Claude Code Skills: สอน Claude ให้จำวิธีทำงานของทีมไว้ครั้งเดียว ใช้ได้ตลอด ไม่เปลือง context
ถ้ายังพิมพ์อธิบายวิธี deploy รูปแบบ commit และสไตล์ของทีมให้ Claude Code ซ้ำทุก session อยู่ แปลว่ายังใช้มันแค่เศษเสี้ยวของพลังจริง Skills คือกลไกที่สอน Claude ให้จำวิธีทำงานของทีมเป็นความสามารถถาวร โหลดเองอัตโนมัติ และเกือบไม่กิน context จนกว่าจะถูกใช้จริง บทความนี้มี SKILL.md ที่ก๊อปไปใช้ได้ทันที พร้อมตารางตัดสินใจ Skill vs Subagent vs MCP vs CLAUDE.md

นักพัฒนาส่วนใหญ่ใช้ Claude Code เป็นแค่ช่องแชท เปิดขึ้นมาแล้วพิมพ์อธิบายซ้ำทุกครั้งว่าทีมนี้ deploy ยังไง commit message ต้องขึ้นต้นแบบไหน โครงสร้างโปรเจกต์เป็นอย่างไร พอปิดหน้าต่างไปแล้วเปิดใหม่ก็เริ่มอธิบายใหม่ตั้งแต่ต้น วนแบบนี้ทุก session ซึ่งวิธีนี้ใช้ได้ก็จริง แต่เป็นการใช้เครื่องมือแค่เศษเสี้ยวของพลังจริง เพราะ Claude Code มีกลไกชื่อ Skills ที่ออกแบบมาเพื่อแก้ปัญหานี้โดยตรง
Skills คือการเก็บวิธีทำงาน ขั้นตอน หรือความรู้เฉพาะทีมไว้ในไฟล์ SKILL.md หนึ่งไฟล์ในโฟลเดอร์ แล้ว Claude จะหยิบมาใช้เองอัตโนมัติเมื่อเกี่ยวข้อง หรือเรียกตรงด้วย /skill-name ก็ได้ จุดที่ทำให้เรื่องนี้สำคัญมากในปี 2026 มีสามข้อ ข้อแรกคือ custom commands ถูกรวมเข้าเป็น Skills แล้ว ใครเคยทำ .claude/commands/ ต้องรู้ ข้อสองคือมันกลายเป็น open standard ที่ Codex, Gemini CLI, Cursor และ Copilot ใช้ร่วมกัน เขียนครั้งเดียวข้ามเครื่องมือได้ และข้อสามซึ่งสำคัญที่สุดคือกลไก progressive disclosure ที่ทำให้มี Skills เป็นร้อยได้โดยแทบไม่กิน context จนกว่าจะถูกใช้ ตามข้อมูลของ Claude Code Documentation เนื้อ skill จะโหลดเฉพาะตอนที่ถูกใช้ ทำให้เอกสารอ้างอิงยาว ๆ แทบไม่มีต้นทุนจนกว่าจะจำเป็น
1. Skill คืออะไร และทำไมมันเหนือกว่าการแปะ prompt ซ้ำ
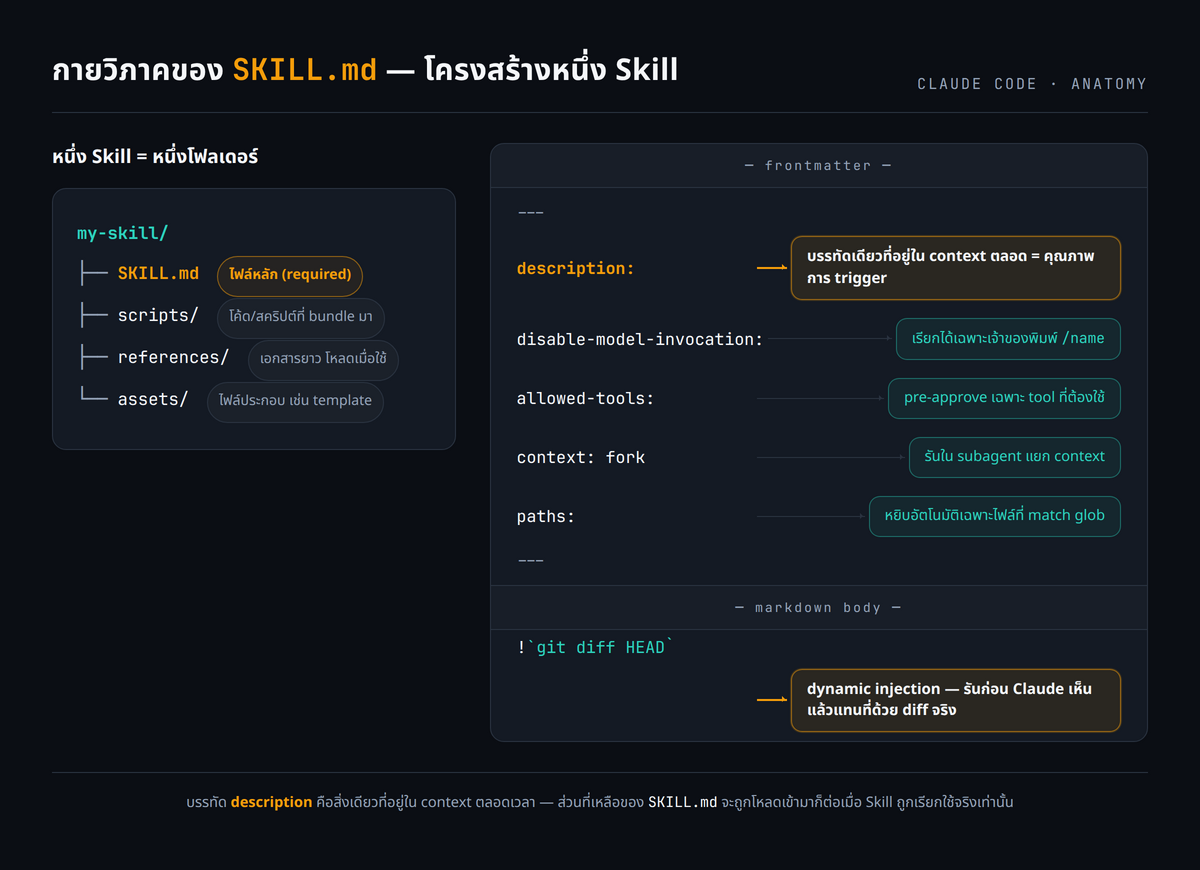
Skill หนึ่งตัวคือโฟลเดอร์หนึ่งโฟลเดอร์ที่มีไฟล์ SKILL.md เป็นไฟล์หลัก ไฟล์นี้แบ่งเป็นสองส่วน ส่วนบนเป็น YAML frontmatter คั่นด้วย --- ซึ่งบอก Claude ว่าควรใช้ skill นี้ตอนไหน และส่วนล่างเป็นเนื้อ markdown ซึ่งเป็นคำสั่งที่ Claude จะทำตาม ชื่อโฟลเดอร์จะกลายเป็นชื่อคำสั่งโดยอัตโนมัติ การเรียกใช้ทำได้สองทาง ทางแรกคือ Claude หยิบมาใช้เองเมื่อคำขอตรงกับ description ทางที่สองคือพิมพ์ /skill-name เรียกตรง
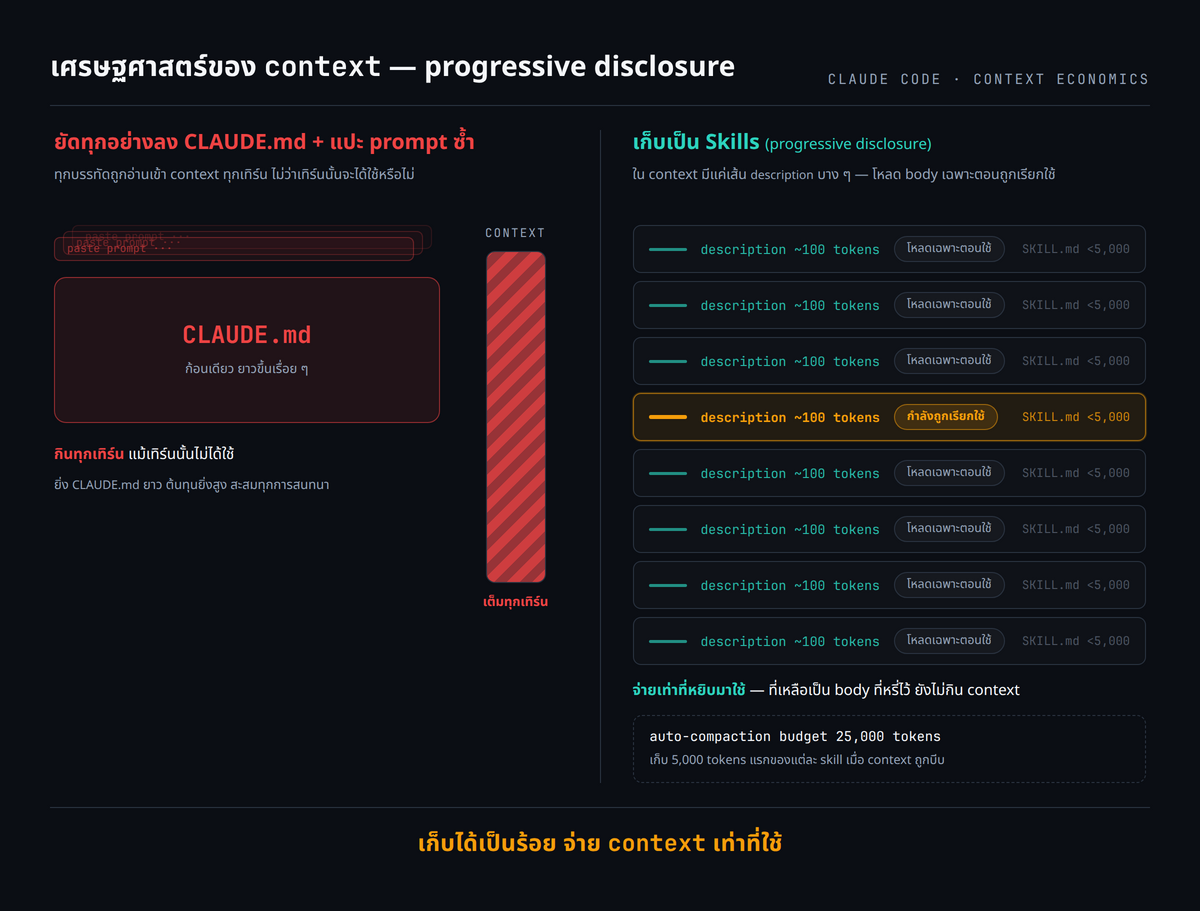
ปัญหาที่ Skills แก้คือคำถามว่าจะให้ Claude รู้วิธีทำงานของทีมได้อย่างไร ปกติมีสองทางที่นักพัฒนาทำกัน ทางแรกคือแปะ prompt ยาวอธิบายซ้ำทุกครั้ง ซึ่งเสียเวลาและมักลืมรายละเอียดบางอย่าง ทางที่สองคือยัดทุกอย่างลง CLAUDE.md ซึ่งแก้ปัญหาการลืมได้ แต่สร้างปัญหาใหม่คือเนื้อหานั้นอยู่ใน context ตลอดเวลา จึงกินโทเคนทุกเทิร์นแม้เทิร์นนั้นไม่ได้เกี่ยวกับการ deploy เลย ยิ่ง CLAUDE.md ยาว ต้นทุนยิ่งสูงและสะสมทุกการสนทนา
