Pre-warming prompt cache ของ Claude API ใช้ max_tokens 0 ตัด latency รอบแรกของ user
Anthropic เปิด max_tokens 0 เป็น API surface ทางการสำหรับ pre-warm prompt cache ก่อน user request แรกจะเข้ามา ตัด cache-miss latency ที่เกิดเวลา cache 5 นาทีหมดอายุ พร้อม pattern ใช้จริง pricing multiplier และ gotcha ที่ Anthropic เน้นในเอกสาร

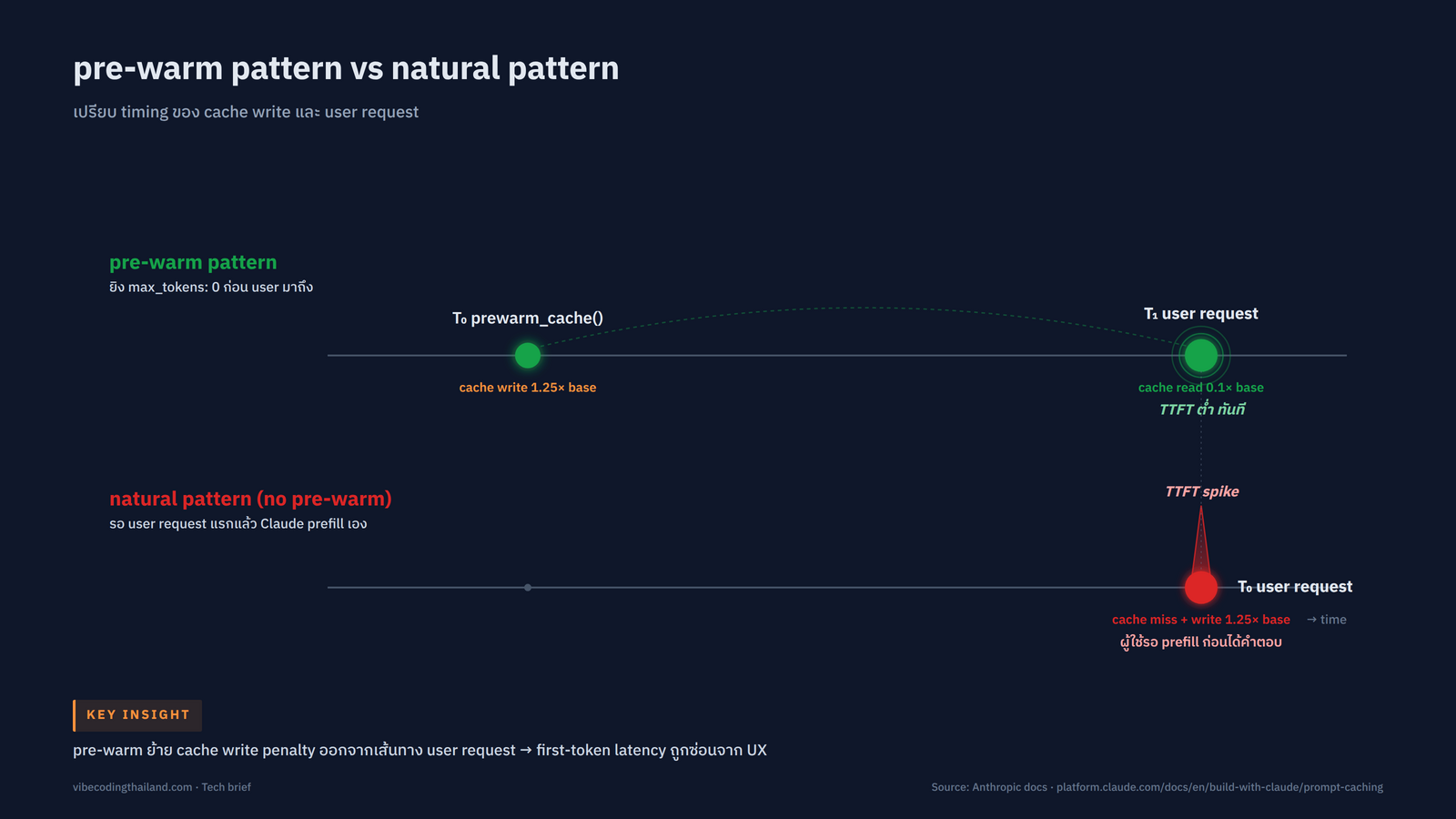
ในเอกสารทางการของ Anthropic หัวข้อ prompt caching มี section เล็กๆ ชื่อ Pre-Warming the Cache ที่ dev ไทยจำนวนมาก skim ผ่าน แต่จริงๆ เป็น pattern ที่แก้ปัญหา latency คลาสสิกของ production app ที่ build บน Claude API ได้ตรงจุด ปัญหาคือหลัง cache หมดอายุ request แรกของ user จะช้าผิดปกติ เพราะ Claude ต้อง prefill system prompt ทั้งก้อนใหม่ ทำให้ time-to-first-token พุ่งเฉพาะรอบแรก ส่วน request ถัดไปที่ยังอยู่ใน window TTL จะเร็วตามคาด
Anthropic prompt-caching docs ระบุว่า ตอนนี้มี API surface ทางการสำหรับยิง request max_tokens: 0 เพื่อโหลด system prompt หรือ tool definitions เข้า cache ก่อน user มาถึง โดย API จะรัน prefill phase เต็มที่ เขียน cache ที่ breakpoint แล้ว return ทันที ไม่ generate output เลย Anthropic อธิบายว่า pattern นี้มาแทน workaround เดิมที่บางทีมเคยใช้ max_tokens: 1 แล้วทิ้ง 1 token ที่ออกมา และเหมาะกับ application ที่ latency-sensitive อย่าง voice agent, customer chat และ autocomplete ที่ user คาดหวัง response เร็วตั้งแต่รอบแรก
1. Prompt cache ทำงานยังไง (recap ก่อนเข้า pre-warming)
ก่อนเข้า pre-warm ต้องเข้าใจ prompt cache พื้นฐานก่อน ตามที่ Anthropic อธิบายในหน้า prompt caching การเปิด cache ทำได้ 2 ทาง คือ automatic caching และ explicit cache breakpoints แบบแรกใส่ cache_control ที่ top-level ของ request 1 ครั้ง แล้วระบบจะวาง breakpoint ที่ block สุดท้ายให้อัตโนมัติ ส่วนแบบหลังวาง cache_control บน content block ที่ต้องการเอง เลือกได้สูงสุด 4 breakpoint ต่อ 1 request
