AI สร้างรูปจากประโยคเดียวได้ยังไง คำตอบที่ทำให้คุณเห็น Midjourney เป็นคนละตัว
AI ไม่ได้วาดรูปจากศูนย์ มันลบความมั่วออกจากผ้าใบจุดมั่วๆ ทีละขั้นจนเหลือภาพ เข้าใจ 5 หลักการนี้ครั้งเดียว ใช้ได้กับ Midjourney DALL-E และทุก tool ที่จะออกในอนาคต

AI ไม่ได้วาดรูปขึ้นมาจากศูนย์ มันลบ noise ออกจากผ้าใบมั่วๆ จนเหลือภาพ
ฟังดูแปลกใช่ไหม เพราะ Midjourney กับ DALL-E ที่คุณใช้พิมพ์ประโยคเดียวแล้วได้รูปสวย จริงๆ แล้วมันเริ่มจากภาพที่เป็นจุดมั่วๆ เหมือนทีวีไม่มีสัญญาณ จากนั้นค่อยๆ ขัดความมั่วออกทีละขั้น 50 รอบ จนเหลือภาพที่คุณเห็น
ที่น่าทึ่งกว่านั้นคือ การคิดแบบนี้คือเหตุผลทั้งหมดที่ทำให้ AI สร้างรูปเก่งขึ้นแบบก้าวกระโดดในปี 2021-2022 หลักการ 5 ข้อในบทความนี้คือสัญชาตญาณที่ใช้ได้ข้าม tool ข้ามเวอร์ชัน ครั้งหน้าคุณเปิด Midjourney จะมองมันเป็นคนละตัวเลย
ปริศนาที่คุณใช้ทุกวันแต่ไม่เคยรู้คำตอบ
ลองนึกภาพ คุณพิมพ์ "แมวใส่หมวกพ่อมดในป่ายามค่ำคืน" ลง Midjourney ผ่านไป 30 วินาที ได้รูปสวยเฉียบที่ไม่เคยมีอยู่บนโลกมาก่อน
คำถามง่ายๆ รูปนี้มาจากไหน
คนส่วนใหญ่จะเดา 2 อย่าง
แบบที่ 1 AI คงมีคลังภาพยักษ์ ไปหารูปแมว รูปหมวกพ่อมด รูปป่ายามค่ำคืน มาแปะกัน
แบบที่ 2 AI ฉลาดมาก มันวาดรูปขึ้นมาเองจากความว่างเปล่า เหมือนศิลปินที่นั่งวาดบนกระดาษเปล่า
คำตอบจริงคือ ผิดทั้งคู่
ความจริงน่าทึ่งกว่าทั้ง 2 แบบมาก AI ไม่ได้เก็บรูปไว้ในกล่อง และก็ไม่ได้วาดจากศูนย์ มันเริ่มจาก "ผ้าใบที่เต็มไปด้วยจุดมั่วๆ" แล้วค่อยๆ ลบความมั่วออกทีละนิด ทีละนิด จนเหลือภาพแมวใส่หมวกพ่อมดที่คุณเห็น
