AI ไม่ได้โกหก แค่ถูกฝึกให้เดา first principles ของ hallucination
AI ไม่ได้โกหก มันแค่ถูกฝึกในระบบที่ให้รางวัลการเดามากกว่ายอมรับว่าไม่รู้ เข้าใจ first principle ของ hallucination แล้วคุณจะรู้ว่าควรเชื่อคำตอบของ AI ตอนไหน

AI ไม่ได้โกหก มันแค่ถูกฝึกมาในระบบที่การเดาให้คะแนนดีกว่ายอมรับว่าไม่รู้ ลองนึกภาพห้องสอบที่ทุกคนคุ้น มีนักเรียนคนหนึ่งเปิดข้อสอบมาเจอข้อที่ตัวเองไม่รู้คำตอบ แต่กระดาษคำตอบบอกชัดว่าตอบผิดได้ 0 คะแนน เว้นว่างก็ได้ 0 คะแนนเหมือนกัน เด็กคนนั้นจะเดาหรือไม่เดา คำตอบชัดอยู่แล้ว ในบทความนี้จะแกะกลไกการเดาแบบนี้ออกมาเป็น 3 ชั้นที่ทำงานพร้อมกัน แล้วเปลี่ยนมันให้เป็นสัญญาณที่คุณดูออกได้ว่าควรเชื่อคำตอบของ AI ตอนไหน
1. ภาพข้อสอบ multiple choice ที่เปลี่ยนพฤติกรรมนักเรียน
นึกภาพข้อสอบ 4 ตัวเลือก กฎคือตอบถูกได้ 1 คะแนน ตอบผิดได้ 0 คะแนน เว้นว่างก็ได้ 0 คะแนน ถ้าคุณเป็นนักเรียนแล้วเจอข้อที่ไม่รู้ ทางที่คุ้มที่สุดคือเดา เพราะค่าเฉลี่ยของการเดาแบบมั่วๆ คือ 0.25 คะแนน (มีโอกาสถูก 1 ใน 4) ส่วนการเว้นว่างคือ 0 คะแนนแน่ๆ การเดาจึงดีกว่าเสมอ
ทีนี้ลองเปลี่ยนกฎ ข้อสอบบางชุดในอดีตอย่าง GRE เก่าหรือ SAT เก่าหักคะแนนตอบผิดประมาณ 0.25 คะแนน นักเรียนจะเรียนรู้พฤติกรรมใหม่ทันที ตอบเฉพาะข้อที่มั่นใจ ข้อที่ไม่รู้เลยให้เว้น เพราะการเดามั่วมีค่าเฉลี่ยติดลบ ระบบให้คะแนนเปลี่ยน พฤติกรรมเปลี่ยนตาม
