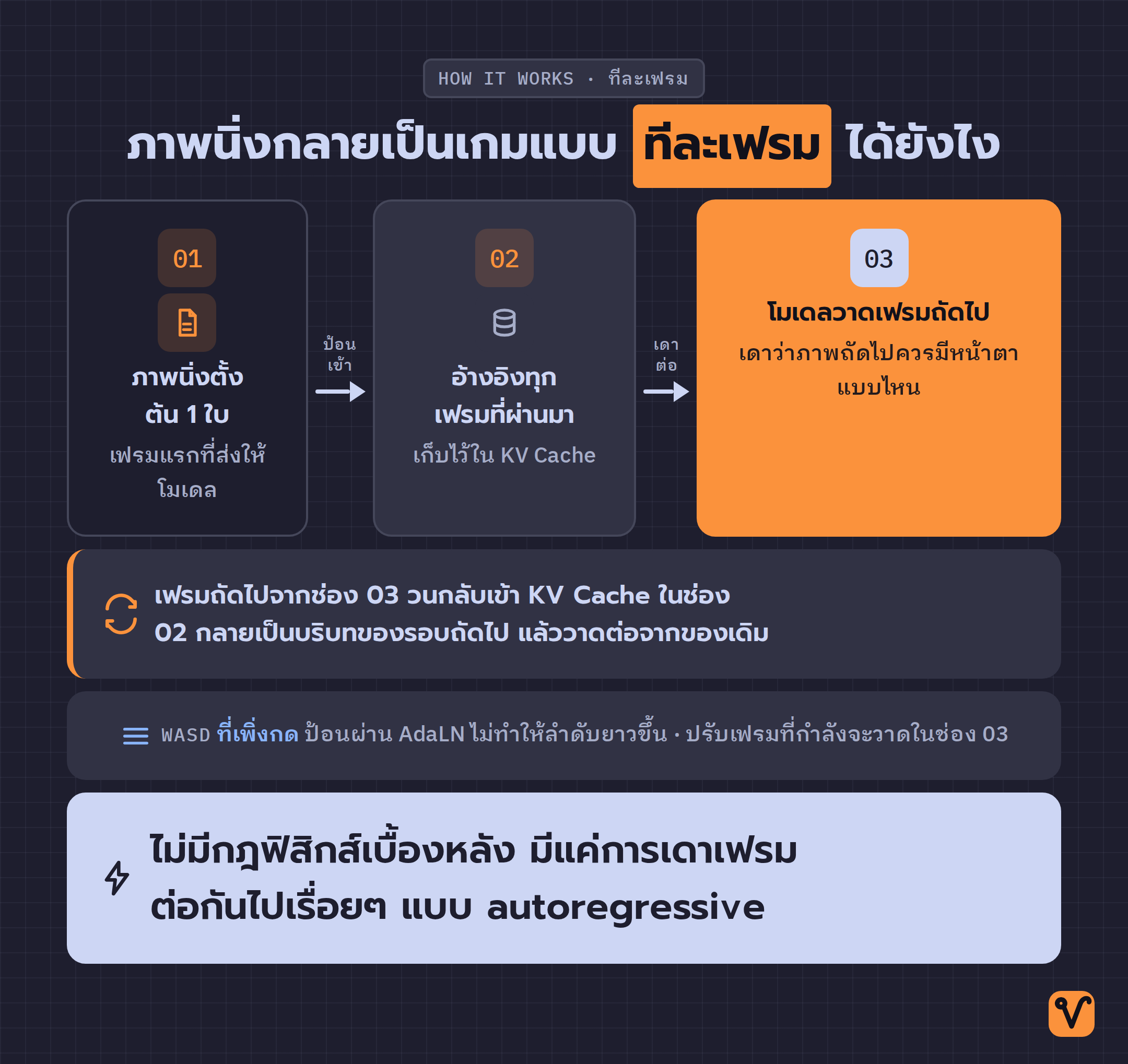
หัวใจของมันคือการรับภาพหนึ่งภาพมาเป็น seed frame หรือเฟรมตั้งต้น จากนั้นโมเดลจะสร้างเฟรมถัดไปขึ้นมาเองทีละเฟรม โดยอ้างอิงจากทุกเฟรมที่ผ่านมาและปุ่มที่ผู้เล่นกด
กลไกนี้ทำงานคล้ายกับ LLM หรือโมเดลภาษาแบบ ChatGPT มากกว่าที่คิด เพราะ LLM เดาคำถัดไปจากคำก่อนหน้าทั้งหมด ส่วน lucidml เดา "เฟรมถัดไป" จากเฟรมก่อนหน้าทั้งหมด มันเก็บความทรงจำของฉากที่ผ่านมาไว้ในสิ่งที่เรียกว่า KV Cache เหมือนที่ LLM เก็บบริบทของบทสนทนา แล้วค่อยๆ สร้างภาพต่อไปเรื่อยๆ แบบ autoregressive คือต่อทีละชิ้นจากของเดิม
ส่วนปุ่ม WASD ที่ผู้เล่นกดนั้น โมเดลไม่ได้รับเข้าไปเป็นคำสั่งอีกก้อนหนึ่ง แต่ใช้มันปรับการคำนวณของเฟรมที่กำลังจะวาดขึ้นมาผ่านเทคนิคที่ชื่อ AdaLN วิธีนี้ฉลาดตรงที่มันไม่ทำให้ลำดับข้อมูลยาวขึ้น โมเดลเลยไม่ช้าลงเพราะต้องรับคำสั่งทิศทาง
ทำไมตัวเล็กถึงสำคัญกว่าที่คิด

เรื่องน่าทึ่งจริงๆ ของงานนี้อยู่ที่ความเร็ว เพราะการสร้างภาพแบบ diffusion ขึ้นชื่อเรื่องช้า แต่ lucidml รุ่นขนาด 500M ทำได้ถึง 50-60 fps บน RTX 5090 ซึ่งเร็วพอจะเล่นได้ลื่นจริง ไม่ใช่แค่สร้างคลิปไว้ดูย้อนหลัง
ความเร็วนี้ไม่ได้มาฟรี ๆ มันมาจากการยอมตัดทอนหลายอย่างให้โมเดลเล็กพอจะรันในเครื่องเดียว เช่น บีบอัดภาพให้กระชับก่อนคำนวณ และเก็บความทรงจำแบบ sliding window คือเมื่อมีฉากใหม่เข้ามา ระบบจะทิ้งฉากที่เก่าที่สุดออกไป เพื่อไม่ให้กินหน่วยความจำจนเครื่องที่บ้านรับไม่ไหว
