AI มองคำว่า 'หมา' กับ 'แมว' ใกล้กันได้ยังไง
AI ไม่เคยลูบขนหมาและไม่เคยได้ยินเสียงเหมียว แต่รู้ว่า 'หมา' กับ 'แมว' อยู่ละแวกเดียวกันบนแผนที่ภาษา หลักการเดียวที่อายุเกือบ 70 ปีนี้คือกระดูกสันหลังของ Spotify Netflix Google และ ChatGPT พร้อมกัน
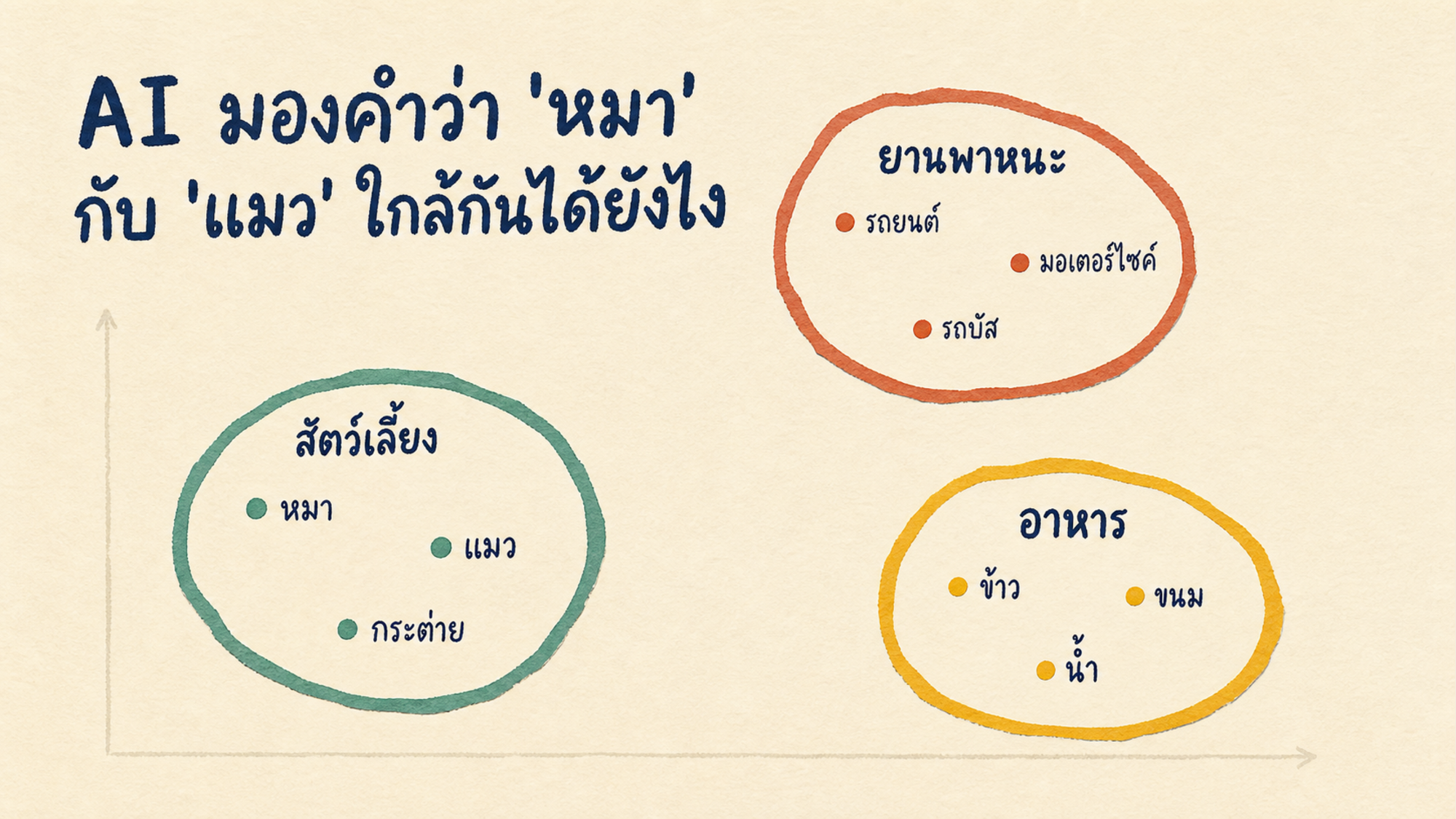
AI ไม่รู้ว่า "หมา" คืออะไร แต่รู้ว่า "หมา" กับ "แมว" อยู่ละแวกเดียวกันบนแผนที่ภาษา กลไกนี้แหละทำให้ Spotify หาเพลงคล้ายให้ฟัง Netflix หาหนังคล้ายให้ดู และ Google หาเจอบทความที่ตอบโจทย์แม้ไม่มีคำเดียวกันกับที่พิมพ์เลยสักคำ บทความนี้จะพาเดินทีละขั้นบนแผนที่ใบนั้น
1. ปริศนาที่เจอทุกวัน แต่ไม่เคยมีใครอธิบาย
ลองนึกถึง 3 อย่างที่ใช้อยู่ทุกวัน
อย่างแรก กดเพลงหนึ่งเพลงใน Spotify แล้วระบบเลื่อนเพลงถัดไปให้ฟัง ฟังแล้วรู้สึกว่า "ใช่ แนวเดียวกัน" ทั้งที่ไม่ใช่ศิลปินเดียวกันและชื่อเพลงไม่ได้คล้ายกันเลย
อย่างที่สอง ดูหนังเรื่องหนึ่งจบบน Netflix แล้วหน้าแรกขึ้น "หนังคล้าย" 5 เรื่อง 4 ใน 5 น่าสนใจจริง
อย่างที่สาม Google ค้น "ปวดท้องช่วงบน" แล้วผลลัพธ์อันดับแรกเป็นบทความเรื่อง "gastritis" ที่ไม่มีคำว่า "ปวดท้อง" อยู่ในบทความเลยสักคำ
ทั้ง 3 อย่างมีอะไรเหมือนกัน คอมพิวเตอร์ไม่ได้ลูบขนหมา ไม่ได้ฟังเพลงด้วยหู ไม่ได้กินยาแก้ปวดท้อง มันรู้ "ความคล้าย" จากไหน
ข่าวดีคือ คำตอบมีตัวเดียวที่อธิบายทั้ง 3 อย่างได้พร้อมกัน นักภาษาศาสตร์ตั้งหลักการนี้ไว้ตั้งแต่ปี 1957 และทุกระบบ AI ในปี 2026 ยังใช้หลักเดียวกัน เปลี่ยนแค่ขนาด หลักนั้นเรียกว่า "แผนที่ภาษา"