Cache อ้างอิง prefix ของ prompt ตาม hierarchy tools → system → messages ตามลำดับ ถ้าเปลี่ยน level ไหน cache ของ level นั้นและทุก level หลังจากนั้นจะ invalidate ตัวอย่างที่ Anthropic ระบุชัดคือ ถ้าแก้ tool definition (name, description, parameter) จะ invalidate ทั้ง tools cache, system cache และ messages cache พร้อมกัน ขณะที่การเปลี่ยน tool_choice จะ invalidate เฉพาะ messages cache
หลักการ 3 ข้อที่ docs เน้นเป็น core ของระบบคือ cache write เกิด เฉพาะที่ breakpoint เท่านั้น, cache read เดินถอยหลัง หา entry ที่ request ก่อนหน้าเขียนไว้ และ lookback window มีขนาด 20 block ต่อ breakpoint นั่นหมายความว่า cache อ้างอิง entry ที่ "เขียนไว้แล้ว" ในรอบก่อน ไม่ใช่ "content ที่ stable" ตามใจ developer ถ้าวาง breakpoint ผิดที่ ระบบจะเขียน cache entry ใหม่ทุก request และไม่มีวันได้ cache hit
ตามค่า default cache มี TTL 5 นาที และ refresh ฟรีทุกครั้งที่ถูกใช้ Anthropic เปิดให้ใช้ TTL 1 ชั่วโมงเพิ่มได้ โดยคิดราคาเขียน 2 เท่าของ base input ผ่าน syntax {"cache_control": {"type": "ephemeral", "ttl": "1h"}} (Bedrock ไม่รองรับ TTL 1 ชั่วโมง)
2. Pre-warming คืออะไร และทำงานยังไง
ในเอกสารของ Anthropic cache pre-warming คือการโหลด system prompt หรือ tool definitions เข้า cache ก่อน user request จริงเข้ามา เพื่อกำจัด cache-miss latency penalty ในรอบแรก กลไกคือยิง request ที่ตั้ง max_tokens: 0 จากนั้นระบบจะรัน prefill phase เต็มที่ เขียน cache ที่ทุก cache_control breakpoint แล้ว return ทันที โดยไม่ generate output
Response จาก pre-warm request มี shape เฉพาะตามที่ docs โชว์ คือ content เป็น array ว่าง, stop_reason เป็น "max_tokens" และ usage block ครบ รวมถึง field cache_creation_input_tokens ที่ระบุจำนวน token ที่เขียนเข้า cache
import anthropic
client = anthropic.Anthropic()
prewarm = client.messages.create(
model="claude-opus-4-7",
max_tokens=0,
system=[
{
"type": "text",