ของเดิมตัวใหญ่จนต้องรันบน datacenter งานนี้ทดลองทำมันให้เล็กพอจะรันบนการ์ดจอในห้องนอน
นี่คือมุมที่ต่างจากงานสร้างโลกเสมือนรุ่นก่อน ๆ ที่เน้นความสวยและความสมจริงโดยไม่สนว่าใช้เครื่องแบบไหน lucidml กลับตั้งโจทย์กลับด้าน คือเริ่มจากข้อจำกัดของเครื่องที่บ้านก่อน แล้วค่อยดูว่าทำให้ดีที่สุดได้แค่ไหนภายใต้กรอบนั้น
สอนมันด้วยการเล่นเกม
โมเดลแบบนี้ต้องการข้อมูลฝึกที่รู้ว่า "กดปุ่มนี้แล้วภาพควรเปลี่ยนยังไง" ซึ่งหายาก ผู้สร้างจึงแก้ด้วยการไปเก็บข้อมูลจากเกม GTA5 เอง ปล่อยให้ agent อัตโนมัติเดินเล่นในเกมแล้วบันทึกว่าปุ่มไหนทำให้ภาพขยับอย่างไร เพื่อสอนระบบให้เดาความสัมพันธ์ระหว่างปุ่มกับการเคลื่อนที่
แต่ถ้าฝึกจาก GTA5 อย่างเดียว โมเดลจะรู้จักแค่โลกแบบนั้น พอเจอภาพอื่นก็ไปต่อไม่เป็น ผู้สร้างเลยเสริมด้วยชุดวิดีโอขนาดใหญ่อีกชุดที่มีฉากหลากหลายทั้งทะเลทราย ทุ่งหญ้า และหิมะ ผลคือโมเดลเริ่มเดินเล่นในภาพธรรมชาติแปลกๆ ได้ดีขึ้น แม้จะยังไม่เก่งกับโครงสร้างซับซ้อนอย่างตึกหรือรถยนต์ก็ตาม
ของจริงยังไม่เนียน และนั่นคือเรื่องปกติ
ถ้าได้ลองเล่นจริง จะเห็นว่ามันยังไม่ใช่เกมในความหมายที่เราคุ้นเคย ภาพยังกระตุก และมีแสงวาบแปลก ๆ เป็นบางครั้ง ยิ่งเดินไปไกล ฉากก็ยิ่งเพี้ยนออกจากของเดิม เพราะระบบจำฉากเก่าได้จำกัด นอกจากนี้มันยังไม่มีกฎฟิสิกส์ และไม่รู้ว่าวัตถุที่เพิ่งเดินผ่านยังอยู่ตรงนั้นถ้าหันกลับไป
เรียกให้ตรงกว่า สิ่งนี้คือ "การสร้างวิดีโอที่โต้ตอบได้" มากกว่าจะเป็นเกมเต็มรูปแบบ มันไม่มี game engine คอยคำนวณกติกาเบื้องหลัง มีแค่โมเดลที่เดาว่าภาพถัดไปน่าจะหน้าตาแบบไหนเมื่อกดปุ่มนี้
