slopo · เครื่องมือ open-source ที่ใช้ embedding ไล่จับโค้ดซ้ำแบบเนียนๆ ที่ grep หาไม่เจอ
slopo คือเครื่องมือ command line ที่ใช้ embedding ไล่หาโค้ดซึ่งเขียนคล้ายกันจนน่าจะซ้ำ แม้จะแยกอยู่คนละไฟล์คนละโมดูล จุดที่น่าสนใจคือมันไม่ตัดสินเองว่าคู่ไหนซ้ำ แต่ส่งรายชื่อผู้ต้องสงสัยต่อให้ AI coding agent ไปยืนยันและเก็บกวาด

slopo คือเครื่องมือ command line ตัวเล็กๆ ที่ทำเรื่องเดียว คือไล่หาโค้ดในโปรเจกต์ที่เขียนคล้ายกันจนน่าจะซ้ำกัน แม้จะกระจายอยู่คนละไฟล์ คนละมุมของโปรเจกต์ก็ตาม สิ่งที่ทำให้มันต่างจากเครื่องมือหาโค้ดซ้ำทั่วไปคือ slopo ไม่ได้ค้นข้อความแบบเทียบตัวอักษรตรงๆ แต่แปลงโค้ดออกมาเป็น "ความหมาย" ด้วย embedding ซึ่งเป็นเทคโนโลยีตัวเดียวกับที่อยู่เบื้องหลังโมเดล AI ทุกวันนี้
จุดที่ slopo เล็งไว้ไม่ใช่โค้ดก๊อป-วางแบบเป๊ะทุกตัวอักษร เพราะแบบนั้นเครื่องมือเดิมๆ จับได้อยู่แล้ว และไม่ใช่โค้ดซ้ำที่วางอยู่ติดกันจนคนหรือ AI กวาดตาก็เห็น แต่เป็นโค้ดที่เขียนคล้ายกันแต่ไม่เป๊ะ แถมยังอยู่ไกลกันคนละโมดูล โค้ดแบบนี้แหละที่เล็ดลอดสายตาไปเรื่อยๆ จนค่อยๆ สะสมเป็นภาระค้างคาที่แก้ทีหลังยากขึ้นเรื่อยๆ โค้ดทั้งหมดเป็น open-source อยู่ที่ github.com/rafal-qa/slopo และผู้สร้างเพิ่งเอาไปให้ชุมชนนักพัฒนาลองใช้บน Hacker News จนมีคนเข้าไปถกกันพอสมควร
โค้ดซ้ำที่อันตรายที่สุด คือแบบที่ไม่มีใครเห็น
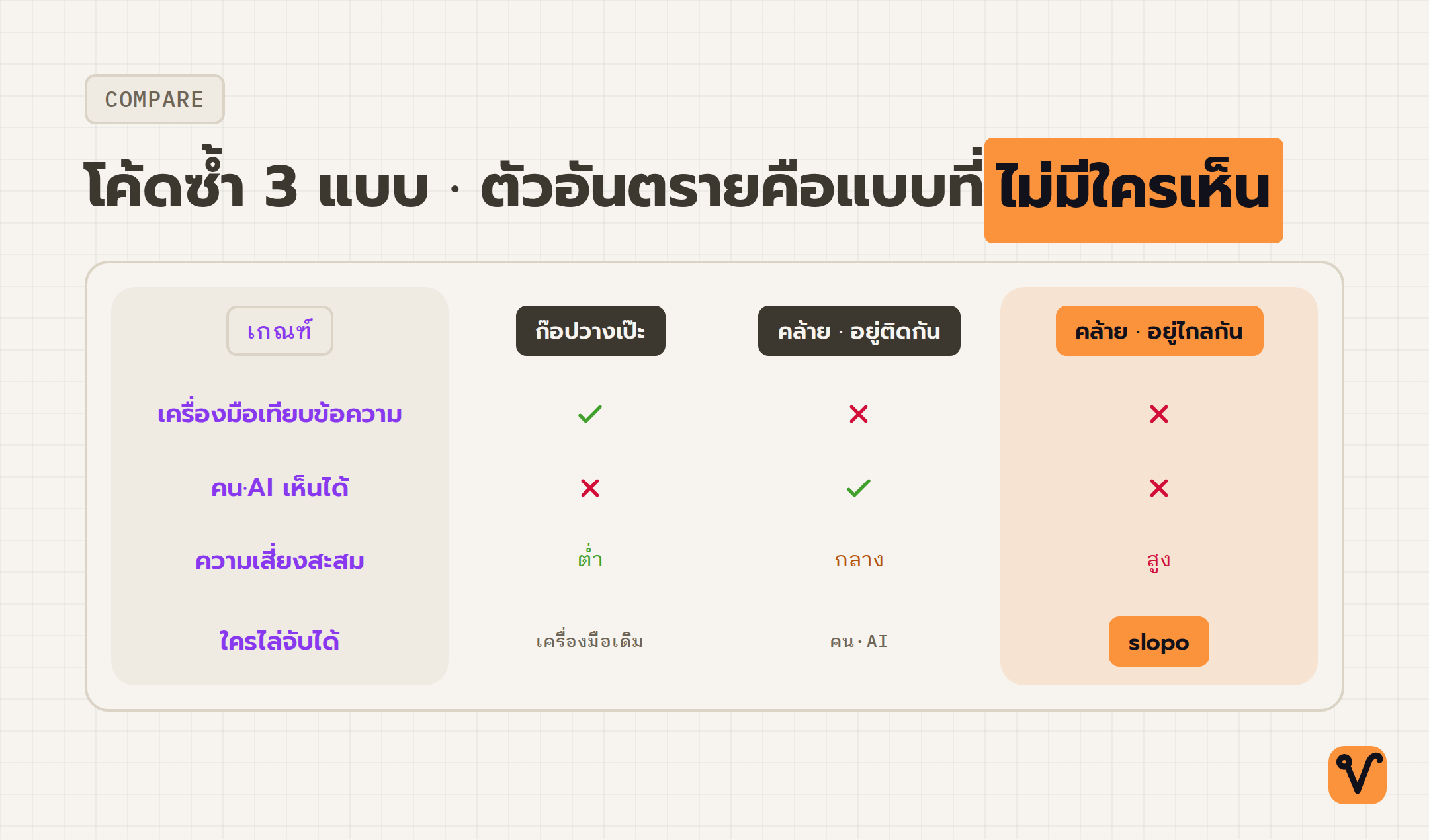
ลองแยกโค้ดซ้ำออกเป็นสามแบบ จะเห็นภาพชัดขึ้น แบบแรกคือก๊อปมาวางเป๊ะทุกบรรทัด อันนี้ตัวจับซ้ำแบบเทียบข้อความจับได้สบายอยู่แล้ว แบบที่สองคือโค้ดคล้ายกันที่บังเอิญอยู่ใกล้กัน เปิดไฟล์เดียวก็เห็นสองฟังก์ชันที่หน้าตาคล้ายกันมาก คนรีวิวหรือ AI ที่อ่านไฟล์นั้นก็สังเกตเห็นเอง