หลักการตรงนี้สำคัญมาก ระบบให้คะแนนเป็นตัวกำหนดพฤติกรรม ไม่ใช่ความตั้งใจของนักเรียน เด็กที่เดาในข้อสอบไม่หักคะแนนไม่ได้ขี้โกง เด็กที่เว้นว่างในข้อสอบหักคะแนนไม่ได้ขี้กลัว ทั้งสองกลุ่มแค่เลือกกลยุทธ์ที่ทำคะแนนได้ดีที่สุดในระบบที่เจอ
จำภาพนี้ไว้ให้แน่นก่อน เพราะอีกไม่กี่ย่อหน้าข้างหน้าเราจะเห็นว่า AI ที่คุณคุยด้วยทุกวันก็คือนักเรียนคนนั้น
2. AI ก็คือนักเรียนคนนั้น กลไก scoring ที่ฝึก model ให้เดา
ทีมวิจัยที่ทำงานกับ OpenAI นำโดย Adam Tauman Kalai ตีพิมพ์ paper ชื่อ Why Language Models Hallucinate ในปี 2025 คำตอบของพวกเขาตรงกับ analogy ข้อสอบที่เพิ่งเล่าไป ต้นตอของ hallucination ไม่ได้อยู่ที่ model "อยากหลอก" แต่อยู่ที่ระบบให้คะแนนที่ฝึกมันมา
เวลานักวิจัยวัดว่า AI เก่งแค่ไหน เขาใช้สิ่งที่เรียกว่า benchmark คือชุดข้อสอบมาตรฐานที่ใช้เทียบ model หลายตัว Kalai กับทีมไปวิเคราะห์ benchmark หลัก 9 ตัวที่วงการใช้กันบ่อย เช่น GPQA, MMLU-Pro, MATH, SWE-bench สิ่งที่พบคือเกือบทั้งหมดให้คะแนนแบบเดียวกัน ตอบถูกได้ 1 ตอบผิดได้ 0 ตอบไม่รู้ก็ได้ 0 เหมือนกัน
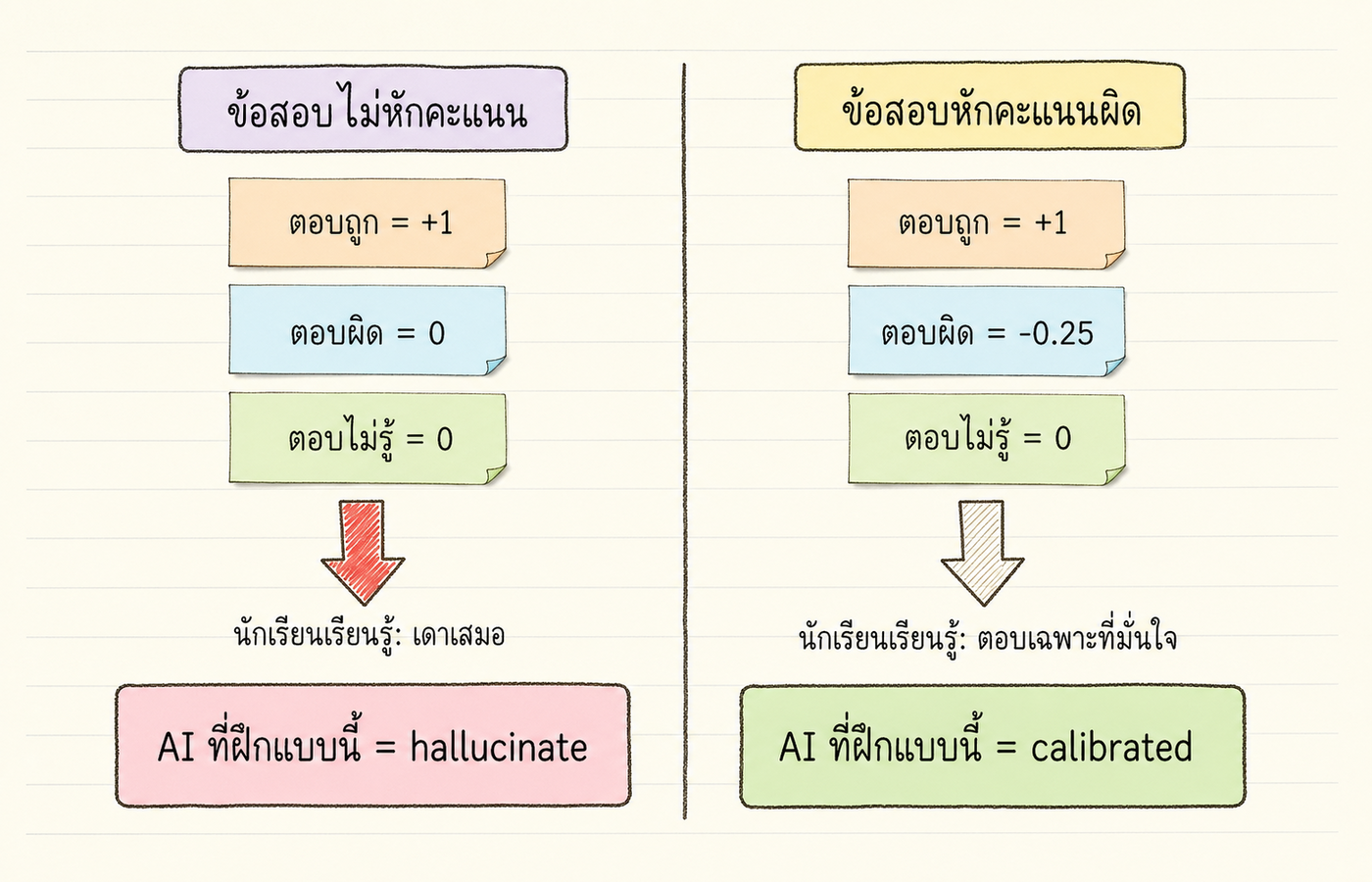