แนวคิดหนึ่งที่ผู้สร้างตั้งความหวังไว้คือ ถ้าฝึกให้โมเดลจำฉากได้ยาวพอ ความทรงจำของมันอาจค่อย ๆ กลายเป็น "ความเข้าใจโลก" ที่เกิดขึ้นเองโดยไม่ต้องเขียนกฎฟิสิกส์ลงไปตรง ๆ ตอนนี้บริบทที่ใช้ฝึกยังสั้นเกินไปจนฉากเพี้ยนง่าย ปัญหานี้เลยเป็นโจทย์ใหญ่ที่ยังต้องแก้ต่อ
เทคนิคหลักที่ lucidml ใช้เป็นฐานเรียกว่า Diffusion Forcing ซึ่งเป็นเทคนิคของนักวิจัยกลุ่มอื่น เปิดให้ศึกษากันได้ที่ diffusion-forcing-transformer ส่วนการเอามันมาย่อให้รันบนการ์ดจอในเครื่องที่บ้านได้จริงคือส่วนที่งานชิ้นนี้ลงมือทดลองเอง
สิ่งที่มันบอกเรื่องอนาคต
สิ่งที่ควรจำจากงานนี้ไม่ใช่ตัวเลข fps แต่เป็นว่าใครทำมันได้ งานระดับสร้างโลกเสมือนแบบเรียลไทม์ที่เคยเป็นสนามของแล็บใหญ่ ตอนนี้นิสิตคนเดียวที่มีการ์ดจอเครื่องเล่นเกมก็เริ่มขยับงานแบบนี้ได้ แม้จะยังทำคนเดียว ทุนสนับสนุนหมดแล้ว และโค้ดยังกระจัดกระจายไม่ได้เปิดสาธารณะครบก็ตาม
เมื่อบีบโมเดลให้เล็กลงจนรันในเครื่องที่บ้านได้ สิ่งที่เคยต้องเช่าเซิร์ฟเวอร์ราคาแพงก็เริ่มย้ายมาอยู่ในมือคนทั่วไป และนั่นคือทิศทางที่น่าจับตามากกว่าตัวเดโมเองด้วยซ้ำ ยิ่งโลกเสมือนที่ AI สร้างมีขนาดเล็กลงเท่าไร มันก็ยิ่งเข้าใกล้เครื่องที่อยู่ตรงหน้าเรามากขึ้นเท่านั้น
ที่มา: โพสต์ Deep Neural Network that can turn any Image into a Playable Game! BUT LOCALLY, NOT ON DATACENTER ในชุมชน r/LocalLLaMA