ฟังดูเหมือนกายกรรม แต่นี่คือกลไกจริง และพอเข้าใจครั้งเดียว คุณจะใช้ AI สร้างรูปได้เก่งขึ้นทันที เพราะรู้ว่าจริงๆ มันทำงานยังไง
ทำไมการ "วาดจากศูนย์" มันยากเกินไปสำหรับ AI
ก่อนจะเข้าหลักการ มาดูก่อนว่าทำไม AI ถึงไม่ "วาดจากศูนย์" เหมือนที่เราเดา
รูปขนาด 512×512 pixel หนึ่งใบ ประกอบด้วยจุดสี 786,432 ค่า (ความกว้าง 512 คูณ ความยาว 512 คูณ 3 ช่องสี RGB) เพราะแต่ละจุดมี 3 ค่า แดง เขียว น้ำเงิน
ถ้าให้ AI ตอบทุก 786,432 ค่าให้ถูกต้องในครั้งเดียว เหมือนให้คุณเขียนนิยาย 200 หน้าโดยพิมพ์ทั้งเล่มในครั้งเดียวห้ามแก้ ไม่มีย้อนกลับ ไม่มีอ่านทบทวน เป็นไปไม่ได้ในทางปฏิบัติเลย
นักวิจัยเลยต้องคิดวิธีใหม่ ถ้าโจทย์ใหญ่ใบเดียวมันยากเกินไป ก็แตกมันเป็นโจทย์เล็กจำนวนมากที่ทำซ้ำได้ ให้แต่ละโจทย์เล็กเป็นเรื่องที่ network (สมองเทียมที่จำลองการเชื่อมต่อของเซลล์ประสาท) เรียนได้ง่าย แล้วเอามาต่อกัน
paper "Denoising Diffusion Probabilistic Models" ของทีม Ho, Jain, Abbeel ที่ตีพิมพ์ใน NeurIPS 2020 วางรากฐานของวิธีคิดนี้ พวกเขาแตกการสร้างรูป 1 ใบ เป็นโจทย์ย่อย 1,000 ขั้นที่เหมือนกันเป๊ะ แต่ละขั้น network ทำงานเดียวคือลบ noise ก้อนเล็กๆ ที่อยู่ในภาพตอนนี้ ตราบใดที่ noise ที่เติมแต่ละขั้นเป็น noise แบบ Gaussian ขนาดเล็ก network ที่ใช้ก็ออกแบบให้ง่ายมากได้
ผลลัพธ์ การแตกปัญหายาก 1 ครั้ง เป็นปัญหาง่าย 1,000 ครั้งที่หน้าตาเหมือนกัน ทำให้ network ไม่ต้องเก่งเรื่อง "วาดทั้งภาพ" เลย แค่เก่งเรื่อง "ทาย noise ก้อนเล็กๆ" พอเท่านั้น

หลักการที่ 1: ลบความมั่วทีละนิดง่ายกว่าวาดทีเดียว
มีคำพูดของ Michelangelo ประมาณว่า ตัวรูปนั้นอยู่ในก้อนหินอ่อนอยู่แล้ว เขาแค่เอาส่วนเกินออกเท่านั้น