Skills แก้ตรงจุดนี้ด้วย progressive disclosure ซึ่งจะอธิบายเชิงตัวเลขในหัวข้อถัดไป หลักการตามที่ Claude Code Documentation ระบุไว้ตรง ๆ คือควรสร้าง skill เมื่อพบว่าตัวเองแปะคำสั่ง checklist หรือขั้นตอนหลายสเต็ปเดิมลงแชทซ้ำ ๆ หรือเมื่อส่วนหนึ่งของ CLAUDE.md โตจากการเป็น "ข้อเท็จจริง" กลายเป็น "ขั้นตอน" เพราะต่างจากเนื้อหาใน CLAUDE.md เนื้อ skill จะโหลดก็ต่อเมื่อถูกใช้ ทำให้เอกสารอ้างอิงยาว ๆ แทบไม่มีต้นทุนจนกว่าจะจำเป็น
ทาง Anthropic อธิบายความต่างไว้ในประโยคที่จำง่ายว่า Projects บอกว่า "นี่คือสิ่งที่ต้องรู้" ส่วน Skills บอกว่า "นี่คือวิธีลงมือทำ" ตามที่ระบุใน Anthropic ความต่างนี้สำคัญเพราะมันบอกว่า อะไรที่เป็นข้อเท็จจริงพื้นฐานควรอยู่ใน CLAUDE.md แต่อะไรที่เป็นวิธีลงมือทำควรเป็น skill เพื่อไม่ให้กิน context ตอนที่ไม่ได้ทำงานนั้น
Tip: ชุมชนผู้ใช้แบ่ง skill ที่ดีเป็นสองประเภทตามที่ Firecrawl สรุปไว้ ประเภทแรกคือ Capability Uplift คือความสามารถใหม่ที่ Claude ไม่มีในตัว เช่น scrape เว็บ สร้างไฟล์ .docx หรือทดสอบ browser และประเภทที่สองคือ Encoded Preference คือวิธีทำงานเฉพาะของทีมในงานที่ Claude ทำได้อยู่แล้ว ซึ่งก็คือทางเลือกเฉพาะที่ทำให้งานของทีมเป็นสไตล์ของทีมเอง
2. Progressive disclosure: เหตุผลเชิงเศรษฐศาสตร์ที่ทำให้ Skill เกือบฟรี
หัวข้อนี้คือหัวใจของเรื่องทั้งหมด เพราะมันคือเหตุผลว่าทำไม Skill ถึงชนะการแปะ prompt ซ้ำและการยัดทุกอย่างลง CLAUDE.md
กลไก progressive disclosure ทำงานเป็นสามขั้นตามที่ agentskills.io อธิบายไว้ ขั้นแรกคือ Discovery ตอนเปิด session ระบบจะโหลดเฉพาะ name และ description ของทุก skill เข้ามา แค่พอให้ Claude รู้ว่ามีของชิ้นนี้อยู่และควรใช้ตอนไหน ขั้นที่สองคือ Activation เมื่องานตรงกับ description ของ skill ตัวใด Claude จึงอ่านเนื้อ SKILL.md เต็มเข้า context และขั้นที่สามคือ Execution คือ Claude ทำตามคำสั่ง โดยรันสคริปต์หรือโหลดไฟล์อ้างอิงเฉพาะที่จำเป็นจริง ๆ
ตัวเลขคือสิ่งที่ทำให้กลไกนี้น่าสนใจ ตามข้อมูลของ Anthropic metadata ที่โหลดก่อนใช้พื้นที่ราว 100 tokens ต่อ skill เท่านั้น ส่วนคำสั่งเต็มจะโหลดเมื่อจำเป็น ซึ่งอยู่ในระดับต่ำกว่า 5,000 tokens และไฟล์ประกอบหรือสคริปต์จะโหลดเฉพาะตอนที่ต้องใช้จริง สถาปัตยกรรมนี้ทำให้มี skill จำนวนมากพร้อมใช้โดยไม่ทำให้ context window ล้น เพราะ Claude หยิบเฉพาะที่ต้องใช้ ตอนที่ต้องใช้ ตัวเลขราว 100 tokens และต่ำกว่า 5,000 tokens นี้เป็นค่าโดยประมาณที่ Anthropic ใช้ในบล็อก ไม่ใช่ค่าตายตัว แต่ลำดับขนาดสะท้อนภาพได้ชัด สมมติว่ามี skill 50 ตัว ต้นทุนที่ลอยอยู่ตลอดคือราว 5,000 tokens รวม ในขณะที่ถ้ายัดเนื้อหาเดียวกันทั้ง 50 เรื่องลง CLAUDE.md ต้นทุนจะเป็นผลรวมของเนื้อเต็มทั้งหมดที่กินทุกเทิร์น แม้เทิร์นนั้นใช้แค่เรื่องเดียว
มีรายละเอียดสำคัญอีกข้อที่ต้องเข้าใจคือ skill content lifecycle ตามที่ Claude Code Documentation ระบุไว้ เมื่อ skill ถูก invoke เนื้อ SKILL.md ที่ render แล้วจะเข้ามาในบทสนทนาเป็นข้อความเดียวและอยู่ตรงนั้นไปตลอดทั้ง session โดย Claude Code จะไม่อ่านไฟล์ skill ใหม่ในเทิร์นถัด ๆ ไป ผลที่ตามมาในทางปฏิบัติคือเนื้อ skill ต้องเขียนเป็น "คำสั่งยืน" ที่ใช้ได้ตลอด ไม่ใช่ขั้นตอนแบบทำครั้งเดียวจบ และเพราะเนื้อ skill อยู่ใน context ทั้ง session ทุกบรรทัดจึงเป็นต้นทุนโทเคนที่เกิดซ้ำ การเขียนจึงควรกระชับ บอกว่าให้ทำอะไร ไม่ต้องเล่ายาวว่าทำไมหรืออย่างไร
ตอน auto-compaction ระบบมีงบจัดการเรื่องนี้ชัดเจน เมื่อบทสนทนาถูกย่อเพื่อคืนพื้นที่ context Claude Code จะดึง invocation ล่าสุดของแต่ละ skill กลับมาต่อท้ายบทสรุป โดยเก็บ 5,000 tokens แรกของแต่ละ skill และ skill ที่ถูกดึงกลับทั้งหมดใช้งบรวมกัน 25,000 tokens ระบบเติมงบนี้โดยเริ่มจาก skill ที่เพิ่ง invoke ล่าสุดก่อน ดังนั้น skill เก่าอาจหลุดออกทั้งหมดหลัง compaction ถ้า invoke skill หลายตัวใน session เดียว ถ้า skill ตัวสำคัญหลุดไป วิธีแก้คือ re-invoke มันอีกครั้งหลัง compaction
3. ลงมือทำจริง: SKILL.md สองตัวที่ก๊อปไปใช้ได้วันนี้
หัวข้อนี้คือส่วนที่เอาไปลงมือทำได้ทันที จะแสดง skill สองตัวที่ครอบสอง mental model หลัก ตัวแรกคือ skill ที่ Claude หยิบเองอัตโนมัติพร้อมการฉีดข้อมูลสดเข้าไป และตัวที่สองคือ skill งานที่มี side-effect ซึ่งต้องคุมจังหวะการเรียกเอง ทั้งสองตัวมาจากตัวอย่างทางการใน Claude Code Documentation โดยตรง
ตัวอย่าง A: summarize-changes (auto-invoke + dynamic context injection)
skill ตัวนี้สรุป diff ที่ยังไม่ commit แล้วชี้จุดเสี่ยง จุดที่น่าสนใจที่สุดคือบรรทัด !`git diff HEAD` ซึ่งใช้กลไก dynamic context injection คือ Claude Code จะรันคำสั่งนั้นก่อน แล้วแทนที่บรรทัดด้วยผลลัพธ์จริง ก่อนที่ Claude จะเห็นเนื้อ skill ผลคือคำสั่งมาถึงพร้อม diff จริงที่ inline อยู่แล้ว ไม่ใช่ให้ Claude เดาว่ามีอะไรเปลี่ยน
---
description: Summarizes uncommitted changes and flags anything risky. Use when the user asks what changed, wants a commit message, or asks to review their diff.