ผลที่ตามมาก็เหมือนกับเด็กในห้องสอบ model ที่ฝึกตามสัญญาณนี้เรียนรู้ว่าการเดาแบบมั่นใจเสมอคือกลยุทธ์ที่ทำคะแนนได้ดีที่สุด ส่วนการยอมรับว่า "ฉันไม่รู้" ไม่ได้คะแนนเพิ่ม แต่เสียโอกาสได้คะแนนจากการเดาถูกบางครั้ง paper เขียนตรงๆ ว่านักเรียนเดาในข้อสอบ multiple choice เพื่อทำคะแนน ฉันใด AI ก็เดาในการประเมินด้วย benchmark ฉันนั้น เพราะการเดาในระบบที่ไม่หักคะแนนคือกลยุทธ์ที่ทำคะแนนได้ดีที่สุด (Kalai et al. 2025)
ประเด็นสำคัญคือปัญหาไม่ได้อยู่ที่ model เป็นคนไม่ดี ไม่ได้อยู่ที่บริษัทตั้งใจสร้างให้มันโกหก แต่อยู่ที่ระบบให้คะแนนทั้งวงการที่ส่งสัญญาณตรงกันมาตลอดว่าเดาดีกว่ายอมรับว่าไม่รู้ ตราบใดที่ตารางจัดอันดับยังจัดด้วยกฎเดิม model รุ่นถัดไปก็จะเรียนรู้พฤติกรรมเดิม นี่คือชั้นแรกของกลไก hallucination
3. ทำไม model จำบางเรื่องไม่ได้ ต่อให้เทรนข้อมูลเยอะแค่ไหน
ระบบให้คะแนนที่ฝึกผิดเป็นแค่ชั้นแรก ชั้นที่สองอยู่ลึกลงไปอีก ลึกตั้งแต่ขั้นตอนที่ model เห็นข้อมูลครั้งแรกที่เรียกว่า pretraining คือการอ่านข้อความจำนวนมหาศาลจากเว็บเพื่อเรียนรู้ภาษาและความรู้ก่อนนำไปปรับใช้งานจริง
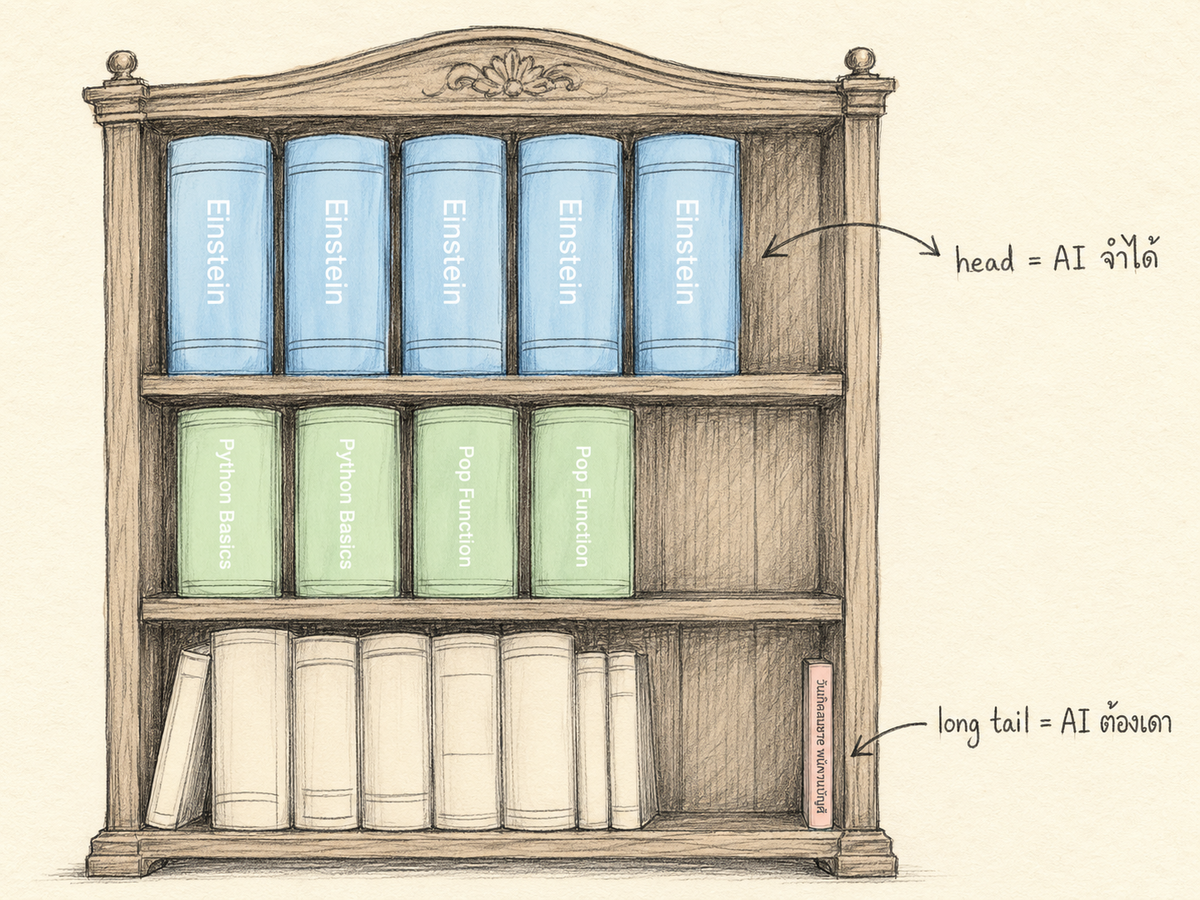
ลองนึกภาพห้องสมุดยักษ์ที่เก็บแทบทุกข้อความบนเว็บไว้หมด เรื่องของ Einstein มีคนเขียนถึงเป็นพันๆ ครั้ง ทั้งบทความ Wikipedia หนังสือเรียน ข้อสอบ บล็อก คำพูดในเว็บบอร์ด ใครก็ตามที่อ่านห้องสมุดทั้งห้องก็จะจำเรื่อง Einstein ได้แม่น ส่วนวันเกิดของพนักงานบัญชีสมชายอาจมีปรากฏแค่ใน LinkedIn ของเขาที่เผลอตั้งเป็นสาธารณะอยู่ที่เดียวในห้องสมุดทั้งห้อง คนที่เห็นข้อมูลแค่ครั้งเดียวจำได้แค่หน้าตาคร่าวๆ ตัวเลขเป๊ะๆ ต้องเดาจากบริบทรอบข้าง