AI ที่สร้างรูปทำงานแบบเดียวกัน
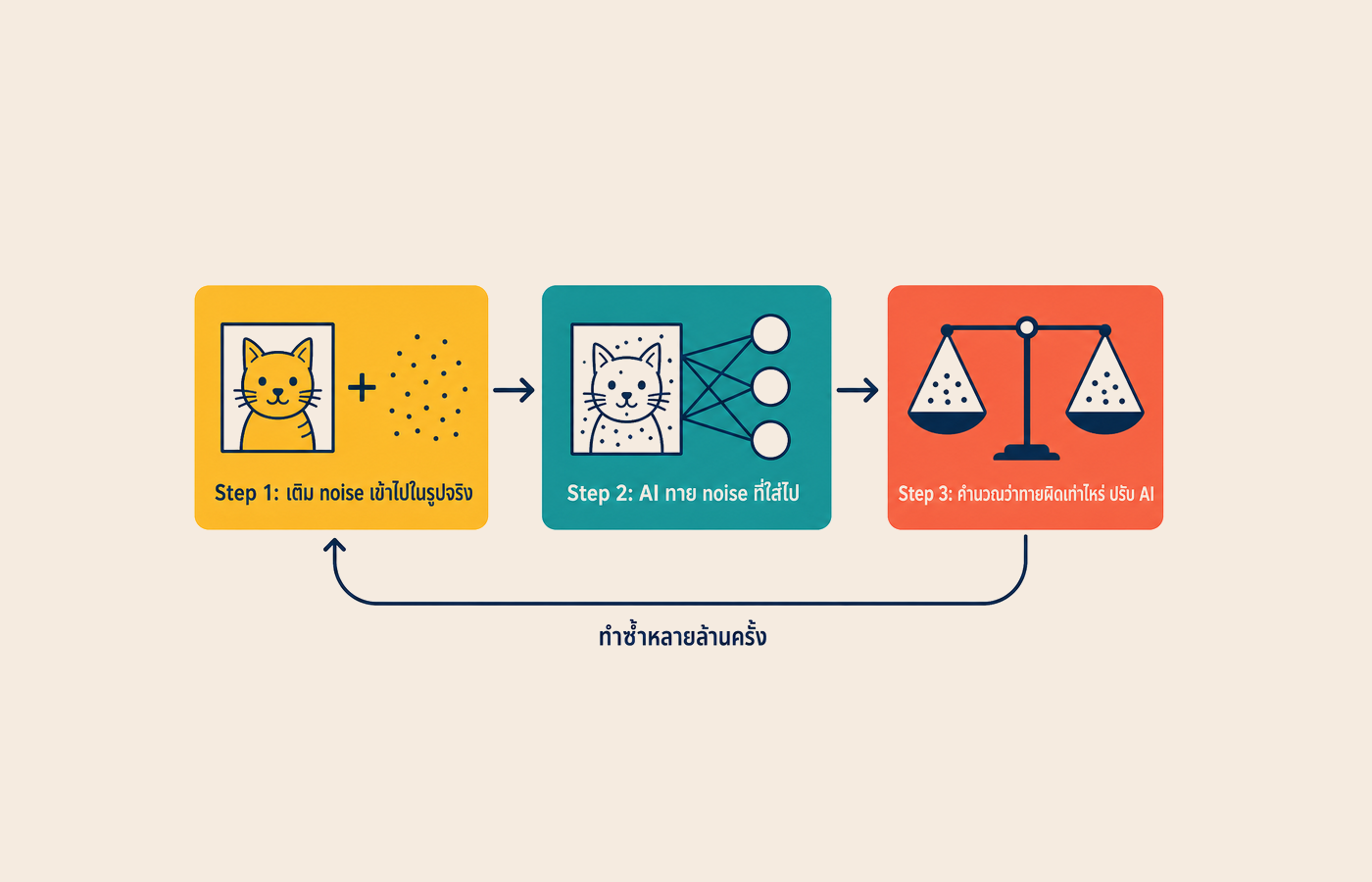
มันไม่ได้เริ่มจากกระดาษเปล่า แต่เริ่มจากผ้าใบที่เต็มไปด้วยจุดมั่วล้วน เหมือนทีวีตอนสัญญาณตัด นักวิจัยเรียกผ้าใบมั่วแบบนี้ว่า Gaussian noise (จุดสีกระจายแบบสุ่ม ไม่มีลวดลายอะไรเลย) จากนั้นทุกขั้นตอน AI จะ "ขัดความมั่วออกนิดเดียว" 50 รอบบ้าง 1,000 รอบบ้าง แล้วแต่การตั้งค่าของแต่ละ tool
ทำไมแตกเป็น 50-1,000 ขั้นย่อยถึงง่ายกว่าวาดในขั้นเดียว
เพราะแต่ละขั้น AI แค่ต้องตอบคำถามเล็กๆ ข้อเดียว "noise น่าจะออกจากตรงไหน" คล้ายช่างขัดประติมากรรมที่ค่อยๆ ขัดผิวหินอ่อนทีละจุด ไม่ใช่นักปั้นที่ต้องสร้างรูปทั้งใบจากดินก้อนเดียว
นี่คือไอเดียแรกที่เปลี่ยนทุกอย่างในวงการ AI สร้างรูปตั้งแต่ปี 2020

หลักการที่ 2: AI เรียนทักษะนี้ได้ฟรี ครูสอนซ่อนอยู่ในตัวข้อมูล
ปริศนาต่อมา AI ต้องเรียน "ทักษะลบ noise" จากตัวอย่างจำนวนมหาศาล แต่ใครเป็นคนสอน ใครจะมานั่งบอกทีละรูปว่า "นี่คือ noise ออกถูกแล้ว" สำหรับรูป 5,000 ล้านรูปบนเว็บ
คำตอบฉลาดมาก AI สร้างแบบฝึกหัดเองได้ฟรี ทุกใบ
ขั้นตอนคือ
เอารูปจริงสวยๆ มา 1 รูป เช่น รูปแมวบนหลังคาที่ใครคนหนึ่งถ่ายไว้
เติม noise ลงไปเอง ตามจำนวนที่สุ่มเลือก เช่น 30% ของจุดทั้งภาพ
ส่งภาพที่เลอะแล้วให้ network ดู พร้อมโจทย์ "ทาย noise ก้อนที่ฉันเพิ่งเติมไปนะ"
network ทาย ส่งคำตอบกลับมา
เปรียบเทียบคำตอบกับ noise จริงที่เราเป็นคนใส่ ผิดเท่าไหร่ก็ปรับ network ให้ทายแม่นขึ้น
ประเด็นที่สำคัญคือ "เพราะ AI เป็นคนใส่ noise เอง เลยรู้คำตอบที่ถูกอยู่แล้ว"