2. วิธีเก่าที่ล้มเหลว เพราะมองทุกคำห่างกันเท่ากัน
ก่อนจะเข้าแผนที่ ต้องเข้าใจก่อนว่าวิธีคิดแบบเก่ามันพังตรงไหน
สมมติเอาพจนานุกรมไทย 100,000 คำ มาทำเป็นตู้ล็อกเกอร์ยาว 100,000 ช่อง คำว่า "หมา" จองล็อกเกอร์เลข 4,512 ติดธงไว้ที่ช่องเดียวเท่านั้น ที่เหลืออีก 99,999 ช่องว่างหมด คำว่า "แมว" จองล็อกเกอร์เลข 71,894 ติดธงที่ช่องเดียวอีกเช่นกัน คำว่า "รถยนต์" จองช่อง 23,007 คำว่า "ตู้เย็น" จองช่อง 89,003 เลขช่องเป็นแค่ป้าย ID ไม่ได้บอกตำแหน่งว่าใครอยู่ใกล้ใคร
วิธีนี้มีชื่อทางเทคนิคว่า one-hot encoding (วิธีแทนคำด้วยรายการยาวๆ ที่มีเลข 1 ตัวเดียวที่ตำแหน่งของคำนั้น และเลข 0 ที่ตำแหน่งอื่นทั้งหมด)

ลองคำนวณดูว่า "หมา" ห่างจาก "แมว" เท่าไร แต่ละคำติดธงคนละช่อง ไม่มีช่องไหนซ้อนกันเลย ระยะห่างจึงเท่ากับระยะห่างจาก "หมา" ไป "รถยนต์" และเท่ากับระยะห่างจาก "หมา" ไป "ตู้เย็น" ทุกคู่ของคำห่างกันเท่ากันหมด
นี่คือเหตุผลที่ search engine ก่อนยุค embedding ทำได้แค่ Ctrl+F ตามตัวอักษรตรง พิมพ์ "ปวดท้อง" ก็ค้นได้แค่บทความที่มีคำว่า "ปวดท้อง" ตรงตัว บทความที่เขียนว่า "gastritis" หรือ "อาหารไม่ย่อย" ระบบมองไม่เห็นเลย เพราะทุกคำเป็นเกาะของตัวเอง
นักวิจัย Bengio และทีมเรียกปัญหานี้ในปี 2003 ว่า curse of dimensionality ตู้ล็อกเกอร์ยาวเป็นแสนช่อง แต่ทุกคำเป็นเกาะ ระบบไม่มีทางเดาความคล้ายได้เลย
3. หลักการเดียวที่เปลี่ยนทุกอย่าง ความหมายอยู่ที่เพื่อนข้างเคียง
ในปี 1957 นักภาษาศาสตร์ชื่อ J.R. Firth เขียนประโยคหนึ่งที่กลายเป็นวรรคทองของวงการ