แบบที่สามต่างหากที่เป็นปัญหาจริง คือโค้ดที่เขียนคล้ายกันแต่แก้ไปนิดหน่อย แล้วดันอยู่ต่างไฟล์ต่างโมดูลกัน แถมห่างกันหลายชั้นในไดเรกทอรี ไม่มีใครเปิดสองจุดนี้ขึ้นมาเทียบกันพร้อมกัน มันเลยรอดสายตาไปได้เรื่อยๆ พอถึงเวลาต้องแก้บั๊กหรือปรับ logic ทีหนึ่ง ก็ต้องไล่แก้หลายจุดโดยไม่รู้ว่ามีจุดไหนตกหล่นไปบ้าง นี่คือช่องว่างที่ slopo ตั้งใจเข้าไปอุด
อ่านความหมายของโค้ด ไม่ใช่แค่ตัวอักษร
วิธีทำงานของ slopo เริ่มจากแบ่งโค้ดทั้งโปรเจกต์ออกเป็น "หน่วยโค้ด" ทีละชิ้น ซึ่งก็คือฟังก์ชันหรือเมธอดแต่ละตัว รวมถึงฟังก์ชันซ้อน (nested function), anonymous function, lambda และ closure ที่นับเป็นชิ้นแยกของตัวเอง จากนั้นจะส่งแต่ละชิ้นไปแปลงเป็น embedding คือเวกเตอร์ตัวเลขชุดหนึ่งที่จับความหมายของโค้ดเอาไว้ โค้ดที่ทำงานคล้ายกันจะได้เวกเตอร์ที่อยู่ใกล้กันในเชิงคณิตศาสตร์
พอมีเวกเตอร์ของทุกชิ้นแล้ว slopo ก็วัดว่าแต่ละคู่คล้ายกันแค่ไหนด้วย cosine similarity แล้วจับคู่ที่คล้ายกันถึงเกณฑ์มารวมเป็นคลัสเตอร์ ผลลัพธ์ที่ได้คือรายการคลัสเตอร์ของโค้ดที่คล้ายกัน แล้วเรียงอันดับด้วยสองเกณฑ์ คือความคล้ายและระยะห่างในโปรเจกต์ คู่ที่อยู่ไกลกันจะขึ้นไปอยู่อันดับสูงกว่า เพราะเป็นจุดที่คนสังเกตยากที่สุด ตรงกับปัญหาแบบที่สามพอดี
มีจุดหนึ่งที่ต้องเข้าใจให้ตรง คือโค้ดที่ให้ผลเหมือนกันแต่เขียนคนละแบบสิ้นเชิง เวกเตอร์ของโค้ดสองแบบนั้นจะอยู่ห่างกัน ทำให้ slopo ไม่จับคู่ให้ และนี่คือสิ่งที่ตั้งใจออกแบบไว้แต่แรก ไม่ใช่ข้อจำกัดที่คาดไม่ถึง เพราะเป้าหมายของมันคือหาโค้ดที่หน้าตาคล้ายกัน ไม่ใช่เดาว่าโค้ดสองก้อนที่เขียนต่างกันลิบทำงานเหมือนกันหรือเปล่า ส่วนโค้ดที่ก๊อปมาเป๊ะๆ หลายจุด slopo ก็รายงานให้เช่นกัน เพียงแต่โชว์โค้ดครั้งเดียวแล้วลิสต์ทุกตำแหน่งที่เจอ