ลองนึกภาพแบบในออฟฟิศดูหน่อย เหมือนคุณถ่ายเอกสาร 1 ฉบับ แล้วเอาน้ำสาดให้เลอะเอง จากนั้นฝึกตัวเองอ่านลายมือบนกระดาษเปียก คุณรู้คำตอบที่ถูกอยู่ตลอด เพราะถือต้นฉบับไว้ในมืออีกฝั่ง ไม่ต้องไปจ้างใครมาเฉลย
ผลลัพธ์ของการที่ AI สร้างแบบฝึกหัดเองได้ฟรี
รูปบนเว็บ 5,000 ล้านรูป ทุกใบกลายเป็นแบบฝึกหัดได้หลายร้อยครั้ง ด้วยระดับ noise ที่ต่างกัน ขยายขนาดการฝึกได้เท่าขนาดของอินเทอร์เน็ตเลย
นี่คือเหตุผลใหญ่ที่ AI สร้างรูปก้าวกระโดดในปี 2021-2022 ไม่ใช่เพราะใครค้นพบ algorithm พิเศษ แต่เพราะวิธีฝึกแบบนี้ขยายได้ในระดับที่ model สร้างรูปรุ่นก่อนๆ ทำไม่ได้
หลักการที่ 3: ทุกขั้น AI ตอบคำถามเดียว ไม่พยายามทำหลายอย่างพร้อมกัน
นี่คือรายละเอียดเล็กๆ ที่ทำให้ diffusion model ดีกว่า model สร้างรูปรุ่นก่อนหน้า เช่น GAN (model สร้างรูปยุคก่อนที่ใช้กันก่อนปี 2020)
GAN ในยุคก่อน พยายามให้ network "เดาภาพสุดท้ายควรเป็นยังไง" จาก noise ในครั้งเดียว ผลคือเก่งบางทีพังบางที ภาพออกมาไม่สมจริงในรายละเอียด
diffusion model ใช้วิธีต่าง ทุกขั้นไม่พยายามทาย "ภาพสุดท้ายควรเป็นยังไง" ทันที แต่ทายแค่ "noise ก้อนนี้ที่อยู่ตรงนี้ น่าเอาออกยังไง"
ฟังเหมือนเรื่องเทคนิค แต่ผลกระทบมหาศาล
เปรียบเทียบให้เห็นภาพ ช่างขัดเงาที่ขัดทีละจุดเล็กๆ จะทำงานละเอียดได้ดีกว่าช่างที่ต้องวาดภาพเหมือนทั้งใบในครั้งเดียวมาก
เพราะ AI ใช้ความสามารถไปขัดทีละนิด ไม่ใช่เดาทุกอย่างใน 1 ครั้ง รายละเอียดเช่นเส้นขนแมว แสงสะท้อนในตา รอยพับของผ้า เลยออกมาคมกว่าเดิมมาก เทคนิคทาย noise ตรงๆ แบบนี้มีพื้นฐานคณิตศาสตร์ที่หนักแน่น เป็นเหตุผลว่าทำไมภาพออกมาคุณภาพสูงกว่ารุ่นเก่าชัดเจน
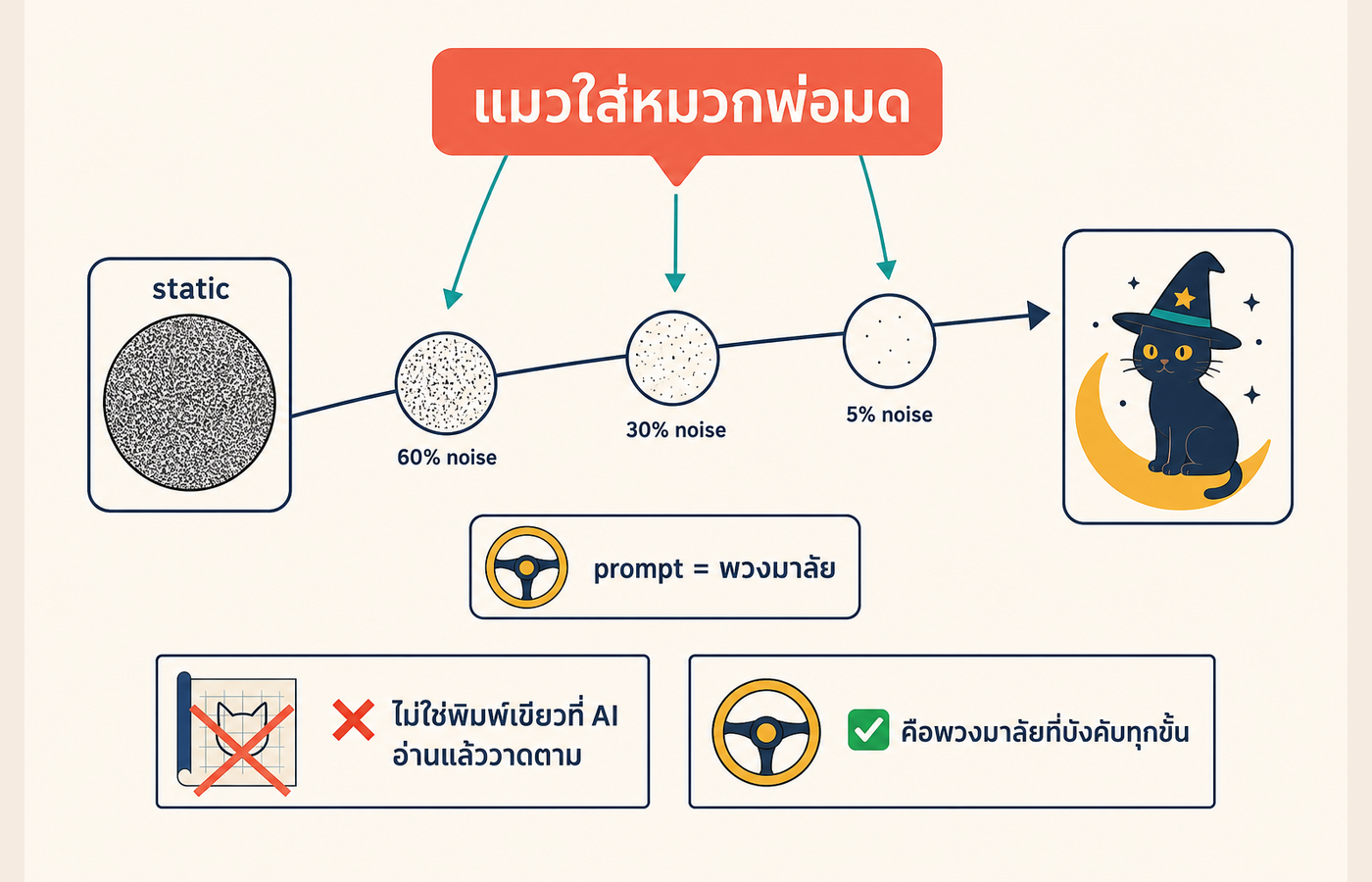