ทีมของ Kalai เรียกข้อเท็จจริงประเภทหลังว่า singleton fact คือข้อเท็จจริงที่ปรากฏแค่ครั้งเดียวในข้อมูลที่ใช้ฝึก model สิ่งที่ paper พิสูจน์ไว้ตรงๆ คือ hallucination rate ของ model หลัง pretraining จะลดต่ำกว่าสัดส่วนของ singleton fact ในข้อมูลฝึกไม่ได้ (Kalai et al. 2025 Theorem 2)
แปลให้เห็นภาพ สมมติในข้อมูลฝึกของ model มีวันเกิดของคน 100 คน ถ้า 20 คนในนี้ถูกพูดถึงแค่ครั้งเดียวในข้อมูลทั้งหมด ไม่ว่าจะถาม model กี่รอบ มันจะตอบวันเกิดผิดอย่างน้อย 20 ครั้งจาก 100 ครั้งที่ถูกถามเรื่องวันเกิด ตัวเลข 20 นี้ไม่ใช่ปัญหาที่จะหายเมื่อฝึกข้อมูลเพิ่ม เพราะตราบใดที่ยังมีคนกลุ่ม "ถูกพูดถึงครั้งเดียว" อยู่ในข้อมูล ตัวเลขนั้นจะอยู่ตามมาตลอด
ตัวอย่างที่ paper ทดสอบจริงคือให้ DeepSeek-V3 ตอบวันเกิดของ Kalai เอง ลอง 3 ครั้งได้ 3 คำตอบ "03-07" "15-06" "01-01" ผิดหมด ไม่ใช่เพราะ DeepSeek-V3 ห่วย เปลี่ยนเป็น model ตัวอื่นถามคำถามเดียวกันก็ตอบผิดเหมือนกัน เพราะ Kalai ในเชิงข้อมูลคือ singleton ไม่มีเว็บไหนพูดถึงวันเกิดเขาซ้ำมากพอจะให้ model จดจำได้
