Mira · AI code reviewer แบบ open-source ที่ self-host ได้ทุกฟีเจอร์ โค้ดบริษัทไม่หลุดออกนอกเครื่อง
Mira คือ AI code reviewer แบบ open-source ที่รันบน infra ของเราเองได้ทั้งหมด โค้ดและประวัติรีวิวไม่ถูกส่งออกไปไหน น่าสนใจตรงที่มันแก้ปัญหาเดิมของเครื่องมือรีวิวสาย AI ส่วนใหญ่ ที่ต้องส่งโค้ดบริษัทออกไปอยู่บนเซิร์ฟเวอร์คนอื่น

Mira คือ AI code reviewer แบบ open-source ที่ออกแบบมาให้ self-host ได้ทุกฟีเจอร์ พูดง่าย ๆ คือช่วยรีวิว pull request ด้วย AI ได้เหมือนเครื่องมือดัง ๆ ทั่วไป แต่โค้ดบริษัทไม่ต้องวิ่งออกไปไหนเลย ตั้งแต่ระบบรีวิว การ index โค้ดทั้ง repo การสแกนช่องโหว่ ไปจนถึง dashboard ทุกอย่างรันอยู่บนเครื่องของเราเอง
จุดนี้ทำให้ Mira ต่างจากของเดิม เพราะเครื่องมือรีวิวสาย AI ที่ดัง ๆ เกือบทั้งหมดเป็นบริการแบบ SaaS เวลารีวิว diff (ส่วนของโค้ดที่เปลี่ยน) มันจึงส่งทั้ง diff และมักรวมโค้ดรอบ ๆ ออกไปประมวลผลบนเซิร์ฟเวอร์ของบริษัทเจ้าของเครื่องมือ โค้ดบริษัทเลยไปอยู่ในที่ที่เราคุมไม่ได้ ทีมที่มีข้อบังคับเรื่อง data residency หรือแค่ไม่อยากให้ source code ออกนอก infra ตัวเอง เครื่องมือแบบนั้นจึงใช้ไม่ได้ตั้งแต่ต้น Mira พลิกจุดนี้ให้ยังได้รีวิวด้วย AI เหมือนเดิม แต่โค้ดไม่ออกนอกบ้าน
ปัญหาไม่ใช่ว่า AI รีวิวไม่เก่ง แต่อยู่ที่โค้ดต้องเดินทาง

จุดที่ทีมจำนวนมากติดกำแพงเดียวกันไม่ใช่คุณภาพการรีวิว แต่เป็นเรื่องที่ต้องส่งโค้ดออกไป เมื่อเครื่องมือรีวิวเป็น SaaS การส่งโค้ดให้มันก็คือการส่งทรัพย์สินของบริษัทไปไว้บนเครื่องคนอื่น สำหรับสตาร์ทอัปทั่วไปอาจรับได้ แต่สำหรับองค์กรที่มีสัญญากับลูกค้าว่าโค้ดและข้อมูลจะอยู่ในประเทศหรืออยู่ใน cloud ของตัวเองเท่านั้น เงื่อนไขข้อนี้ทำให้เครื่องมือดี ๆ หลายตัวกลายเป็นตัวเลือกที่ใช้ไม่ได้