หลักการที่ 4: prompt ทำหน้าที่เป็นพวงมาลัย ไม่ใช่พิมพ์เขียว
จุดที่หลายคนเข้าใจผิดที่สุดเกี่ยวกับ prompt คือคิดว่า prompt อธิบายภาพให้ AI เข้าใจ แล้ว AI ก็อ่านแล้ววาดตาม
ผิดครับ
ความจริงคือ prompt ทำหน้าที่ "ผลักทิศทางการลบ noise ตลอดทั้ง 50 ขั้น" ไม่ใช่พิมพ์เขียวที่ AI กางออกแล้วเดินตาม
ลองนึกภาพการขับรถจากจุด A ไปจุด B พิมพ์เขียวคือแผนที่ที่กำหนดเส้นทางทุกตารางนิ้วล่วงหน้า รถวิ่งตามแบบไม่มีทางเลือก ส่วนพวงมาลัยคือสิ่งที่คุณบังคับทุกวินาที ค่อยๆ หมุนทิศไปเรื่อยๆ จนถึงปลายทาง
prompt ของ Midjourney/DALL-E ทำงานแบบหลัง ทุกขั้นของการลบ noise prompt จะถูก "อ่าน" อีกครั้ง แล้วบอก network ว่า "ขั้นนี้ ลบไปทางที่ตรงกับคำว่าแมวใส่หมวกพ่อมดมากกว่านะ"
paper "High-Resolution Image Synthesis with Latent Diffusion Models" ของทีม Rombach และคณะ ใน CVPR 2022 ใช้กลไกชื่อ cross-attention เพื่อทำเรื่องนี้ ทุกขั้นของ network จะ "เหลียวมอง" prompt อีกที เพื่อตัดสินใจว่าจะลบ noise ไปในทิศไหน
ผลที่จับต้องได้ ทำไมเปลี่ยน prompt 1 คำแล้วภาพเปลี่ยนทั้งใบ
ลองเปลี่ยน "แมวใส่หมวกพ่อมด" เป็น "แมวใส่หมวกชาวสวน" ภาพออกมาคนละโลกเลย ทั้งที่ noise ตั้งต้นอาจเหมือนกันด้วยซ้ำ เพราะพวงมาลัยถูกหมุนคนละทิศตั้งแต่ขั้นแรก หมวกที่กำลังก่อตัวขึ้นในขั้นกลางๆ ถ้าพวงมาลัยบอกว่าพ่อมด รายละเอียดที่งอกขึ้นจะเป็นทรงแหลมๆ มีดาว ถ้าพวงมาลัยบอกว่าชาวสวน รายละเอียดเดียวกันจะกลายเป็นปีกกว้าง สีฟาง
นี่คือเหตุผลที่ prompt ที่เปลี่ยนคำขยายนิดเดียว ภาพเปลี่ยนแบบยกเครื่อง เพราะคุณไม่ได้แก้พิมพ์เขียว คุณกำลังหมุนพวงมาลัยตั้งแต่กิโลเมตรแรก
หลักการที่ 5: ร่างก่อนลงสี ทำไม Stable Diffusion รันบน laptop ได้