You shall know a word by the company it keeps
แปลตรงตัวว่า "อยากรู้ความหมายของคำไหน ดูที่เพื่อนของมัน"
Firth ยกตัวอย่างคำว่า "ass" ในภาษาอังกฤษ ปกติแปลว่า "ลา" แต่ถ้าเจอในประโยคอย่าง "you silly ass" หรือ "don't be such an ass" เราจะเข้าใจทันทีว่าคำนี้หมายถึง "คนโง่" ไม่ใช่ "ลา" เหตุที่รู้คือเพื่อนของคำมันเปลี่ยน คำว่า "silly" และ "don't be such" เป็นเพื่อนที่บอกความหมายใหม่
ลองทดสอบกับภาษาไทยทันที คำว่า "กิน" ปรากฏใกล้คำว่า "ข้าว" "น้ำ" "ขนม" "ยา" บ่อยที่สุด คำว่า "ดู" ปรากฏใกล้ "หนัง" "ละคร" "TV" คำว่า "ขับ" ปรากฏใกล้ "รถ" "มอเตอร์ไซค์" "ทาง" ใครที่ไม่เคยเรียนภาษาไทยมาก่อน อ่านประโยคไทยเป็นล้านๆ ประโยค ก็พอจะเดาได้ว่า "กิน" "ดู" "ขับ" เป็นคนละกลุ่มกัน เพราะเพื่อนของคำมันคนละกลุ่ม
นี่คือหลักการที่นักภาษาศาสตร์ Zellig Harris สรุปไว้ตั้งแต่ปี 1954 ว่าคำที่ปรากฏในบริบทคล้ายกัน มีแนวโน้มมีความหมายคล้ายกัน ส่วน Firth สรุปด้วยวรรคทองข้างบนในปี 1957 ทุกระบบ AI ที่เรียนความหมายของคำหลังจากนั้น ตั้งแต่ word2vec ในปี 2013 จนถึง LLM ในปี 2026 ใช้หลักนี้เหมือนกันหมด เปลี่ยนแค่ขนาดของข้อมูลและจำนวนมิติของแผนที่
4. แผนที่ภาษา ทุกคำได้พิกัดของตัวเอง
ลืมตู้ล็อกเกอร์ทิ้งไป
ลองนึกถึงแผนที่ใบใหญ่ที่จัดวางทุกคำตามเพื่อนข้างเคียง คำที่มีเพื่อนคล้ายกัน อยู่ใกล้กัน คำที่มีเพื่อนคนละกลุ่ม อยู่คนละมุม ระบบไม่ต้องมาบอกว่า "หมาเป็นสัตว์เลี้ยง" หรือ "รถยนต์เป็นยานพาหนะ" เพียงแค่ป้อนข้อความให้อ่านมากๆ จุดของแต่ละคำจะเลื่อนเข้ามาหากันเอง