---
## Current changes
!`git diff HEAD`
## Instructions
Summarize the changes above in two or three bullet points, then list any
risks you notice such as missing error handling, hardcoded values, or
tests that need updating. If the diff is empty, say there are no
uncommitted changes.วิธีติดตั้งคือสร้างโฟลเดอร์ด้วยคำสั่ง mkdir -p ~/.claude/skills/summarize-changes แล้วเซฟไฟล์ข้างบนเป็น ~/.claude/skills/summarize-changes/SKILL.md ตำแหน่งนี้คือ personal skills folder ซึ่งใช้ได้กับทุกโปรเจกต์ การทดสอบทำได้สามขั้นง่าย ๆ ขั้นแรกแก้ไฟล์อะไรก็ได้ในโปรเจกต์ที่เป็น git repo โดยยังไม่ commit ขั้นที่สองทดสอบให้ Claude หยิบเองโดยถามว่า "What did I change?" ซึ่งตรงกับ description ขั้นที่สามทดสอบเรียกตรงด้วย /summarize-changes ทั้งสองทางจะให้ผลสรุป diff พร้อมจุดเสี่ยง
Note: บรรทัด
!`<command>`คือ preprocessing ไม่ใช่สิ่งที่ Claude สั่งรันเอง การแทนที่จะรันครั้งเดียวบนไฟล์ต้นฉบับ และผลลัพธ์ของคำสั่งจะถูกใส่เป็น plain text ที่ไม่ถูก scan หา placeholder ซ้ำ ถ้าต้องการรันหลายคำสั่งใช้ fenced block ที่เปิดด้วย```!ได้
ตัวอย่าง B: deploy (task skill + disable-model-invocation + allowed-tools)
skill ตัวนี้เป็นงานที่มี side-effect แบบที่ไม่อยากให้ Claude เผลอตัดสินใจรันเองเพราะโค้ดดูพร้อม จึงตั้ง disable-model-invocation: true เพื่อให้เรียกได้เฉพาะตอนพิมพ์ /deploy เอง และตั้ง allowed-tools เพื่อ pre-approve เฉพาะคำสั่ง git ที่จำเป็น ทำให้ skill ทำงานต่อเนื่องโดยไม่ต้องกดอนุญาตทุกครั้ง
---
name: deploy
description: Deploy the application to production
disable-model-invocation: true
allowed-tools: Bash(git add *) Bash(git commit *) Bash(git status *)
---
Deploy $ARGUMENTS to production:
1. Run the test suite
2. Build the application
3. Push to the deployment target
4. Verify the deployment succeededติดตั้งด้วย mkdir -p ~/.claude/skills/deploy แล้วเซฟเป็น ~/.claude/skills/deploy/SKILL.md เวลาเรียกเช่น /deploy staging ตัวแปร $ARGUMENTS จะกลายเป็น staging มีรายละเอียดที่ระบุไว้ใน Claude Code Documentation ว่า ถ้า skill ถูกเรียกพร้อม argument แต่ในเนื้อไม่มี $ARGUMENTS ระบบจะต่อท้ายให้เองเป็น ARGUMENTS: <ค่าที่พิมพ์> เพื่อให้ Claude ยังเห็นค่านั้น
Warning:
allowed-toolsไม่ได้จำกัด tool ทุก tool ยังเรียกได้ตามปกติ และ permission setting ปกติยังคุม tool อื่นที่ไม่ได้ระบุ ประเด็นด้านความปลอดภัยที่ต้องระวังคือ project skill ที่อยู่ใน.claude/skills/ของ repo สามารถ grant tool access ให้ตัวเองได้กว้าง จึงควรรีวิว project skill ก่อนกด trust repo ที่ไม่รู้จัก ตามคำเตือนใน Claude Code Documentation