พอเข้าใจกลไกแล้วก็จะเห็นภาพชัด ถามเรื่องที่ "ปรากฏซ้ำเยอะในเว็บ" อย่าง Einstein ภาษา Python หรือฟังก์ชันมาตรฐาน model จะตอบแม่น ถามเรื่องที่ "ปรากฏน้อย" อย่างชื่อพนักงานในบริษัทคุณ หรือ quirk เฉพาะของ tool ภายในที่ทีมคุณใช้กันเอง model จะเดาสูง ที่สำคัญกว่านั้นคือปัญหานี้ไม่หายแม้จะเพิ่มข้อมูลฝึกอีกหลายเท่า เพราะในโลกจริงมีคนใหม่ บริษัทใหม่ เหตุการณ์ใหม่เกิดขึ้นตลอดเวลา ของใหม่เหล่านี้ยังไม่มีใครพูดถึงซ้ำพอที่ model จะจดจำได้ มันก็จะตอบเรื่องของใหม่ๆ เหล่านี้ผิดอยู่ดี ไม่ว่าจะฝึกข้อมูลเพิ่มกี่รอบ
4. Hallucination 2 ตระกูล ที่ต้องแยกก่อนจะแก้
ก่อนจะไปถึงเรื่องสัญญาณที่ดูออก ต้องแยกประเภทของ hallucination ก่อน เพราะวิธีตรวจคนละแบบกันโดยสิ้นเชิง งานสำรวจการจัดประเภทของ hallucination โดย Huang และคณะในปี 2023 แบ่ง hallucination เป็น 2 ตระกูลใหญ่
ตระกูลแรกชื่อ factuality hallucination คือคำตอบของ AI ขัดกับข้อเท็จจริงในโลก เช่นบอกว่า Einstein เกิดปี 1888 (ของจริงคือ 1879) หรือบอกว่า paper ฉบับหนึ่งเขียนโดยใครสักคนที่ไม่ได้เขียนจริง ตรวจประเภทนี้ได้ด้วยการเทียบกับแหล่งภายนอก เปิด Wikipedia ค้น Google Scholar ดูเอกสารต้นฉบับ
ตระกูลที่สองชื่อ faithfulness hallucination คือคำตอบขัดกับสิ่งที่คุณเพิ่งให้ไป แบ่งย่อยเป็น 3 แบบ แบบแรกไม่ทำตามคำสั่ง ขอให้ตอบสั้น 3 บรรทัด มันตอบยาว 10 บรรทัด แบบที่สองขัดกับเอกสารที่แนบไป ส่งไฟล์รายงานประชุมไปให้สรุป มันเพิ่มประเด็นที่ไม่มีในเทป แบบที่สามขัดแย้งภายในคำตอบเดียวกัน ย่อหน้าแรกบอก A ย่อหน้าหลังบอกตรงข้ามกับ A