ปริศนาสุดท้าย ภาพ 512×512 ต้องใช้ supercomputer สิ ทำไม Stable Diffusion รันบน GPU เครื่องเล่นเกมที่บ้านได้ภายใน 4-5 วินาที
คำตอบไม่ใช่เพราะ algorithm ฉลาดขึ้น แต่เพราะวิธีคิดเปลี่ยน
paper Latent Diffusion Models ของทีม Rombach อธิบายว่า AI ไม่ได้ทำงานบน pixel จริงๆ มันบีบรูป 512×512 ลงเหลือ "ขนาดเท่ากับร่างคร่าวๆ" ก่อน คือ 64×64 ทำงานบนร่างนั้น แล้วค่อย "ลงสีลงรายละเอียด" กลับเป็น 512×512 ตอนสุดท้าย
ลองนึกถึงการทำงานของศิลปิน
ขั้นแรก ศิลปินไม่ได้ลงหมึกหรือสีเลยทันที วาดร่างดินสอแบบหลวมๆ ก่อน 1 ใบ จัดองค์ประกอบ ตำแหน่ง สัดส่วน ให้ลงตัว
ขั้นที่ 2 พอร่างหลวมลงตัวแล้ว ค่อยกลับไปลงเส้นชัด ลงสี ลงเงาทับลายร่าง
Stable Diffusion ทำเหมือนกันเป๊ะ autoencoder (ตัวที่บีบรูปลงและขยายกลับ) บีบภาพต้นฉบับ 512×512 จุด ลงเหลือร่างขนาด 64×64 ซึ่งเล็กลง 64 เท่า (พื้นที่ 512×512 = 262,144 จุด ส่วน 64×64 = 4,096 จุด) ขั้นตอน "ลบ noise 50 ครั้ง" ทำงานบนร่างเล็กนี้ แล้ว autoencoder ก็ขยายร่างขั้นสุดท้ายกลับเป็น 512×512 อีกที
paper อธิบายว่ามันแยกเป็น 2 ช่วง ช่วงแรกคือ "บีบรูปทิ้งรายละเอียดเล็กๆ" เก็บแต่ความหมายของภาพ ช่วงที่สอง diffusion model ทำงานแค่กับความหมายบนร่างที่บีบแล้ว ไม่ต้องเสียพลังไปทำ pixel ละเอียดๆ ทุกจุดด้วย
ผลลัพธ์ที่ทำให้ Stable Diffusion เป็นจุดเปลี่ยน รันได้บน GPU เครื่องเล่นเกมใน 4-5 วินาที ไม่ใช่เพราะ algorithm เก่งขึ้น แต่เพราะย้ายไปทำงานบนพื้นที่ที่เล็กกว่าเดิม 64 เท่า
การฝึก model แบบเดิมที่ทำงานบน pixel ตรงๆ ใช้เวลาเป็นพันวันบน GPU ระดับศูนย์ข้อมูลขององค์กร ส่วน latent diffusion ลดต้นทุนลงมหาศาล เปิดประตูให้ทุกคนใช้ได้ที่บ้าน