อีกตัวที่เหมาะกับการสะท้อนมุม "วิธีทำงานของทีม" คือ skill commit ที่บังคับรูปแบบ Conventional Commits เขียนคล้ายตัว B แต่ตั้ง description ให้ตรง เช่น "Stage and commit using Conventional Commits format. Use when the user asks to commit, save changes, or write a commit message." พร้อม allowed-tools ที่มี Bash(git diff *) เพิ่ม เพื่อให้ Claude ดู diff ก่อนจัดกลุ่มและเขียน subject กระชับ skill แบบนี้คือ Encoded Preference ที่เก็บวิธีทำงานของทีมไว้ในที่เดียว ใช้ซ้ำได้สม่ำเสมอ
4. ข่าวที่ทุกคนที่มี .claude/commands/ ต้องรู้
ปี 2026 Claude Code รวม custom commands เข้าเป็น Skills แล้ว ตามที่ระบุใน Claude Code Documentation ไฟล์ที่ .claude/commands/deploy.md กับ skill ที่ .claude/skills/deploy/SKILL.md สร้างคำสั่ง /deploy เหมือนกันและทำงานเหมือนกัน ไฟล์เดิมใน .claude/commands/ ยังใช้ได้ต่อและรองรับ frontmatter ชุดเดียวกัน จึงไม่ต้องรีบย้าย แต่ของใหม่แนะนำให้เป็น skill เพราะได้ฟีเจอร์เพิ่ม
สิ่งที่ skill ให้เพิ่มมีสามอย่าง อย่างแรกคือโฟลเดอร์สำหรับใส่ไฟล์ประกอบ เช่น template สคริปต์ หรือไฟล์อ้างอิง อย่างที่สองคือ frontmatter สำหรับควบคุมว่าใครเรียก skill ได้บ้าง และอย่างที่สามคือความสามารถให้ Claude โหลด skill เองอัตโนมัติเมื่อเกี่ยวข้อง สามอย่างนี้คือสิ่งที่ไฟล์ใน .claude/commands/ แบบเดิมทำไม่ได้
มีกฎสำคัญสองข้อที่ต้องจำ ข้อแรกคือถ้า skill กับ command ชื่อเดียวกัน skill ชนะ ข้อที่สองคือ precedence ข้ามระดับ เมื่อ skill ชื่อเดียวกันอยู่หลายระดับ enterprise จะ override personal และ personal จะ override project ส่วน plugin skill ใช้ namespace plugin-name:skill-name จึงไม่ชนกับใคร ตำแหน่งที่เก็บ skill มีสี่ระดับตามตารางนี้
| ระดับ | path | ใช้กับ |
|---|---|---|
| Enterprise | ตั้งผ่าน managed settings | ผู้ใช้ทุกคนในองค์กร |
| Personal | ~/.claude/skills/<skill-name>/SKILL.md | ทุกโปรเจกต์ของผู้ใช้ |
| Project | .claude/skills/<skill-name>/SKILL.md | เฉพาะโปรเจกต์นี้ |
| Plugin | <plugin>/skills/<skill-name>/SKILL.md | ที่ที่ plugin เปิดใช้งาน |
มีรายละเอียดที่เป็นประโยชน์อีกข้อคือ Claude Code เฝ้าดูการเปลี่ยนแปลงในโฟลเดอร์ skill การเพิ่ม แก้ หรือลบ skill ภายใต้โฟลเดอร์ที่ session กำลังเฝ้าดูอยู่จะมีผลทันทีโดยไม่ต้อง restart แต่ถ้าสร้างโฟลเดอร์ skill ระดับบนสุดที่ยังไม่มีตอนเปิด session ต้อง restart Claude Code เพื่อให้มันเริ่มเฝ้าดูโฟลเดอร์ใหม่ ส่วนหมายเหตุเรื่องเลขเวอร์ชันที่ merge นั้น เอกสารทางการไม่ระบุเลขเวอร์ชันเจาะจง บทความนี้จึงอ้างเพียงว่าเกิดในปี 2026