"text": "You are an expert software engineer with deep knowledge of distributed systems...",
"cache_control": {"type": "ephemeral"},
}
],
messages=[{"role": "user", "content": "warmup"}],
)
print(prewarm.stop_reason) # "max_tokens"
print(prewarm.content) # []
print(prewarm.usage) # cache_creation_input_tokens > 0Anthropic ยกตัวอย่าง response JSON ที่กลับมาจาก pre-warm request ของ system prompt ขนาดประมาณ 5,000 token ไว้ดังนี้
{
"id": "msg_01XFDUDYJgAACzvnptvVoYEL",
"content": [],
"stop_reason": "max_tokens",
"usage": {
"input_tokens": 8,
"cache_creation_input_tokens": 5120,
"cache_read_input_tokens": 0,
"cache_creation": {
"ephemeral_5m_input_tokens": 5120,
"ephemeral_1h_input_tokens": 0
},
"output_tokens": 0
}
}จุดที่ docs เน้นคือ pre-warm ยังเสีย cache write charge ตามปกติ เหมือน request อื่นที่เขียน cache ใหม่ แต่ไม่บิล output token เลย เพราะ output เป็น 0 เมื่อ user request จริงเข้ามาภายใน TTL ระบบจะอ่าน prefix ที่ pre-warm ไว้เป็น cache read ในราคาเพียง 0.1 เท่าของ base input ตามตาราง pricing ของ Anthropic
Placeholder user message เป็นข้อความอะไรก็ได้ที่มี non-whitespace content โดยเอกสารใช้ "warmup" เป็นตัวอย่าง ระบบจะอ่าน content ของ message นี้ระหว่าง prefill แต่จะไม่ตอบ เพราะ max_tokens: 0 หยุดการ generate ไว้ก่อน
3. Pattern ใช้จริง: prewarm function + respond function
หน้า docs ของ Anthropic เสนอ pattern ใช้งานจริงที่แยก prewarm_cache() ออกจาก respond() ชัดเจน โดยมี shared variable คือ SYSTEM_PROMPT ซึ่งวาง cache_control breakpoint ไว้บน block สุดท้ายของ system prompt ไม่ใช่บน user message
import anthropic
client = anthropic.Anthropic()
SYSTEM_PROMPT = [
{
"type": "text",
"text": "You are an expert software engineer with deep knowledge of distributed systems...",
"cache_control": {"type": "ephemeral"},
}
]
def prewarm_cache() -> None:
"""Call this at application startup or on a scheduled interval."""