ผลลัพธ์ตามธรรมชาติคือ "หมา" "แมว" "กระต่าย" "นก" ไปกองอยู่มุมหนึ่ง เพราะปรากฏใกล้คำว่า "เลี้ยง" "ขน" "น่ารัก" "อาหารสัตว์" บ่อยพอๆ กัน ส่วน "รถยนต์" "มอเตอร์ไซค์" "รถบัส" ไปกองอีกมุม เพราะปรากฏใกล้ "ขับ" "ล้อ" "เครื่องยนต์" "น้ำมัน" และ "ข้าว" "ขนม" "น้ำ" ไปกองอีกมุม เพราะปรากฏใกล้ "กิน" "อิ่ม" "อร่อย"
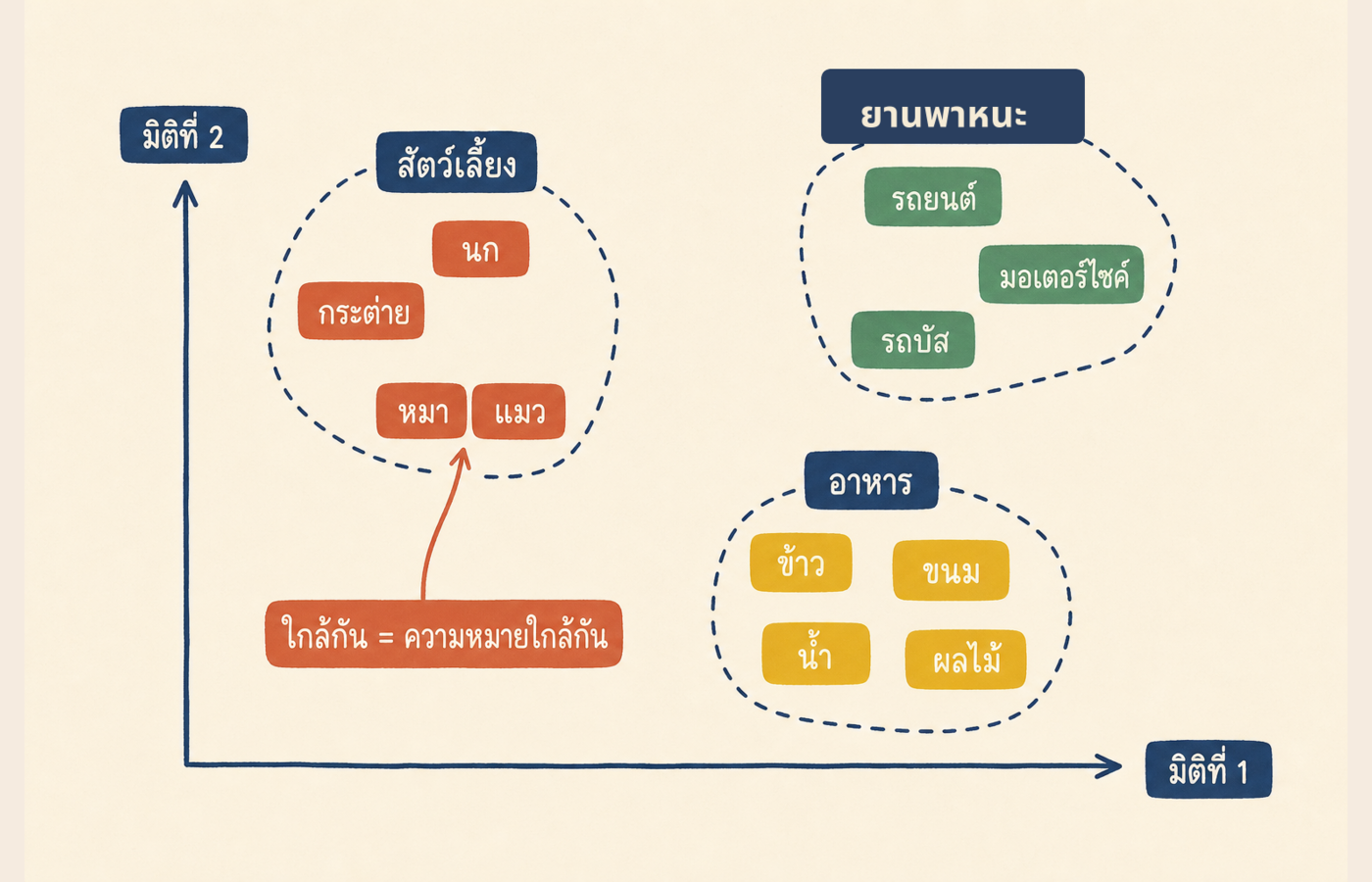
มีอีกจุดที่ต้องเข้าใจเพิ่ม แผนที่ที่ AI ใช้จริงไม่ใช่แผนที่ 2 มิติแบบ Google Maps แต่เป็นแผนที่ที่มีหลายร้อยมิติ คำว่า "มิติ" ในที่นี้คือแกนหนึ่งของพิกัด แต่ละแกนบอกอะไรคนละอย่าง อาจมีแกน "ความเป็นสัตว์" แกน "ความน่าเลี้ยง" แกน "ขนาดเล็กถึงใหญ่" และอีกหลายร้อยแกน
คนเรานึกภาพเกิน 3 มิติไม่ออกอยู่แล้ว ไม่ต้องพยายามจินตนาการตาม ขอแค่จำว่ามันคือพิกัดของแต่ละคำที่มีหลายค่ามากๆ ก็พอ
ตัวเลขเปลี่ยนตามรุ่นของ model
- word2vec รุ่นแรกในปี 2013 ใช้ 100 ถึง 1,000 มิติ ค่ายอดนิยมคือ 300
- BERT ในปี 2018 ใช้ 768 มิติสำหรับรุ่นเล็ก และ 1,024 สำหรับรุ่นใหญ่
- text-embedding-3 ของ OpenAI ในปี 2024 ใช้ 1,536 มิติสำหรับรุ่นเล็ก และ 3,072 สำหรับรุ่นใหญ่
มิติเยอะขึ้น แผนที่จัดได้ละเอียดขึ้น แต่หลักการเดียวกันตลอด คำที่อยู่ใกล้กันคือคำที่มีความหมายใกล้กัน
ตำแหน่งของคำบนแผนที่นี้แหละที่นักวิจัยเรียกว่า embedding และเป็นคำตอบของ "ความหมาย" ในมุมมองของ AI ความหมายของ "หมา" สำหรับ AI ไม่ใช่คำอธิบายในพจนานุกรม แต่คือที่อยู่บ้านบนแผนที่ มีเพื่อนข้างบ้านคือ "แมว" "สุนัข" "puppy"