Mira เก็บทุกอย่างไว้กับเรา ตั้งแต่โค้ด · diff · embeddings · index · ประวัติการรีวิว ไปจนถึงข้อมูลช่องโหว่ ทั้งหมดบันทึกอยู่ในฐานข้อมูล SQLite หรือ Postgres ที่รันบน infra ของเราเอง ตัวมันไม่ phone-home คือไม่แอบส่งข้อมูลกลับไปหาผู้พัฒนา และไม่บังคับเปิด telemetry ที่สำคัญคือไม่มี paid tier ไม่มี license key และไม่ upsell แบบ SaaS ทุกความสามารถมาพร้อมในตัวตั้งแต่แรก ใต้ลิขสิทธิ์ Apache 2.0
เลือกสมองที่ใช้รีวิวได้เอง
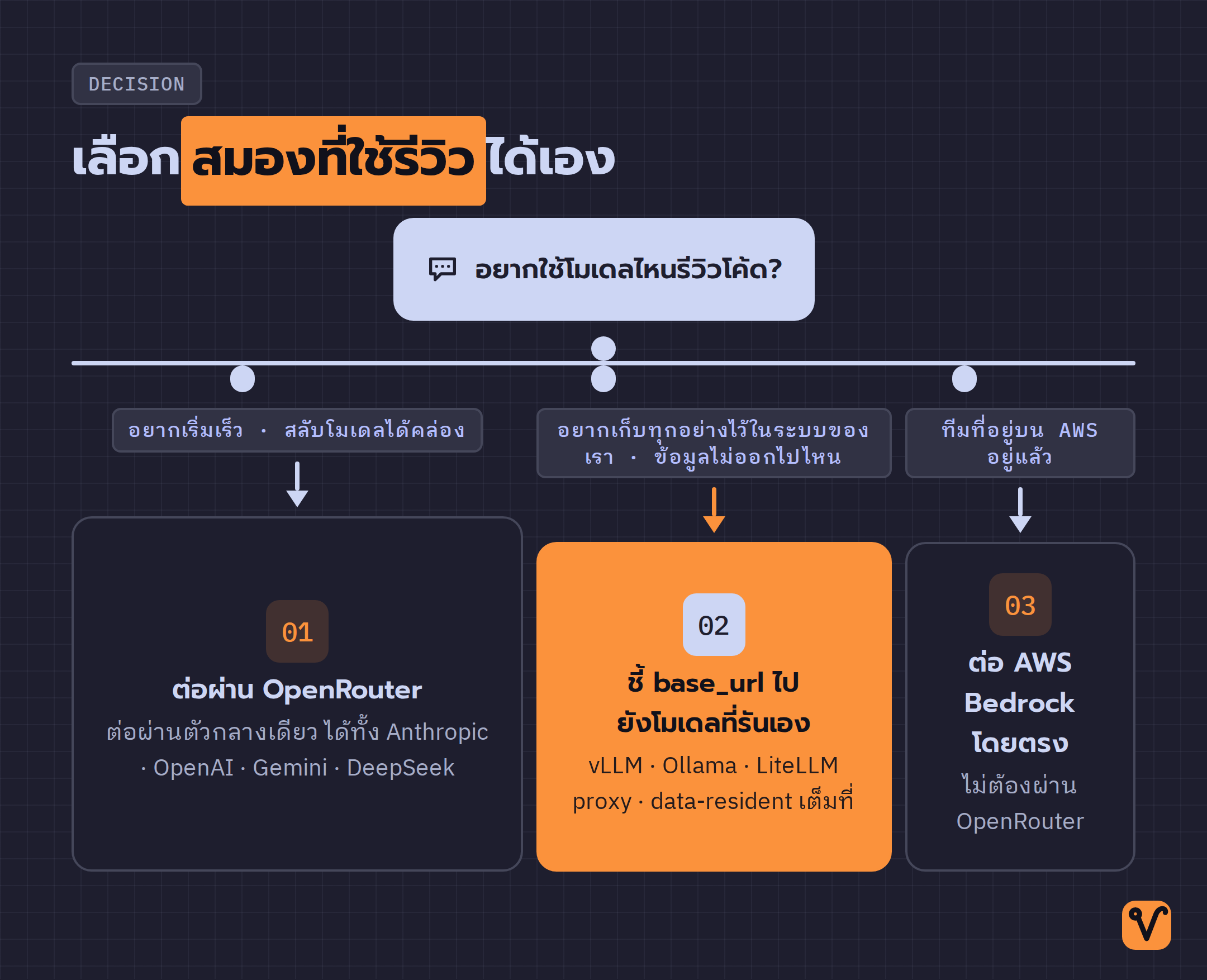
ถึง Mira จะเก็บข้อมูลไว้กับเรา แต่ตัวที่ "คิด" จริง ๆ ก็ยังเป็น LLM อยู่ดี จุดที่ Mira ยืดหยุ่นคือให้เราเลือกได้เองว่าจะใช้โมเดลไหนรีวิว ค่าเริ่มต้นจะต่อผ่าน OpenRouter ซึ่งเป็นตัวกลางที่เชื่อมไปยังโมเดลหลายเจ้าได้ในที่เดียว ทั้ง Anthropic · OpenAI · Google Gemini · DeepSeek
แต่ถ้าทีมไหนต้องการให้ทุกอย่างอยู่ในบ้านจริง ๆ แม้แต่ตัวโมเดลเอง Mira ก็เปิดให้ชี้ค่า llm.base_url ไปที่เซิร์ฟเวอร์โมเดลที่เรารันเองได้ เช่น vLLM · Ollama · หรือ LiteLLM proxy เท่านี้โมเดลก็รันอยู่บน infra ของเรา ข้อมูลไม่ต้องวิ่งออกไปหา API ของใครเลย เหมาะกับทีมที่ต้องการ data residency แบบเต็มขั้น ส่วนทีมที่อยู่บน AWS อยู่แล้ว Mira ก็ต่อ AWS Bedrock ได้ตรง ๆ โดยไม่ต้องผ่าน OpenRouter
การตั้งค่าทั้งหมดนี้อยู่ในไฟล์ mira.yaml ไฟล์เดียว โดยมีค่าโมเดลเริ่มต้นเป็น anthropic/claude-sonnet-4-6 สำหรับการรีวิว และ anthropic/claude-haiku-4-5 สำหรับงาน index ที่ต้องเร็วและถูกกว่า ส่วน secret อย่าง API key เก็บแยกไว้ในไฟล์ .env ต่างหาก
ติดตั้งเป็น GitHub App แล้วให้มันรีวิวเองทุก PR
Mira ทำงานโดยรันเป็น GitHub App ติดตั้งกับ repo ที่ต้องการครั้งเดียว จากนั้นทุก pull request ที่เปิดขึ้นมา Mira จะเข้าไปรีวิวให้อัตโนมัติ โดยไม่ต้องสั่งทีละครั้ง ความต่างจากเครื่องมือทั่วไปคือมันไม่ได้ดูแค่ diff แต่ index โค้ดทั้ง repo ไว้ก่อน เพื่อให้ LLM มี context รอบด้านพอจะเข้าใจว่าโค้ดที่เปลี่ยนไปกระทบกับส่วนอื่นอย่างไร
ถ้าอยากเริ่มลองวันนี้ ทำตามลำดับนี้ได้เลย