client.messages.create(
model="claude-opus-4-7",
max_tokens=0,
system=SYSTEM_PROMPT,
messages=[{"role": "user", "content": "warmup"}],
)
def respond(user_message: str) -> anthropic.types.Message:
"""The real user request; benefits from a warm cache."""
return client.messages.create(
model="claude-opus-4-7",
max_tokens=1024,
system=SYSTEM_PROMPT,
messages=[{"role": "user", "content": user_message}],
)
# Warm the cache before any user traffic arrives.
prewarm_cache()
# Later, when the user submits a message, the system-prompt prefix is already cached.
response = respond("How do I implement a binary search tree?")
print(response.content[0].text)ส่วน TypeScript ใช้ SDK @anthropic-ai/sdk กับ shape เดียวกัน ต่างกันแค่ syntax ของภาษา
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic();
const prewarm = await client.messages.create({
model: "claude-opus-4-7",
max_tokens: 0,
system: [
{
type: "text",
text: "You are an expert software engineer with deep knowledge of distributed systems...",
cache_control: { type: "ephemeral" }
}
],
messages: [{ role: "user", content: "warmup" }]
});
console.log(prewarm.stop_reason); // "max_tokens"
console.log(prewarm.content); // []จังหวะที่เหมาะกับการยิง prewarm_cache() ตามที่ Anthropic แนะนำ คือตอน application startup หรือบน scheduled interval ที่ถี่กว่า TTL เล็กน้อย ถ้าใช้ default TTL 5 นาที ต้อง re-fire pre-warm อย่างน้อยทุก 5 นาที โดยนับตาม wall clock จาก refresh ล่าสุด ไม่ใช่จากเวลาสร้าง ส่วน app ที่มี gap ระหว่าง user request ยาวกว่านั้น Anthropic แนะนำให้ใช้ TTL 1 ชั่วโมงตั้งแต่ต้น
4. Pricing และการ monitor ที่ usage field
ตามตาราง pricing ของ Anthropic prompt cache คิดเงินด้วย multiplier 3 ระดับเมื่อเทียบกับ base input
| Multiplier | Ratio | ตัวอย่างราคา Sonnet 4.6 (base 3 USD ต่อ 1 ล้าน token) |
|---|---|---|
| 5-minute cache write | 1.25 เท่า | 3.75 USD ต่อ 1 ล้าน token |
| 1-hour cache write | 2.0 เท่า | 6.00 USD ต่อ 1 ล้าน token |
| Cache read และ refresh | 0.1 เท่า | 0.30 USD ต่อ 1 ล้าน token |
ราคาเต็มของแต่ละ model ตามที่ Anthropic ระบุในหน้า prompt caching แบ่งเป็น base, 5m write, 1h write, cache read และ output ต่อ 1 ล้าน token ตามลำดับ สำหรับ Claude Opus 4.7/4.6/4.5 คือ 5 / 6.25 / 10 / 0.50 / 25 USD ส่วน Sonnet 4.6/4.5 คือ 3 / 3.75 / 6 / 0.30 / 15 USD และ Haiku 4.5 คือ 1 / 1.25 / 2 / 0.10 / 5 USD multiplier เหล่านี้ stack กับ pricing modifier อื่น เช่น Batch API discount และ data residency ได้
Anthropic เปิดเผยข้อมูล cache ของทุก request ผ่าน usage block ใน response (หรือ message_start event ถ้าใช้ streaming) โดยมี field สำคัญ 3 ตัว