มีอีก paper หนึ่งของทีม Song, Meng, Ermon ใน ICLR 2021 ที่ลดจำนวนขั้นตอนจาก 1,000 เหลือ 50 ขั้นได้ เร็วขึ้นอีก 10-50 เท่า ทำให้ทุกอย่างมารวมกันที่ความเร็วระดับวินาที
ส่งท้าย: 5 หลักการที่ใช้ได้ตลอดไป
สรุป 5 หลักการเป็นชุดเดียวที่อ่านจบแล้วจำได้
หนึ่ง ลบความมั่วทีละขั้นง่ายกว่าวาดทีเดียว AI เริ่มจากผ้าใบ noise ล้วน แล้วขัดออก 50 รอบ
สอง ฝึกฟรีจากการเติม noise เอง รูปบนเว็บทุกใบกลายเป็นแบบฝึกหัดได้หลายร้อยครั้ง ไม่ต้องมีคนมาช่วยติดป้ายว่ารูปนี้สวยหรือพังแล้ว
สาม ทุกขั้นตอบคำถามเดียว noise น่าเอาออกตรงไหน ไม่พยายามทำหลายอย่างพร้อมกัน
สี่ prompt = พวงมาลัย ค่อยๆ บังคับทิศทุกขั้น ไม่ใช่พิมพ์เขียวที่ AI อ่านแล้ววาดตาม
ห้า ร่างก่อนลงสี AI ทำงานบนร่างขนาดเล็กก่อน ค่อยลงรายละเอียดตอนสุดท้าย รันบน laptop ได้
ครั้งหน้าที่คุณเปิด Midjourney แล้ว loading bar ขึ้น คุณจะนึกออกว่าเบื้องหลังจอนั้น มีผ้าใบจุดมั่วๆ ที่ค่อยๆ ถูกขัดออกตามที่ประโยคของคุณชี้ทาง ไม่มีคลังภาพยักษ์ ไม่มีการวาดจากศูนย์ มีแค่ประติมากรที่ขัดหินอ่อนตามพวงมาลัยที่คุณส่งให้
แค่นี้ก็เปลี่ยนวิธีที่คุณมองเครื่องมือพวกนี้ได้แล้ว
แหล่งอ้างอิง
- Denoising Diffusion Probabilistic Models โดย Ho, Jain, Abbeel (NeurIPS 2020)
- High-Resolution Image Synthesis with Latent Diffusion Models โดย Rombach และคณะ (CVPR 2022)
- Denoising Diffusion Implicit Models โดย Song, Meng, Ermon (ICLR 2021)
- Classifier-Free Diffusion Guidance โดย Ho, Salimans (NeurIPS 2021 Workshop)