ลองรันจริงในไม่กี่คำสั่ง
ขั้นตอนใช้งานจริงสั้นกว่าที่คิด เริ่มจากติดตั้งด้วยคำสั่งเดียว
uv tool install slopo
ตรงนี้เราติดตั้ง slopo ผ่าน uv ซึ่งเป็นตัวจัดการแพ็กเกจของ Python ข้อดีคือ uv จะจัดการ virtual environment แยกให้เอง ไม่ต้องไปลง Python ต่างหากให้ยุ่ง จากนั้นก็รันคำสั่งตามลำดับ
slopo initสร้างไฟล์ config พร้อมคำอธิบายในตัว อย่างน้อยต้องบอกว่าจะวิเคราะห์โค้ดในไดเรกทอรีไหน และจะใช้ embedding model ตัวใดslopo indexไล่อ่านโค้ดแล้วแบ่งเป็นหน่วยย่อยๆslopo embedส่งแต่ละหน่วยไปแปลงเป็นเวกเตอร์slopo analyzeประมวลผลออกมาเป็นรายงานคลัสเตอร์
รายงานที่ได้จะมีไฟล์ index.md ที่ลิสต์คลัสเตอร์ทั้งหมดไว้ให้ไล่ดู ผู้สร้างแนะนำให้รันรอบแรกแล้วเปิด index.md ดูก่อน ถ้าผลออกมาเยอะไปหรือน้อยไป ก็ปรับ threshold และตัดไดเรกทอรีที่ไม่อยากวิเคราะห์ เช่นโฟลเดอร์ tests ทิ้ง จากนั้นให้ AI coding agent ช่วยกรองคลัสเตอร์ที่ดูแล้วไม่ใช่โค้ดที่ซ้ำกันจริงออกไป แล้วเก็บ hash ของคลัสเตอร์พวกนั้นลงไฟล์ slopo.ignore.txt เมื่อรันใหม่อีกรอบ รายงานก็จะเหลือแต่คลัสเตอร์ที่ยังไม่ได้รีวิว
ไฟล์ slopo.ignore.txt นี้ commit ขึ้น git ได้ ทั้งทีมจึงใช้รายการที่รีวิวแล้วชุดเดียวกันได้ พอมีคลัสเตอร์ใหม่โผล่มา ก็จะแสดงในรายงานอีก ส่วนไฟล์ config ที่ไม่มี API key ก็ commit ได้เช่นกัน มีแค่ไฟล์ slopo.db ที่เป็นข้อมูลเฉพาะเครื่องเราซึ่งห้าม commit และ slopo ยังรองรับ incremental re-index คืออัปเดตเฉพาะไฟล์ที่เปลี่ยน ไม่ต้องคำนวณใหม่ทั้งโปรเจกต์ทุกครั้ง