cache_creation_input_tokensคือจำนวน token ที่ถูกเขียนเข้า cache ในรอบนี้ (= cache write)cache_read_input_tokensคือจำนวน token ที่อ่านจาก cache ที่เขียนไว้แล้ว (= cache hit)input_tokensคือจำนวน token หลัง breakpoint สุดท้าย ที่ไม่อยู่ใน cache eligible
สูตร total input ที่ docs ระบุไว้คือ
total_input_tokens = cache_read_input_tokens
+ cache_creation_input_tokens
+ input_tokensตัวอย่างที่ Anthropic ยกในเอกสาร: ถ้า request หนึ่งมี cache content 100,000 token ที่อ่านจาก cache, ไม่มี cache write ใหม่ และมี user message หลัง breakpoint อีก 50 token ค่า cache_read_input_tokens จะเป็น 100,000, cache_creation_input_tokens เป็น 0 และ input_tokens เป็น 50 รวม token ที่ประมวลผลทั้งหมด 100,050 token
5. ขั้นต่ำ token และข้อจำกัดที่ docs เน้น
Anthropic prompt-caching docs ระบุขั้นต่ำของ prompt ที่ cache ได้ แยกตาม model ตามตารางนี้
| Model | ขั้นต่ำที่ cache ได้ |
|---|---|
| Claude Opus 4.7 / 4.6 / 4.5 และ Claude Mythos Preview | 4,096 token |
| Claude Sonnet 4.6 / 4.5 / Opus 4.1 / Opus 4 / Sonnet 4 | 1,024 token |
| Claude Haiku 4.5 | 4,096 token |
| Claude Haiku 3.5 (เหลือเฉพาะ Vertex AI) | 2,048 token |
ถ้า prompt สั้นกว่า threshold ระบบจะรับ request ปกติ แต่ไม่เขียน cache เลย และไม่ return error ใดๆ docs แนะนำให้ verify ด้วยการเช็ค field cache_creation_input_tokens ใน response ถ้าเป็น 0 พร้อมกับ cache_read_input_tokens = 0 แปลว่า prompt ไม่ผ่าน threshold
นอกจากนี้ max_tokens: 0 จะถูก reject ด้วย invalid_request_error ถ้า set field ต่อไปนี้ตามที่ docs ระบุ เพราะแต่ละ field สื่อว่าต้องมี output แต่ budget 0 token produce output ไม่ได้
stream: true- Extended thinking (
thinking.type: "enabled") - Structured outputs (
output_config.format) tool_choice: {"type": "tool", ...}หรือ{"type": "any"}
max_tokens: 0 ยังถูก reject ใน Message Batches request ด้วย Anthropic อธิบายว่า batch processing ไม่มี concept ของ time-to-first-token อยู่แล้ว และ cache entry ที่เขียนระหว่าง batch อาจหมดอายุก่อน follow-up request จะรัน
6. Gotcha ที่ Anthropic เน้นเป็นพิเศษ
หน้า docs เน้น gotcha 5 ข้อที่ทำให้ pre-warm fail แบบไม่ส่ง error chunk ใดๆ กลับมา ดังนั้น dev ที่อ่านหน้านี้ครั้งแรกควรอ่าน 5 ข้อนี้ก่อนเขียน code
Breakpoint ผิดที่ = ไม่ได้ cache เอกสารยกตัวอย่างชัดว่า ถ้า prompt มี static system context อยู่ block 1-5 และ block 6 เป็น per-request context ที่มี timestamp หรือ incoming message การวาง cache_control บน block 6 จะทำให้ hash ของ prefix ต่างกันทุก request ระบบจึงเขียน cache entry ใหม่ทุกรอบและไม่เคยได้ cache hit วิธีแก้คือย้าย breakpoint ไปที่ block 5 ซึ่งเป็น block สุดท้ายที่ stable ข้าม request