คนที่ใช้ AI ในงานออฟฟิศจะเจอ faithfulness hallucination บ่อยกว่า factuality เพราะส่วนใหญ่งานของคุณคือป้อนเอกสาร ป้อนบริบท แล้วขอให้ AI สรุป แปล หรือเรียบเรียง ปัญหาที่เจอจึงเป็น "AI ใส่อะไรเพิ่มที่ไม่มีในต้นฉบับ" ไม่ใช่ "AI ผิดเรื่องประวัติศาสตร์โลก" วิธีตรวจ faithfulness ต้องเทียบกับข้อมูลที่คุณให้ไปเอง ไม่ใช่กับโลกภายนอก ดังนั้นเทคนิคแก้ก็คนละชุดกับการแก้ factuality
5. สัญญาณที่ดูออกได้ว่า AI กำลังเดาหรือกำลังตอบจากของจริง
ทีนี้มาถึงส่วนที่เอาไปใช้ได้จริง งานวิจัยปี 2025 ของ Tao และคณะ ทดสอบ model 80 ตัวขนาดต่างๆ ตั้งแต่ตัวเล็กที่รันบนเครื่องตัวเองได้ ไปจนถึงตัวใหญ่ที่สุดในวงการ งานนี้เปรียบเทียบ 3 วิธีดูว่า model มั่นใจแค่ไหนกับคำตอบของตัวเอง
วิธีแรกคือถามตรงๆ ให้ model ตอบเป็นเปอร์เซ็นต์ความมั่นใจ เช่น "ฉันมั่นใจ 90%" วิธีที่สองคือดูสัญญาณภายในของ model ที่นักวิจัยเข้าถึงได้ระหว่างที่มันสร้างคำตอบทีละคำ วิธีที่สามคือดูภาษากำกวมที่ model ใช้ในประโยค เช่น "อาจจะ" "น่าจะ" "เท่าที่ฉันเข้าใจ" ผลออกมาชัดเจน วิธีที่สามเอาชนะอีก 2 วิธีในเกือบทุกการทดสอบ