ข้อควรรู้ก่อนติดตั้ง
แต่ก่อนติดตั้งไปลองใช้ มีข้อจำกัดที่ต้องรู้ไว้ก่อน อย่างแรกคือ slopo ไม่ได้คำนวณ embedding บนเครื่องเราเองทั้งหมด มันต้องต่อกับผู้ให้บริการ embedding ภายนอกที่ต้องมี API key เช่น Voyage AI หรือเจ้าไหนก็ได้ที่เข้ากันกับ LiteLLM แปลว่าระบบจะส่งโค้ดของเราออกไปคำนวณที่ฝั่ง provider ไม่ได้ประมวลผลอยู่ในเครื่องเราอย่างเดียว และมีค่าใช้จ่ายตามปริมาณการเรียก API จุดนี้สำคัญทั้งเรื่องความเป็นส่วนตัวของโค้ดและค่าใช้จ่าย ใครทำงานกับโค้ดที่ห้ามหลุดออกนอกองค์กรต้องคิดให้ดีก่อน (จะตั้ง API key เป็น env var หรือแยกใส่ไฟล์ .env ไว้ก็ได้ จะได้ไม่ติดไปกับโค้ด)
อีกเรื่องคือ slopo ยังเป็นเครื่องมือใหม่และตัวเล็ก ตัวอย่างในเอกสารยังเป็นเวอร์ชัน v0.2.0 อยู่เลย ตอนนี้รองรับแปดภาษา ได้แก่ Python · TypeScript · JavaScript · Java · Kotlin · C# · Go · Rust และอย่างที่บอกไปแล้วว่ามันจับได้แค่โค้ดที่หน้าตาคล้ายกัน ไม่ได้จับตรรกะที่เหมือนกันแต่เขียนคนละสไตล์ ดังนั้นอย่าเพิ่งคาดหวังว่ามันจะกวาดโค้ดซ้ำได้ครบทุกชนิด
slopo หาผู้ต้องสงสัย · AI เป็นคนตัดสิน
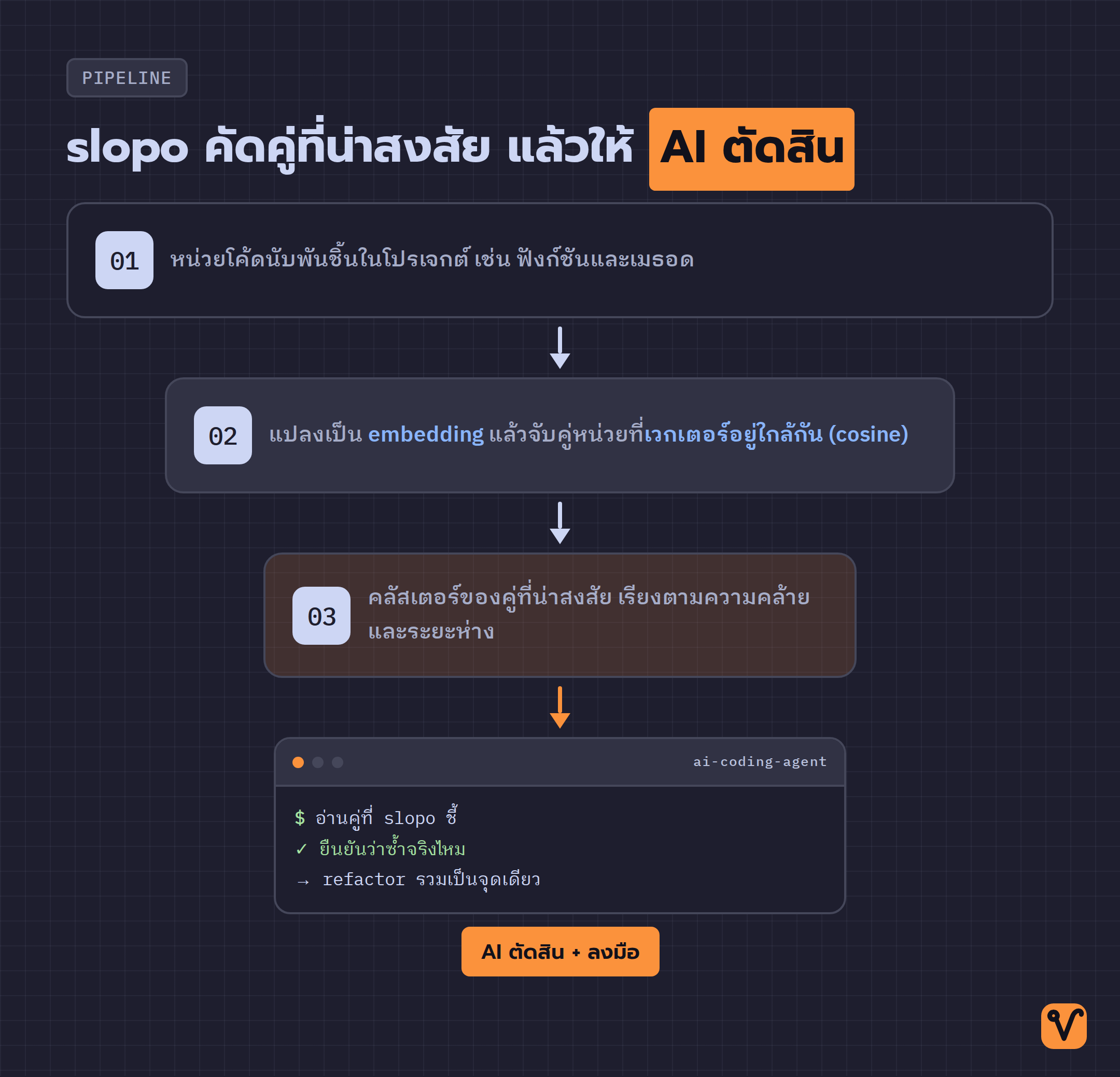
จุดที่ทำให้ slopo น่าสนใจในเชิงวิธีทำงานยุคใหม่ คือมันไม่ได้ตั้งใจให้เป็นเครื่องมือที่ทำงานจบในตัวเอง README บอกไว้เลยว่าผลลัพธ์แบบคลัสเตอร์มีไว้เพื่อส่งต่อเป็น input ให้ AI coding agent ไปตรวจว่าคู่ไหนซ้ำจริง แล้วสั่งให้ agent ลงมือ refactor ต่อ พูดง่ายๆ คือ slopo รับหน้าที่คัดผู้ต้องสงสัยจากทั้งโปรเจกต์ให้เหลือแค่ไม่กี่คู่ ส่วน AI ที่มี context ของโปรเจกต์อยู่แล้วมีหน้าที่ยืนยันและลงมือแก้
