Mistral OCR 4 (Document AI) อ่านเอกสารแล้วแยกหัวข้อ-ตาราง-รูปให้เลย ทำคะแนน OlmOCRBench 85.20 สูงสุด
Mistral OCR 4 หรือชื่อผลิตภัณฑ์ Document AI คือโมเดลอ่านเอกสารตัวใหม่ที่ไม่ได้ดึงแค่ตัวอักษร แต่ตีกรอบแต่ละส่วนบนหน้าแล้วแยกประเภทให้ ส่งรูปเอกสารเข้าไปครั้งเดียวก็ได้ข้อมูลที่มีโครงสร้างกลับมาใช้ต่อได้เลย

Mistral OCR 4 (ชื่อผลิตภัณฑ์ว่า Document AI) คือโมเดลอ่านเอกสารตัวใหม่ที่ Mistral เพิ่งเปิดตัวเมื่อวันที่ 23 มิถุนายน 2026 และเปิดให้ใช้งานได้ตั้งแต่วันแรก จุดที่ทำให้ต่างจาก OCR ที่เราคุ้นกันคือ มันไม่ได้แค่กวาดตัวอักษรออกมาเป็นก้อนข้อความยาว ๆ แต่ยังอ่าน "โครงสร้าง" ของหน้าเอกสารด้วย ส่วนไหนเป็นหัวข้อ ตรงไหนเป็นตาราง ตรงไหนเป็นรูป มันแยกให้เป็นส่วน ๆ
พูดให้เห็นภาพง่าย ๆ คือส่งรูปเอกสารหรือไฟล์เข้าไปครั้งเดียว แล้วได้ข้อมูลที่จัดโครงสร้างมาให้พร้อมใช้กลับมาเลย ไม่ต้องมานั่งคีย์ทีละช่องเอง สำหรับคนที่ต้องดึงข้อมูลจากใบเสร็จ สลิปโอนเงิน หรือเอกสารกองโต ๆ ทุกวัน นี่คือความต่างที่รู้สึกได้จริง
OCR ธรรมดาได้แค่ตัวอักษร อันนี้ได้ทั้งหน้า

OCR แบบที่เราใช้กันมานานทำหน้าที่หลักคือเปลี่ยน "ภาพของตัวอักษร" ให้กลายเป็น "ตัวอักษรที่คอมพิวเตอร์อ่านได้" ผลลัพธ์คือข้อความเรียงต่อกันเป็นก้อน มันไม่รู้ว่าส่วนไหนเป็นหัวข้อ ส่วนไหนเป็นช่องในตาราง หรือส่วนไหนเป็นคำอธิบายใต้รูป เพราะเห็นแค่ตัวอักษร ไม่เห็นการจัดวางของหน้านั้น
คนที่เคยเอารูปใบกำกับภาษีไปแปลงเป็นข้อความน่าจะเข้าใจปัญหานี้ดี เพราะสิ่งที่ได้กลับมามักเป็นตัวเลขกับตัวหนังสือปนกันมั่ว ตารางที่เคยเป็นแถวเป็นช่องกลายเป็นบรรทัดยาวพรืด สุดท้ายก็ต้องมานั่งจัดเรียงเองอยู่ดี