- สร้าง GitHub App ขึ้นมาตัวหนึ่ง กำหนด Webhook URL ให้สิทธิ์อ่าน-เขียน Pull Requests · Contents · Issues แล้ว generate private key เป็นไฟล์
.pem - Deploy ตัว Mira ด้วย Docker จาก image
ghcr.io/miracodeai/mira:latestพร้อมไฟล์mira.yamlและ.envที่เตรียมไว้ (จะ deploy บน Railway · Fly.io · หรือ Render ก็ได้) - ติดตั้ง GitHub App ตัวนั้นลงบน repo ที่ต้องการ แล้วลองเปิด PR ทดสอบ
ถ้ายังไม่อยากต่อกับ GitHub แต่อยากเห็นหน้าตาผลรีวิวก่อน ก็ลองรันบนเครื่องตัวเองด้วยคำสั่งเดียวได้
git diff HEAD~1 | mira review --stdin --dry-run --config mira.yamlหลังติดตั้งแล้ว เวลาอยากถาม Mira เพิ่มเกี่ยวกับโค้ดใน PR นั้น ก็พิมพ์คอมเมนต์ขึ้นต้นด้วย @miracodeai ตามด้วยคำถามได้เลย มันจะตอบกลับในเธรดเหมือนคุยกับเพื่อนร่วมทีมคนหนึ่ง ข้อจำกัดที่ต้องรู้ไว้คือ ตอนนี้ Mira รองรับเฉพาะ GitHub เท่านั้น ส่วน GitLab · Bitbucket · Gitea ยังอยู่ใน roadmap
มากกว่ารีวิว คือเห็นภาพ dependency ทั้ง org
นอกจากรีวิวราย PR แล้ว Mira ยังมี dashboard ในตัวที่ทำให้เห็นภาพรวมของทั้ง organization ตรงนี้คือส่วนที่หลายทีมจะได้ประโยชน์โดยไม่คาดคิด มันเก็บ inventory ว่า repo ไหนใช้ package ตัวไหนเวอร์ชันอะไรบ้าง พอมี CVE ใหม่ออกมา มันจะ poll ข้อมูลช่องโหว่จากฐานข้อมูลสาธารณะ OSV.dev ทุกชั่วโมง แล้วแจ้งเตือนเป็นราย dependency พร้อมระดับความรุนแรง ลิงก์ advisory และเวอร์ชันที่แก้แล้ว
ลึกไปอีกขั้นคือกราฟ blast-radius ก่อนแก้โค้ดส่วนไหน เราดูได้ว่ามี file หรือ repo ไหนบ้างที่พึ่งพา symbol นั้นอยู่ จะได้รู้ล่วงหน้าว่าการเปลี่ยนครั้งนี้จะกระเทือนถึงตรงไหน และเพราะ Mira ถือ LLM key ไว้เอง ตัวเลข cost กับ token ที่เห็นบน dashboard จึงเป็นยอดใช้จ่ายจริงต่อ repo ต่อ model ไม่ใช่ค่าประมาณ
ได้รีวิวด้วย AI เหมือนเดิม แต่โค้ดไม่ต้องเดินทางออกไปไหนเลย
ยิ่งใช้ยิ่งฉลาดขึ้น แต่อย่าเพิ่งเชื่อตัวเลขทั้งหมด