Automatic caching ใช้คู่ pre-warm ไม่ได้ เพราะ automatic วาง breakpoint ที่ block สุดท้ายอัตโนมัติ ซึ่งใน context ของ pre-warm คือ placeholder user message (เช่น "warmup") cache key จึงผูกกับ placeholder ไม่ใช่ system prompt และ request จริงที่มี user message ต่างกันจะ miss cache เสมอ Anthropic บอกตรงๆ ว่า pre-warm ต้องใช้ explicit cache breakpoint เท่านั้น
Min token threshold เงียบเกินไป ถ้า system prompt สั้นกว่า 4,096 token สำหรับ Opus 4.7 ระบบจะ accept request และ return response ปกติ แต่ cache_creation_input_tokens จะเป็น 0 และไม่มี cache entry สร้างขึ้น ทำให้ pre-warm ไม่ได้ผล ทั้งที่ดู logs เหมือนทุกอย่างเรียบร้อย วิธี verify คือต้องอ่าน field นี้ใน response ทุกครั้งหลัง pre-warm
Concurrent request ไม่ปลอดภัย เอกสารระบุว่า cache entry จะใช้ได้หลัง response แรกเริ่ม streaming เท่านั้น ถ้า application ส่ง burst request 100 ตัวพร้อมกันตอน app start request แรกจะเขียน cache แต่ที่เหลืออีก 99 ตัวยังไม่เห็น entry และเสีย cache write charge ซ้ำๆ วิธีที่ถูกคือ gate ให้ pre-warm response กลับมาก่อน แล้วค่อยปล่อย user request ต่อ
Workspace isolation ตั้งแต่ 5 กุมภาพันธ์ 2026 เอกสารทางการของ Anthropic ระบุว่า prompt cache เปลี่ยนจาก org-level isolation มาเป็น workspace-level isolation ตั้งแต่ 5 ก.พ. 2026 บน Claude API, Claude Platform on AWS และ Microsoft Foundry (beta) ส่วน Bedrock และ Vertex AI ยังเป็น org-level เหมือนเดิม ดังนั้น application ที่มี multi-workspace ต้อง review caching strategy ใหม่ เพราะ cache ไม่ share ข้าม workspace อีกต่อไป
ในระดับ best practice docs ยังกล่าวถึงอีก 3 จุด คือ การเปลี่ยน tool_choice invalidate messages cache แม้ tools และ system จะไม่เปลี่ยน, การ add หรือ remove image ตำแหน่งใดใน prompt ก็ invalidate messages cache เช่นกัน และ JSON serialization ใน Swift หรือ Go ที่ randomize key order ของ tool_use content block จะทำให้ hash ต่างกันทั้งที่ content เหมือนเดิม จึงต้อง verify ว่า key มี stable ordering เสมอ
7. เมื่อไหร่ควรใช้ pre-warm และเมื่อไหร่ปล่อยให้ traffic warm เอง
การเลือกระหว่าง pre-warming กับ natural cache hit ขึ้นกับ traffic pattern ของ application เป็นหลัก เอกสารของ Anthropic อธิบาย trade-off ไว้ว่า natural cache hit ไม่มี cost overhead เพราะ cache write เกิดตอน user request แรกของรอบใหม่อยู่แล้ว แต่ user คนนั้นต้องรอ prefill เต็มก้อน ส่วน pre-warming ย้าย cache write timing มา ก่อน user มาถึง ทำให้ user เห็นแต่ cache read latency ที่ต่ำ แต่แลกกับ cache write charge ที่อาจเสียฟรีถ้าไม่มี user มาถึงภายใน TTL
| มิติ | Natural cache hit | Pre-warming explicit |
|---|---|---|
| Latency รอบแรกของ user | สูง เพราะต้อง prefill ใหม่ทั้งก้อน | ต่ำ เพราะ cache hit ทันที |
| Cache write timing | เกิดตอน user request แรกของรอบใหม่ | เกิด ก่อน user มาถึง invisible to user |