5. Skill vs Subagent vs MCP vs CLAUDE.md เลือกอันไหนเมื่อไหร่
นี่คือคำถามที่นักพัฒนาค้นหามากที่สุด และยังสับสนกันทั้งวงการ สี่อย่างนี้ไม่ใช่ของแทนกัน แต่เป็นชั้นที่ทำงานคนละหน้าที่ วิธีจำที่กระชับที่สุดสรุปไว้ใน K21 Academy คือ Skill ลงมือทำสิ่งที่รู้แล้ว Subagent คิดหาว่าต้องทำอะไร MCP ดึงสิ่งที่ยังไม่รู้เข้ามา และ CLAUDE.md คือความจริงพื้นฐานที่ต้องรู้ตลอด
| มิติ | Skill | Subagent | MCP | CLAUDE.md |
|---|---|---|---|---|
| ให้อะไร | วิธีทำและขั้นตอน | มอบหมายงานให้ผู้เชี่ยวชาญที่มี context แยก | ต่อกับระบบภายนอก เช่น DB API SaaS | ข้อเท็จจริงพื้นฐานของโปรเจกต์ |
| บทบาท | ชั้นลงมือทำ | ชั้นคิดและวางแผน | ชั้นเชื่อมต่อและดึงข้อมูล | ชั้นบริบทที่ต้องรู้ตลอด |
| โหลดเข้า context เมื่อ | เฉพาะตอนเกี่ยว desc ราว 100 tokens อยู่ตลอด body โหลดตอน invoke | ตอนถูก invoke แบบ context แยก | พร้อมใช้ตลอด เป็น tool definitions | อยู่ใน context ตลอดทุกเทิร์น |
| ใส่โค้ดหรือสคริปต์ได้ | ได้ มี scripts/ | ได้ | ได้ เป็น tool | ไม่ได้ เป็นเอกสาร |
| ใช้เมื่อ | รู้แล้วว่าต้องทำอะไร อยากให้ทำซ้ำได้สม่ำเสมอ เช่น convention deploy commit สไตล์ทีม | ต้องให้คิดเป็นขั้น แยก context หนัก หรือทำขนาน เช่น debug research วิเคราะห์ยาว | ต้องเข้าถึงข้อมูลหรือระบบที่ Claude เอื้อมไม่ถึงเอง เช่น DB GitHub Slack | ทุก session ต้องรู้สิ่งนี้เสมอ เช่น สถาปัตยกรรม ห้ามทำ X การตั้งชื่อ |
| ต้นทุน context | ต่ำมาก จาก progressive disclosure | แยก context ของตัวเอง | คงที่ tool defs อยู่ตลอด | สูง อยู่ตลอดแม้ไม่ใช้ |
| ผูกกับ Anthropic | ไม่ เป็น open standard | Claude-specific | open protocol ข้ามโมเดล | Claude-specific |
ตารางเปรียบเทียบของ Anthropic เองสรุปแก่นไว้ว่า Subagents เหมาะกับงานเฉพาะทางที่เป็นเอเจนต์เบ็ดเสร็จในตัว ส่วน MCP ต่อ Claude เข้ากับข้อมูล และ Skills สอน Claude ว่าจะทำอะไรกับข้อมูลนั้น ตามที่ระบุใน Anthropic ทั้งสองอย่างใช้คู่กันได้ คือ MCP สำหรับการเชื่อมต่อ ส่วน Skills สำหรับความรู้เชิงขั้นตอน
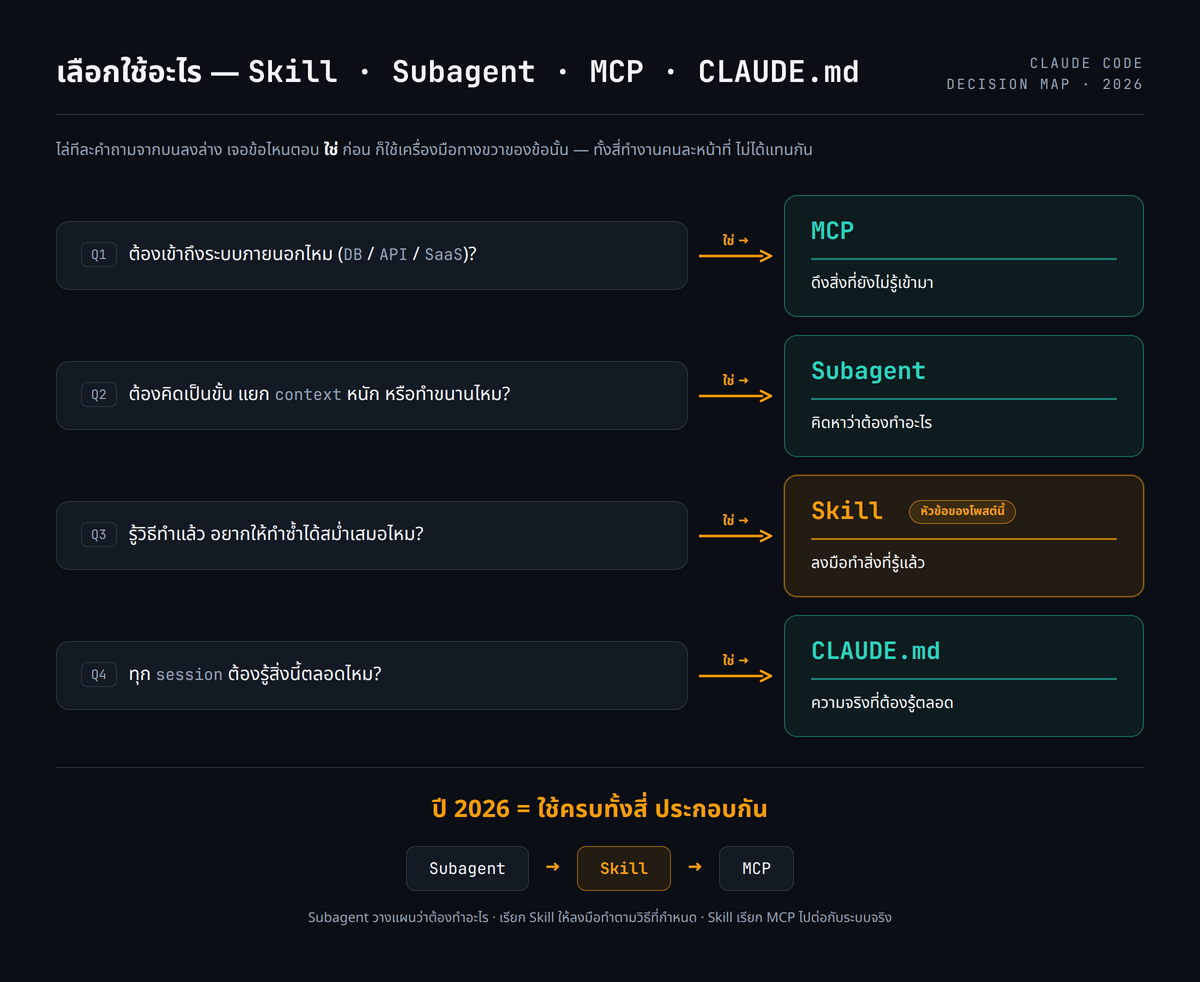