อีกจุดที่ออกแบบมาดีคือการกรองเสียงรบกวน เพราะปัญหาคลาสสิกของ AI reviewer คือมันคอมเมนต์เยอะเกินจนคนเลิกอ่าน Mira จัดการด้วยการตั้ง confidence threshold · ตัดคอมเมนต์ซ้ำ · เรียงตามความรุนแรง และจำกัดจำนวนคอมเมนต์ต่อ PR ค่าเริ่มต้นคือต้องมีคะแนนความเชื่อมั่นเกิน 0.7 และคอมเมนต์ไม่เกิน 5 รายการต่อ PR ยิ่งไปกว่านั้นยังมี learning loop ที่เรียนรู้จากคอมเมนต์ที่ทีมปฏิเสธ และจากรูปแบบการรีวิวของคนจริงบน PR ที่ merge ไปแล้ว เพื่อสร้างกฎใหม่ที่ช่วยลดคอมเมนต์ในประเด็นที่ทีมไม่ให้ความสำคัญ
ส่วนเรื่อง benchmark ต้องพูดกันตรง ๆ ทาง Mira เคลมว่าตัวเองเป็นเครื่องมือที่ "เร็วที่สุด" และเป็นตัวเดียวที่อยู่บนเส้น Pareto frontier ของความเร็วเทียบกับคุณภาพ โดยอ้างว่าเครื่องมือที่ทำคะแนน F1 ได้สูงกว่า ล้วนใช้เวลาต่อ PR มากกว่าหลายเท่าตัว ตัวเลขเหล่านี้น่าสนใจ แต่ต้องดูที่มาด้วย เพราะเป็นผลที่ทีมผู้พัฒนา Mira วัดเอง บน dataset ขนาด 50 PR และใช้ Claude Sonnet 4.5 เป็นตัวตัดสินคะแนน ไม่ใช่ผลทดสอบจากหน่วยงานกลางที่เป็นอิสระ ดังนั้นใช้เป็นข้อมูลประกอบได้ แต่อย่าเพิ่งยึดเป็นคำตัดสินสุดท้าย
ความน่าสนใจที่แท้จริงของ Mira จึงไม่ได้อยู่ที่ตัวเลขในตาราง แต่อยู่ที่คำถามว่าทีมยอมแลกอะไรกับอะไร เครื่องมือ SaaS อาจตั้งค่าง่ายกว่าและไม่ต้องดูแล server เอง แต่แลกด้วยการที่โค้ดต้องออกไปอยู่ที่อื่น ส่วน Mira ต้องให้เราลงแรง deploy และดูแลเองมากขึ้น แลกกับโค้ดทุกบรรทัดที่ยังอยู่ในกำมือเราตลอด สำหรับทีมที่โค้ดห้ามหลุด นั่นไม่ใช่ความยุ่งยาก แต่คือเงื่อนไขที่ขาดไม่ได้
ที่มา:
ชอบเรื่องแนวนี้ มีอีบุ๊คฟรีให้อ่านต่อ
สร้าง Claude Skill แบบไม่ต้องรู้โค้ด คู่มือสร้าง Claude Skill ของคุณเองด้วยการคุยกับ Claude Code เป็นภาษาไทย
กดสมัครแล้วเราจะส่งเทคนิค AI และของแจกใหม่ๆ ให้ทางอีเมล เลิกรับได้ตลอด
Claude Cowork · The Business Playbook

ฉบับภาษาไทย 15 บท เรียนรู้ผ่านโปรเจกต์จำลองต่อเนื่องทั้งเล่ม ตั้งแต่ตั้งค่า Workspace จัดการไฟล์ เชื่อมแอป ตั้งระบบอัตโนมัติ จนถึงสร้าง Plugin