5. กลไกเวทมนตร์ king − man + woman ≈ queen
ตรงนี้เป็นจุดที่หลายคนตอนเห็นครั้งแรกร้องว่าเหมือนเวทมนตร์
ลองเอา vector (ชุดตัวเลขที่บอกพิกัดของคำในแผนที่) ของ 4 คำมาบวกลบกันแบบเลขประถม
vec(king) − vec(man) + vec(woman)
ผลที่ได้ออกมาเป็นพิกัดหนึ่ง แล้วลองหาว่าคำไหนอยู่ใกล้พิกัดนี้ที่สุดบนแผนที่ คำตอบคือ "queen"
เห็นครั้งแรกแล้วงง ไม่มีใครสอนคอมพิวเตอร์เรื่อง "เพศ" หรือ "ราชวงศ์" สักคำเดียว ทำไมเลขประถมแบบนี้ถึงให้คำตอบที่มีความหมายตรงตามที่เราคิด
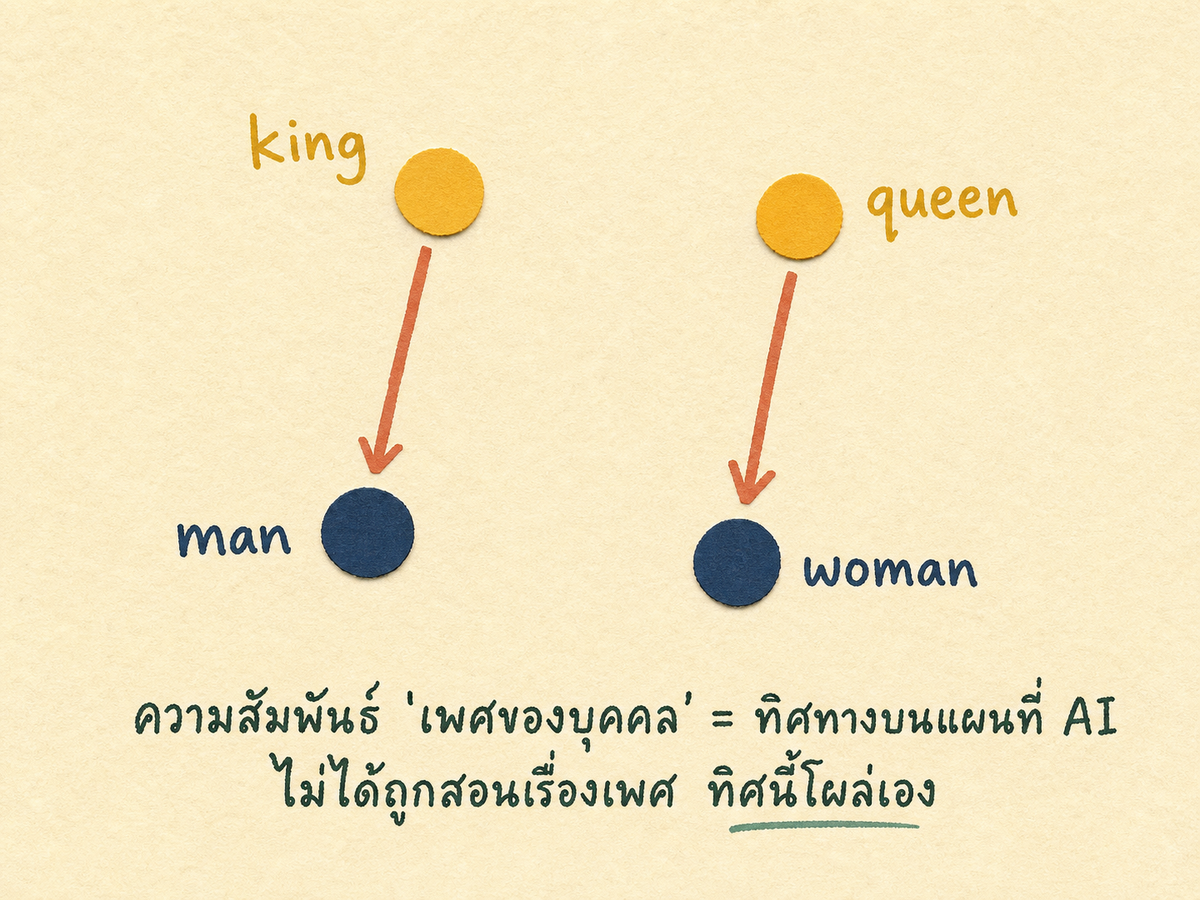
เฉลยไม่ใช่เวทมนตร์ แต่เป็นเรขาคณิตของแผนที่ บนแผนที่ที่จัดดีๆ ทิศทางจาก "king" ไป "man" เป็นทิศเดียวกับทิศทางจาก "queen" ไป "woman" เพราะทั้ง 2 คู่มีความสัมพันธ์เดียวกัน คือ "เพศชายของบุคคลในตำแหน่งเดียวกัน" ความสัมพันธ์นี้โผล่ขึ้นมาเป็นทิศทางบนแผนที่อัตโนมัติ ไม่มีใครไปเขียนกฎว่า "king คือผู้ชาย queen คือผู้หญิง" ไว้ในฐานข้อมูล ระบบเรียนเองจากการที่คำเหล่านี้ปรากฏในบริบทไหนบ้าง
ทีม Mikolov จาก Google สาธิตอีกคู่ที่ดังพอกันใน paper ปี 2013
The result of a vector calculation vec('Madrid') - vec('Spain') + vec('France') is closer to vec('Paris') than to any other word vector
หักความเป็น "Spain" ออกจาก "Madrid" จะได้ทิศทางของ "ความเป็นเมืองหลวง" บวกกลับเข้ากับ "France" ก็ได้ "Paris" ทิศทาง "ความเป็นเมืองหลวงของประเทศ" โผล่ออกมาเองเช่นกัน ทั้งหมดนี้ทีม Google ฝึกบนข้อความ 1.6 พันล้านคำใน paper ต้นทาง word2vec ใช้เวลาฝึกไม่ถึง 1 วัน