ที่น่าสนใจคือผู้สร้างเคยคิดจะใส่ขั้นตอนให้ LLM ช่วยแยกแยะว่าคู่ไหนซ้ำจริงไว้ในตัวเครื่องมือเองด้วยซ้ำ แต่สุดท้ายเลือกไม่ทำ เหตุผลคือ coding agent ที่เห็นภาพรวมทั้งโปรเจกต์น่าจะตัดสินได้ดีกว่า จึงยอมแลกกับการที่ผลลัพธ์อาจไม่คงเส้นคงวาเป๊ะทุกครั้ง เพื่อให้ได้ผลที่เข้ากับบริบทจริงมากกว่า
ตัวอย่างที่ผู้สร้างเล่าไว้เห็นภาพดี เขาเจอโค้ดตรวจสิทธิ์ (permission check) ที่เขียนคล้ายกันอยู่คนละจุดของโปรเจกต์ คล้ายกันแต่ไม่เป๊ะ เพราะเวอร์ชันหนึ่งเช็กเข้มกว่าอีกเวอร์ชัน พอเอาไปวิเคราะห์กับ coding agent ต่อ ถึงได้รู้ว่าโค้ดทั้งสองจุดยังใช้งานอยู่จริงทั้งคู่ แปลว่ามีจุดหนึ่งที่การตรวจสิทธิ์หย่อนกว่า ถ้ารวมให้เหลือจุดตรวจเดียวก็จะอุดช่องโหว่แบบนี้ได้ง่ายกว่ามาก เห็นได้ว่าการเจอโค้ดคล้ายกันที่อยู่ไกลกัน บางทีก็ไม่ใช่แค่เรื่องความสวยงามของโค้ด แต่กลายเป็นเรื่องความปลอดภัยได้เลย
เครื่องมือที่เราน่าจะได้ใช้บ่อยขึ้น
ยิ่งเราปล่อยให้ AI ช่วยเขียนโค้ดได้เร็วขึ้นเท่าไร โค้ดที่หน้าตาคล้ายๆ กันก็ยิ่งเพิ่มจำนวนและกระจายไปทั่วโปรเจกต์เร็วขึ้นเท่านั้น เครื่องมือที่อ่านความหมายของโค้ดออกอย่าง slopo จึงไม่ใช่แค่ลูกเล่นทางเทคนิค แต่เป็นอีกตัวช่วยที่คนดูแลโค้ดเบสน่าจะได้หยิบมาใช้บ่อยขึ้นเรื่อยๆ ส่วนคำตัดสินสุดท้ายว่าอะไรควรรวม อะไรควรปล่อย ยังอยู่ที่คนกับ AI ที่เข้าใจโปรเจกต์นั้นจริงๆ อยู่ดี
ที่มา:
- โปรเจกต์ slopo บน GitHub (github.com/rafal-qa/slopo)
- เธรดพูดคุยของผู้สร้างกับชุมชนบน Hacker News