แปลเป็นภาษาคนคือ ภาษากำกวมที่ AI ใช้เองตามธรรมชาติเชื่อถือได้กว่าตัวเลขเปอร์เซ็นต์ที่มันพ่นออกมา ฟังดูสวนสามัญสำนึก แต่พอคิดดูก็สมเหตุสมผล เพราะตัวเลขเปอร์เซ็นต์ก็คือคำตอบอีกแบบที่ model สร้างขึ้น มันเดาเปอร์เซ็นต์ได้เหมือนเดาคำตอบนั่นแหละ ส่วนคำกำกวมที่แทรกในประโยคเป็นพฤติกรรมที่ลึกกว่า เพราะมันสะท้อนว่าตัว model เองรู้ตัวอยู่ว่าส่วนไหนแน่ใจ ส่วนไหนไม่แน่ใจ
จากตรงนี้แปลงเป็นสัญญาณที่ตาคุณดูออกได้จริง
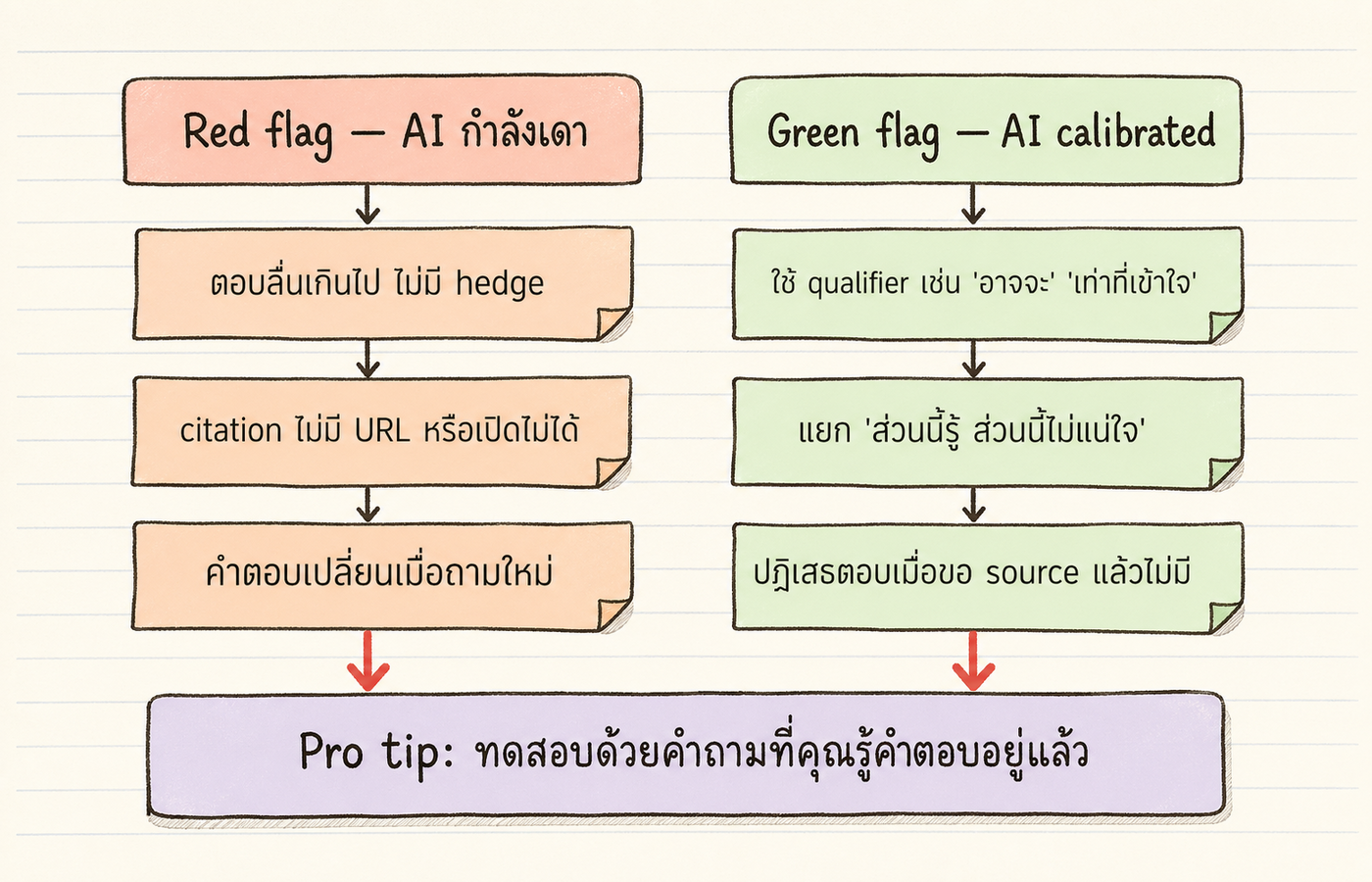
red flag 3 ข้อที่บอกว่า AI กำลังเดา 1. คำตอบลื่นเกินไป มั่นใจเกินไปในเรื่องเฉพาะอย่างชื่อคน วันที่ ตัวเลข แหล่งอ้างอิง ของจริงควรมีคำกำกวมแทรกบ้าง 2. แหล่งอ้างอิงไม่มีลิงก์ หรือมีลิงก์แต่เปิดไม่ได้ ส่วนใหญ่กรณีนี้คือ AI แต่งขึ้น 3. คำตอบเปลี่ยนเมื่อถามใหม่ในห้องสนทนาใหม่ ของจริงควรตอบเหมือนเดิมทุกครั้ง ถ้าสไลด์ไปมาแสดงว่ามาจากการเดา
green flag 3 ข้อที่บอกว่า AI ตอบจากของจริง 1. ใช้คำกำกวมตามธรรมชาติ เช่น "เท่าที่ฉันเข้าใจ" "อาจจะ" "ตามข้อมูลของฉันถึง..." 2. แยกในคำตอบเดียวกันว่าส่วนนี้รู้ ส่วนนี้ไม่แน่ใจ 3. ปฏิเสธตอบเมื่อขอ source แล้วมันไม่มี source จริง
วิธีลองใช้ทันที ถามคำถามที่คุณรู้คำตอบอยู่แล้วในเรื่องที่คุณถนัด 5 คำถาม นับว่ามันยอมรับว่าไม่รู้กี่ครั้ง เดามั่นใจกี่ครั้ง ตอบถูกกี่ครั้ง พอใช้งานจริงในเรื่องเดียวกันคุณจะเริ่มอ่านสัญญาณของ tool นั้นออก