Document AI ทำงานคนละแบบ มันมองเอกสารทั้งหน้า แล้วตีกรอบรอบแต่ละส่วน (เรียกว่า bounding box) จากนั้นบอกว่ากรอบนั้นคืออะไร แยกได้ห้าประเภทหลัก ได้แก่หัวข้อ (title) หัวข้อรอง (subtitle) ข้อความปกติ (text) รูปภาพ (image) และตาราง (table) แต่ละกรอบยังมีคะแนนความมั่นใจ (confidence score) กำกับมาด้วย เพื่อบอกว่าโมเดลมั่นใจในการอ่านส่วนนั้นมากแค่ไหน
"ก้าวเดียว" หมายความว่าอย่างไร
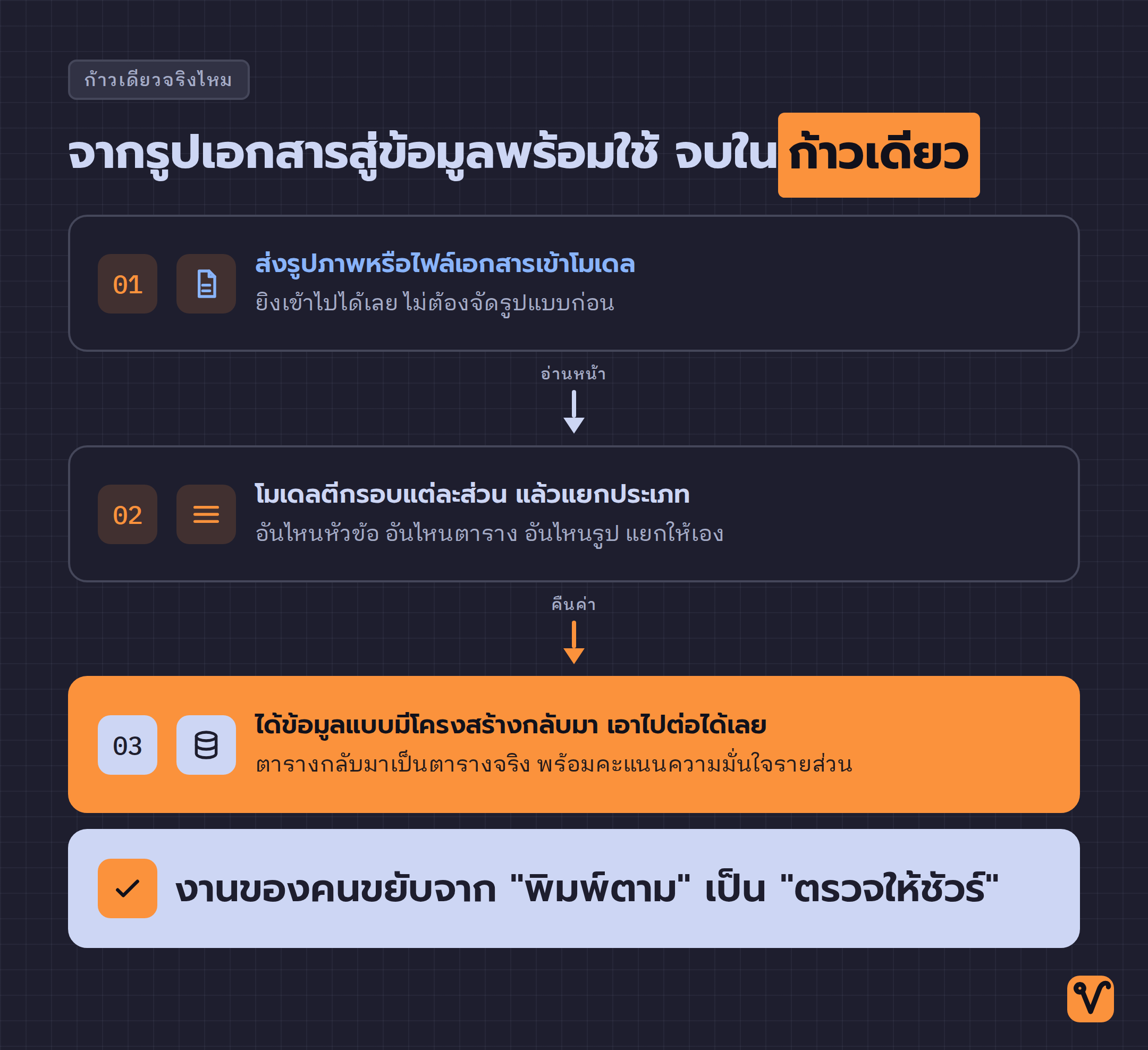
ลองนึกถึงงานเดิมที่เราเคยทำกัน เปิดรูปสลิป มองหาเลขที่บัญชี พิมพ์ลงตาราง มองหายอดเงิน พิมพ์ลงอีกช่อง มองหาวันที่ พิมพ์อีกที วนแบบนี้ทีละใบ ทีละช่อง เอกสารหนึ่งปึกก็หมดไปครึ่งวัน
ขั้นตอนของ Document AI สั้นกว่านั้นมาก
- ส่งรูปภาพหรือไฟล์เอกสารเข้าโมเดล
- โมเดลจับแต่ละส่วนของหน้าเป็นกรอบ แล้วแยกประเภทให้ว่าอันไหนหัวข้อ อันไหนตาราง อันไหนรูป
- ได้ข้อมูลที่จัดเป็นโครงสร้างกลับมา พร้อมคะแนนความมั่นใจรายส่วน เอาไปต่อยอดในระบบของตัวเองได้เลย
ความหมายของ "ก้าวเดียว" อยู่ตรงนี้ ตารางในใบเสร็จกลับมาเป็นตารางจริง ๆ ไม่ใช่ข้อความที่ต้องมานั่งแกะว่าช่องไหนคู่กับช่องไหน คนที่ทำงานคีย์ข้อมูลจึงรู้สึกถึงความต่าง เพราะส่วนที่กินเวลาที่สุดไม่ใช่การ "อ่าน" เอกสาร แต่เป็นการ "จัดข้อมูลให้เข้าช่อง" และนั่นคือสิ่งที่โมเดลช่วยทำให้
ตัวเลขที่ Mistral เอามาเคลม
Mistral บอกว่า OCR 4 ทำคะแนนสูงสุดบน OlmOCRBench ที่ 85.20 ซึ่งเป็นชุดทดสอบสาธารณะที่ใช้วัดความแม่นยำในการอ่านเอกสาร และยังทำคะแนนนำในการทดสอบความสามารถหลายภาษาที่ Mistral วัดเองภายใน
จุดที่น่าสนใจกว่าตัวเลขเฉย ๆ คือ Mistral ระบุว่าโมเดลทำได้ดีที่สุดในกลุ่ม "ภาษาที่มีทรัพยากรน้อย" (rare and low-resource languages) ซึ่งเป็นกลุ่มภาษาที่ระบบอื่น ๆ ส่วนใหญ่มักทำได้แย่ เพราะมีข้อมูลฝึกน้อยกว่าภาษาหลักอย่างภาษาอังกฤษมาก
เริ่มลองได้ทางไหนบ้าง
ข้อดีอย่างหนึ่งของการเปิดตัวรอบนี้คือเปิดให้ใช้หลายทางพร้อมกันตั้งแต่วันแรก ไม่ต้องรอคิว แต่ละช่องทางเหมาะกับคนคนละแบบ
- API สำหรับคนที่อยากเชื่อมเข้าระบบหรือแอปของตัวเอง เอาไปวางในขั้นตอนการประมวลผลเอกสารอัตโนมัติได้