หลักที่ต้องจำคือ ความสัมพันธ์ระหว่างคำคู่ใดๆ บนแผนที่ embedding คือทิศทาง ไม่ใช่กฎที่เขียนไว้ในฐานข้อมูล ทิศทางพวกนี้โผล่ออกมาเองเพราะข้อมูลฝึกมีรูปแบบเดิมซ้ำๆ
6. ทำไมหลักนี้ขับเคลื่อน Spotify Netflix Google ChatGPT พร้อมกัน
กลับไปที่ 3 ปริศนาตอนเปิดบทความ
Spotify หาเพลงคล้ายยังไง ระบบแปลงทุกเพลงเป็นพิกัดบนแผนที่เพลง ไม่ใช่แผนที่คำ แต่หลักการเดียวกัน เพลงที่คนกลุ่มเดียวกันชอบฟังต่อกันบ่อยๆ ระบบจะดันให้อยู่ใกล้กันบนแผนที่ เพลงที่มีป้ายกำกับคล้ายกันก็เช่นกัน "เพลงคล้าย" ของ Spotify คือเพื่อนบ้านของเพลงปัจจุบันบนแผนที่นั้น
Netflix หาหนังคล้ายและ Amazon หาสินค้าคล้ายใช้หลักเดียวกัน เปลี่ยนจากแผนที่คำเป็นแผนที่หนัง แผนที่สินค้า หรือแม้แต่แผนที่ผู้ใช้ ทุกอย่างกลายเป็นจุดบนแผนที่หลายมิติ และ "ของคล้ายกัน" คือเพื่อนบ้าน
Google ค้น "ปวดท้องช่วงบน" แล้วเจอบทความเรื่อง gastritis ทำงานยังไง
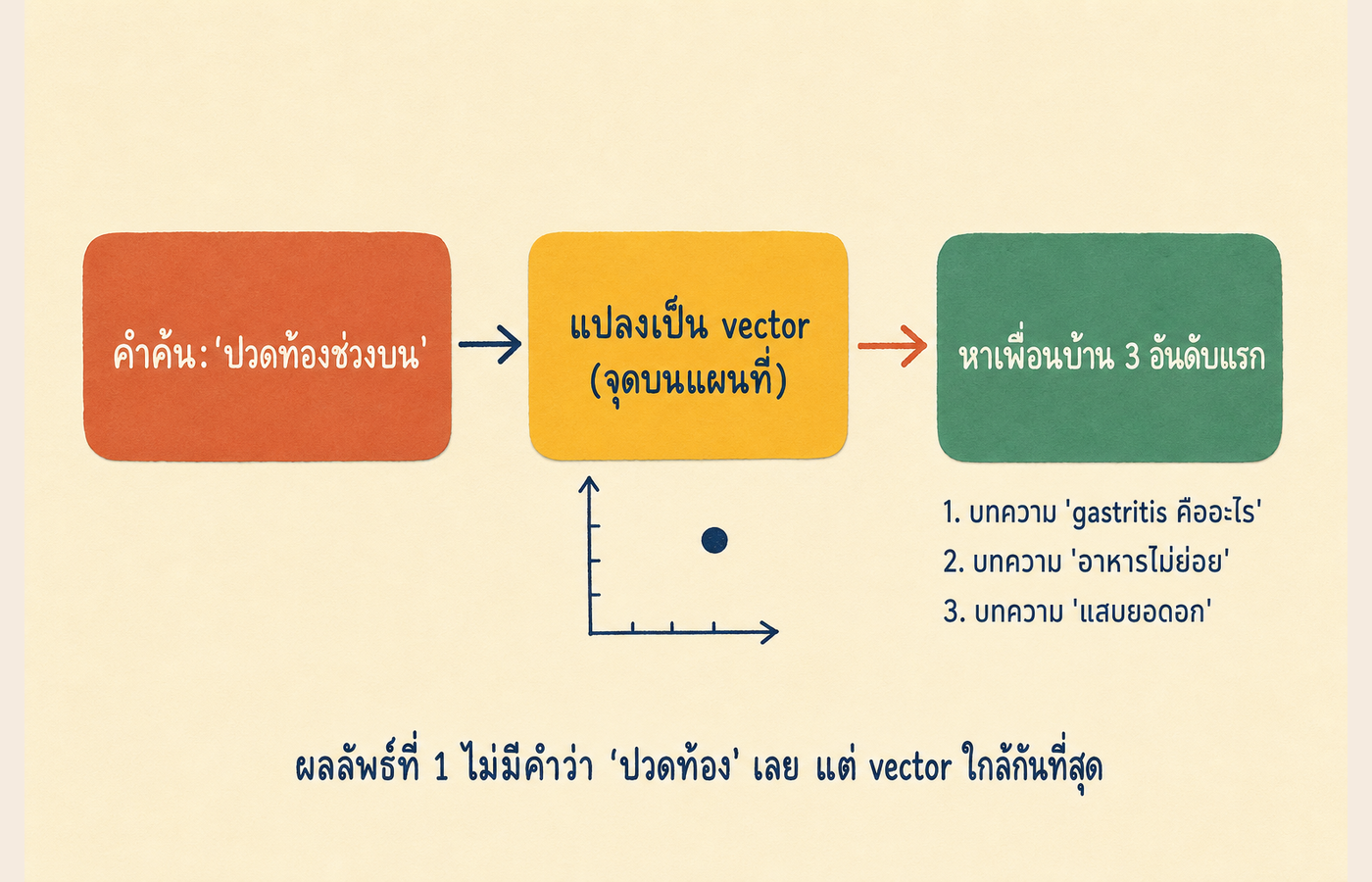
ระบบทำ 3 ขั้น
- รับคำค้น "ปวดท้องช่วงบน" แล้วแปลงประโยคทั้งหมดเป็นพิกัด 1 จุดบนแผนที่
- ระบบมีบทความเป็นล้านๆ บทความที่แปลงเป็นจุดบนแผนที่เดียวกันไว้ก่อนแล้ว
- หาบทความที่จุดอยู่ใกล้จุดของคำค้นที่สุด ดึงมา 3 อันดับแรก
บทความเรื่อง gastritis อยู่ใกล้ที่สุดเพราะในข้อมูลฝึก คำว่า gastritis ปรากฏในบริบทคล้ายกับคำว่า "ปวดท้อง" "อาหารไม่ย่อย" "แสบยอดอก" บ่อยมาก แม้ในตัวบทความจะไม่มีคำว่า "ปวดท้อง" สักคำเดียว แผนที่จัดให้อยู่ใกล้กันอยู่แล้ว