คำตอบ default ของปี 2026 ไม่ใช่เลือกอันใดอันหนึ่ง แต่คือใช้ครบทั้งสี่ประกอบกัน รูปแบบที่ K21 Academy อธิบายคือ subagent เป็นชั้นเหตุผลที่ orchestrate งาน เรียก skill เป็นชั้นลงมือทำเพื่อทำงานเฉพาะ และ skill เรียก MCP เป็นชั้นเชื่อมต่อเพื่อดึงข้อมูลสด ตัวอย่างเช่น research agent ที่เป็น subagent มอบหมายงานดึง GitHub issues แล้ว skill เรียก MCP ให้ GitHub คืนข้อมูลสดกลับมา ความสัมพันธ์ระหว่าง skill กับ subagent มีสองทิศ ทิศแรก skill ที่ตั้ง context: fork จะรันใน subagent แยก context โดยเนื้อ skill กลายเป็น prompt ของ subagent นั้น ทิศที่สอง subagent ที่มี field skills จะ preload เนื้อ skill เต็มตั้งแต่ startup
ข้อควรระวังที่พบบ่อยมีสามข้อ ข้อแรกคือเอา subagent ไปทำงานง่าย ๆ ซึ่งเพิ่มความซับซ้อนโดยไม่จำเป็น ข้อที่สองคือลืม MCP ตอนที่ระบบต้องการข้อมูลภายนอกจริง ๆ ข้อที่สามคือยัด logic ลง skill มากจนเสียจุดประสงค์ของมัน หลักการง่าย ๆ คือ ถ้าส่วนหนึ่งของ CLAUDE.md กลายเป็น "ขั้นตอน" มากกว่า "ข้อเท็จจริง" ให้ย้ายส่วนนั้นเป็น skill จะได้ไม่กิน context ตอนไม่ใช้
6. เขียนครั้งเดียว รันข้ามเครื่องมือ และ frontmatter ที่สำคัญที่สุด
ก่อนปิดท้ายมี frontmatter อีกไม่กี่ field ที่ควรรู้จัก เพราะมันคือปุ่มควบคุมพฤติกรรมของ skill ทุก field เป็น optional มีแค่ description ที่แนะนำให้มี field ที่สำคัญที่สุดคือ description เพราะมันคือบรรทัดเดียวที่อยู่ใน context ตลอด คุณภาพของ description จึงเท่ากับคุณภาพการ trigger ควรเขียนทั้งว่าทำอะไรและใช้ตอนไหน ใส่ keyword ที่ผู้ใช้พูดจริง และเอา use case หลักไว้หน้าสุด เพราะข้อความ description รวมกับ when_to_use ถูกตัดที่ 1,536 ตัวอักษรใน skill listing ตามที่ระบุใน Claude Code Documentation field อื่นที่ควรรู้ ได้แก่ disable-model-invocation: true ที่ห้าม Claude หยิบไปใช้เอง เรียกได้เฉพาะตอนพิมพ์ /name เหมาะกับงานมี side-effect ส่วน user-invocable: false ทำตรงข้ามคือซ่อนจากเมนู / ให้เฉพาะ Claude หยิบเอง เหมาะกับความรู้พื้นหลังที่ไม่ใช่ action ส่วน paths เป็น glob ที่จำกัดให้ skill ถูกหยิบอัตโนมัติเฉพาะตอนทำงานกับไฟล์ที่ตรง pattern และ context: fork ที่รัน skill ใน subagent แยก context โดยเหมาะกับ skill ที่มีคำสั่งชัดเท่านั้น ถ้าเป็นแค่ guideline ไม่มี task subagent จะได้ guideline แต่ไม่มีงานทำ จึงคืนค่าว่าง
ตัวแปรที่ควรใช้ให้เป็นนิสัยคือ ${CLAUDE_SKILL_DIR} สำหรับอ้าง path สคริปต์ที่ bundle มากับ skill แทนการ hardcode path เพราะมันจะ resolve ถูกต้องไม่ว่า skill จะติดตั้งที่ระดับ personal, project หรือ plugin นอกจากนี้ยังมี $ARGUMENTS สำหรับ argument ทั้งหมด $0 หรือ $1 สำหรับ argument ตามตำแหน่ง และ ${CLAUDE_SESSION_ID} สำหรับ log ที่อิง session