- Document AI ใน Mistral AI Studio สำหรับคนที่อยากลองหน้าเว็บก่อน ไม่ต้องเขียนโค้ด เหมาะกับการทดสอบว่ามันอ่านเอกสารของเราได้ดีไหมก่อนลงทุนต่อ
- Amazon SageMaker และ Microsoft Foundry สำหรับองค์กรที่ทำงานบนคลาวด์สองเจ้านี้อยู่แล้ว เรียกใช้จากที่เดิมได้เลย
- Snowflake Parse Document กำลังจะตามมาเร็ว ๆ นี้ สำหรับคนที่ใช้ Snowflake เป็นคลังข้อมูล
ถ้าให้เลือกแบบเริ่มจากศูนย์ คนที่ไม่ใช่สายเทคควรเริ่มจากหน้า Document AI ใน Mistral AI Studio เพราะลองได้ทันทีโดยไม่ต้องตั้งระบบอะไร ส่วนคนที่จะเอาไปใช้กับงานปริมาณมากค่อยขยับไปทาง API ทีหลัง
ถ้าเอกสารห้ามออกนอกบริษัท
อีกทางที่ Mistral เปิดไว้คือ self-host บน single container หมายความว่ารันโมเดลไว้ในเครื่องหรือสภาพแวดล้อมของตัวเองได้ทั้งหมด Mistral ย้ำเองว่าทำแบบนี้แล้วเอกสารจะไม่ต้องออกไปไหนนอกสภาพแวดล้อมของเรา
ตรงนี้สำคัญกับคนที่ต้องจัดการเอกสารอ่อนไหว เช่น ข้อมูลลูกค้า เอกสารการเงิน หรือสัญญา ซึ่งนโยบายห้ามส่งออกไปประมวลผลข้างนอก การติดตั้งแบบจบในคอนเทนเนอร์เดียวช่วยให้ทีมไอทีดูแลง่ายขึ้น แต่ต้องแลกกับเครื่องที่แรงพอจะรันโมเดลเอง และคนที่ตั้งระบบเป็น ไม่ใช่เปิดใช้แล้วได้เลยเหมือนหน้าเว็บ
ของใหม่ที่คุ้มลอง
สิ่งที่เปลี่ยนไปจริง ๆ ไม่ใช่เรื่องที่ AI "อ่าน" เอกสารได้แม่นขึ้น เพราะ OCR อ่านตัวอักษรได้ดีมานานแล้ว จุดที่เปลี่ยนคือมันเริ่ม "เข้าใจ" ว่าเอกสารหนึ่งหน้าประกอบด้วยอะไรบ้าง และอะไรอยู่ตรงไหน
งานที่เคยกินเวลาที่สุดของการคีย์ข้อมูลไม่ใช่การอ่านตัวหนังสือ แต่เป็นการตัดสินใจว่าตัวเลขก้อนนี้ควรอยู่ช่องไหน เมื่อโมเดลเริ่มทำส่วนนั้นแทนได้ งานของคนก็ขยับจาก "พิมพ์ตาม" เป็น "ตรวจให้ชัวร์"
ที่มา:
- โพสต์ Mistral AI (@MistralAI) on X จาก Mistral AI
- โพสต์ Mistral AI (@MistralAI) on X จาก Mistral AI