LLM อย่าง Claude GPT Gemini ก็ใช้แผนที่นี้เป็นชั้นแรกเสมอ ทุกคำที่พิมพ์เข้าไปใน ChatGPT ระบบจะแปลงเป็นพิกัดบนแผนที่ก่อน แล้วค่อยส่งต่อให้ส่วนที่ทำหน้าที่คิดต่อ หลักการของ Firth ปี 1957 ยังคงเป็นกระดูกสันหลังของ AI ปี 2026
7. ข้อจำกัดที่ควรรู้
แผนที่ embedding ไม่ได้สมบูรณ์แบบ มี 3 ข้อจำกัดที่ควรเข้าใจ
คำพ้องรูปจัดการยาก คำว่า "ขาว" หมายถึงสีก็ได้ ความบริสุทธิ์ก็ได้ ชื่อคนก็ได้ บนแผนที่รุ่นเก่าอย่าง word2vec คำว่า "ขาว" มีจุดเดียว จึงพยายามอยู่ตรงกลางระหว่าง 3 ความหมาย ไม่ได้ใกล้กลุ่มไหนเลยจริงๆ ปัญหานี้เรียกว่า polysemy (คำที่มีหลายความหมาย) แผนที่รุ่นใหม่ตั้งแต่ BERT ในปี 2018 แก้ด้วยการให้คำเดียวกันได้พิกัดต่างกันตามประโยค "ธนาคารริมแม่น้ำ" กับ "ธนาคารฝากเงิน" คำว่า "ธนาคาร" ได้คนละพิกัด
อคติติดมาจากข้อมูล เพราะแผนที่จัดวางคำตามที่ปรากฏในข้อมูลจริง ทุกรูปแบบทางสังคมที่อยู่ในข้อมูลก็ถูกฝังเข้าไปด้วย มีการทดลองที่พบว่า word2vec ที่ฝึกบน Google News ให้ผลลัพธ์ "man → computer programmer" ใกล้เคียงกับ "woman → homemaker" เพราะใน corpus (กองข้อความที่ใช้สอน AI) อาชีพ "computer programmer" ปรากฏใกล้คำว่า "man" บ่อยกว่า "woman" หลักเดียวกันที่ทำให้ "หมา" อยู่ใกล้ "แมว" ก็ฝังภาพเหมารวมทางเพศ อาชีพ และเชื้อชาติเข้าไปในแผนที่ ไม่มี embedding ตัวไหนที่เป็นกลางโดยธรรมชาติ
แผนที่ของแต่ละ model ไม่ใช่อันเดียวกัน แผนที่ของ Claude ไม่ใช่แผนที่ของ GPT ไม่ใช่แผนที่ของ Gemini เพราะแต่ละ model ฝึกคนละข้อมูล จัดวางต่างกัน เอา vector จาก model หนึ่งไปเทียบกับอีก model ตรงๆ ไม่ได้ ต้องผ่านการแปลงก่อน