จุดที่ขยายมูลค่าของการลงทุนเขียน skill คือ format นี้ Anthropic สร้างขึ้นแล้วปล่อยเป็น open standard ชื่อ Agent Skills ตามที่ระบุใน agentskills.io โครงสร้างพื้นฐานของ spec กลางคือโฟลเดอร์ที่มี SKILL.md ซึ่ง frontmatter required มีแค่ name กับ description บวกโฟลเดอร์ scripts/ references/ assets/ ที่เป็น optional และกลไก progressive disclosure เดียวกัน ผลคือ SKILL.md ที่นักพัฒนาไทยเขียนให้ Claude Code ไม่ได้ผูกกับ Anthropic โฟลเดอร์เดียวกันรันได้บน Codex CLI, Gemini CLI, Cursor, Copilot, VS Code, Junie ของ JetBrains, Goose ของ Block และเครื่องมืออื่นอีกหลายตัว ส่วน Claude Code เพียงต่อยอด standard นี้ด้วยฟีเจอร์เสริมอย่าง invocation control, subagent execution และ dynamic context injection แต่ตัว format พื้นฐานพกพาข้ามเครื่องมือได้
ในแง่ความนิยม ตามบล็อก Firecrawl มี skill ของชุมชนที่ถูกติดตั้งระดับแสนครั้งต่อสัปดาห์หลายตัว เช่น Frontend Design ที่ช่วยให้ Claude ไม่ออกแบบ UI ซ้ำซากแบบ generic, Vercel Web Design Guidelines ที่เป็นกฎ accessibility และ UX กว่าร้อยข้อ และ Remotion ที่ออกมาเดือนกุมภาพันธ์ 2026 แล้วชุมชนพูดถึงกันมาก ตัวเลขติดตั้งเหล่านี้มาจากบล็อก Firecrawl ใช้เป็นภาพประกอบความนิยม ไม่ใช่สถิติทางการ แต่ก็สะท้อนว่า ecosystem ของ skill โตจริง
แนวทางสุดท้ายที่ควรยึดเป็นกฎทองมีไม่กี่ข้อ description ต้องใส่ keyword ที่ผู้ใช้พูดจริงและเอา use case หลักไว้หน้าสุด SKILL.md ควรไม่เกิน 500 บรรทัด ถ้าเนื้อหายาว เช่น API reference หรือตัวอย่างจำนวนมาก ให้แยกไฟล์แล้วอ้างจาก SKILL.md เพื่อให้โหลดเฉพาะตอนต้องใช้ task skill ที่มี side-effect ควรตั้ง disable-model-invocation: true เสมอ และถ้า skill ไม่ trigger ให้ตรวจว่า description มี keyword ที่ผู้ใช้พูดจริงไหม ลองถาม "What skills are available?" หรือพิมพ์ /skill-name ตรง ถ้า description ถูกตัดสั้นเพราะ skill เยอะเกิน budget ที่สเกล 1% ของ context window ให้รัน /doctor ดูว่า budget ล้นไหม แล้วปรับด้วย skillListingBudgetFraction หรือตั้ง skill ที่ไม่สำคัญเป็น "name-only" ใน skillOverrides
สิ่งที่ทำได้ทันทีหลังอ่านจบคือก๊อป SKILL.md ตัวอย่าง A ในหัวข้อ 3 เซฟเป็น ~/.claude/skills/summarize-changes/SKILL.md แก้ไฟล์ในโปรเจกต์โดยยังไม่ commit แล้วถาม Claude ว่า "What did I change?" เพียงเท่านี้ก็ได้ skill ตัวแรกที่ Claude หยิบมาใช้เองอัตโนมัติ จากนั้นค่อยขยับไปเก็บวิธี deploy และวิธี commit ของทีมเป็น skill ทีละตัว สุดท้ายจะได้ Claude Code ที่จำวิธีทำงานของทีมได้ถาวร โดยแทบไม่กิน context จนกว่าจะถูกใช้จริง
ที่มา: Claude Code Documentation, Anthropic, agentskills.io, Firecrawl, K21 Academy