| Cost overhead | 0 ตามธรรมชาติ แต่ user รอ | 1 cache write ต่อรอบ TTL ถ้าไม่มี user มาภายใน TTL = เสียฟรี |
| เหมาะกับ | App ที่ traffic ต่อเนื่อง (cache refresh ฟรีทุก request) | App ที่ traffic เป็น burst หลัง idle |
| Implementation | ไม่ต้องทำอะไร | เพิ่ม startup hook หรือ cron ยิง max_tokens 0 |
จากตาราง trade-off สรุปเป็น rule of thumb ตามที่ docs ใบ้ไว้ได้ว่า ถ้า traffic ต่อเนื่องและ request ห่างกันน้อยกว่า 5 นาที ก็ไม่จำเป็นต้อง pre-warm เพราะ 5m cache refresh ฟรีทุกครั้งที่ใช้ ถ้า traffic มาเป็นช่วงและห่างกัน 5 นาทีถึง 1 ชั่วโมง ทางเลือกคือสลับไปใช้ TTL 1 ชั่วโมง หรือ schedule pre-warm ทุก 5 นาที โดยเทียบ cost ของ cache write กับ frequency ที่ traffic จะ flow มาจริง ส่วน app ที่มี burst หลัง idle ยาว เช่นเปิดบริการเช้าวันจันทร์หรือหลังคลาส การ pre-warm ก่อน user มาถึงเป็น pattern ที่ Anthropic แนะนำตรงๆ
8. แทน workaround เก่า max_tokens 1
ก่อนที่ Anthropic จะเปิด max_tokens: 0 เป็น official feature บางทีมเคยใช้ max_tokens: 1 แล้วทิ้ง output token ที่ออกมา เพื่อให้ได้ effect คล้าย pre-warm หน้าเอกสารระบุตรงๆ ว่า max_tokens: 0 เป็น preferred approach ด้วย 3 เหตุผล คือ ระบบไม่ produce output จึงไม่มี single-token reply ที่ต้องทิ้ง, ไม่บิล output token เลย และ intent ของ request ชัดเจนว่าเป็น pre-warm ไม่ใช่ real query
ทีมที่ยังมี workaround max_tokens: 1 อยู่ใน code base เก่าจึงควร migrate มาใช้ max_tokens: 0 ตามที่ Anthropic แนะนำ เพราะนอกจากประหยัด output token cost แล้ว ยังตรงกับ official API surface ที่ Anthropic commit ว่าจะดูแลต่อไป
Note: ตัวเลข pricing, model threshold และ behavior ทั้งหมดในบทความนี้ดึงจากหน้า prompt caching docs ของ Anthropic ที่ fetch เมื่อ 15 พ.ค. 2026 ราคา Claude API อาจปรับเปลี่ยนได้ developer ที่กำลัง implement ควรตรวจสอบเลขปัจจุบันจาก docs ทางการก่อน deploy production
สรุป
Pre-warming ใช้ max_tokens: 0 เปลี่ยน timing ของ cache write จาก "ตอน user request แรก" มาเป็น "ก่อน user มาถึง" ทำให้ TTFT ของรอบแรกลดลงจนใกล้ cache hit ตามปกติ Anthropic อธิบายว่า pattern นี้เหมาะกับ application ที่ latency-sensitive และ traffic เป็น burst หลัง idle ส่วน app ที่ traffic ต่อเนื่องไม่จำเป็นต้อง pre-warm เพราะ 5-minute cache refresh ฟรีทุกครั้งที่ใช้อยู่แล้ว
จุดที่ต้องระวังที่สุดคือ explicit cache breakpoint ต้องอยู่บน block ที่ stable ข้าม request ไม่ใช่บน placeholder user message และห้ามใช้ automatic caching คู่ pre-warm เพราะมันจะวาง breakpoint บน last block ที่เป็น placeholder โดยอัตโนมัติ ทำให้ cache key ผูกกับ placeholder และ request จริงจะไม่ hit cache ตลอดกาล นอกจากนี้ต้อง verify ว่า prompt มี token ถึงขั้นต่ำของ model นั้นๆ (4,096 token สำหรับ Opus 4.7 และ Haiku 4.5) เพราะถ้าต่ำกว่านี้ ระบบจะรับ request แต่ไม่เขียน cache และไม่ส่ง error