แม้จะมีข้อจำกัด หลักการพื้นฐานยังคงเดิม ความหมาย = พิกัดบนแผนที่ที่จัดวางตามเพื่อนข้างเคียง ในปี 2031 หรือ 2041 หลักของ Firth ก็ยังเป็นพื้นฐาน เพราะเป็นวิธีเดียวที่ AI เรียนความหมายได้โดยไม่ต้องมีประสบการณ์ตรงในโลกจริง
8. ปิดท้าย หลักเดียวที่ทุก AI พึ่งพา
สรุปทั้งบทความให้ลงในประโยคเดียว
ความหมายของคำใน AI คือพิกัดบนแผนที่หลายมิติที่จัดวางตามว่า คำไหนปรากฏใกล้คำไหนในข้อมูลฝึก
ที่น่าทึ่งคือ หลักนี้ไม่ใช่ของใหม่ Firth เขียนวรรคทอง "อยากรู้ความหมายของคำไหน ดูที่เพื่อนของมัน" ไว้ตั้งแต่ปี 1957 อายุเกือบ 70 ปี ผ่านยุคของ word2vec ในปี 2013 ผ่านยุคของ BERT ในปี 2018 ผ่านมาถึงยุคของ Claude GPT Gemini ในปี 2026 หลักการเดียวยังเป็นกระดูกสันหลังของทุกระบบ เปลี่ยนแค่ขนาดและความละเอียดของแผนที่
หลักการที่อยู่ทนข้ามยุคขนาดนี้ มีแนวโน้มจะอยู่ต่อไปอีกนาน
แหล่งอ้างอิง
- Efficient Estimation of Word Representations in Vector Space (Mikolov et al. 2013)
- Distributed Representations of Words and Phrases and their Compositionality (Mikolov et al. 2013)
- GloVe: Global Vectors for Word Representation (Pennington, Socher, Manning 2014)
- Distributional Structure (Harris 1954)
- A Neural Probabilistic Language Model (Bengio et al. 2003)
- Word2vec บน Wikipedia
- Word embedding บน Wikipedia
- OpenAI text-embedding-3 documentation
- Distributional Hypothesis บน ACL Wiki