ประเด็นที่ต้องจำคือ น้ำเสียงมั่นใจของ model ไม่ใช่ตัวบ่งชี้ความจริง บางครั้งมันมั่นใจเพราะรู้จริง บางครั้งมันมั่นใจเพราะเดาสวย แยกออกจากกันด้วยน้ำเสียงอย่างเดียวไม่ได้ ต้องดูคำกำกวมและลักษณะการตอบอื่นประกอบ
6. ทำไม "model ใหม่ใหญ่กว่า" ไม่ใช่คำตอบ และอะไรคือคำตอบจริง
ความเข้าใจผิดที่พบบ่อยคือ พอ model รุ่นถัดไปออก hallucination จะหายไปเอง รอไปเรื่อยๆ ก็ดีขึ้นเอง ความเข้าใจนี้พลาดประเด็นใหญ่ของ Kalai ตราบใดที่ระบบให้คะแนนยังเดิม คือยังให้คะแนนแบบถูก/ผิด 0 หรือ 1 ผ่าน benchmark ที่ไม่ให้คะแนนกับการยอมรับว่าไม่รู้ model รุ่นไหนก็ฝึกไปทางเดิม hallucination จะลดเฉพาะเรื่องที่ปรากฏซ้ำเยอะในเว็บ ส่วนเรื่องที่ปรากฏน้อยจะอยู่ตลอด
ทางออกจริงตามที่ paper เสนอไม่ใช่เปลี่ยนโครงสร้างของ model แต่คือเปลี่ยนระบบให้คะแนน ตัวอย่างที่ paper เสนอคือเขียน instruction ใน prompt ระบุชัดแบบนี้ "ตอบเฉพาะเมื่อมั่นใจมากกว่า 75% ตอบผิดหัก 2 คะแนน ตอบไม่รู้ได้ 0 คะแนน ตอบถูกได้ 1 คะแนน" พอระบบให้คะแนนแบบนี้ model จะเรียนรู้ที่จะยกธงขาวยอมไม่ตอบเมื่อไม่มั่นใจ เพราะการเดาผิดมีต้นทุนจริง
ทางออกที่ user ทำเองได้โดยไม่ต้องรอวงการเปลี่ยน benchmark มี 2 ทาง
ทางแรกคือ RAG (Retrieval-Augmented Generation) เทคนิคที่ให้ model ค้นข้อมูลจากแหล่งภายนอกก่อนตอบ เช่นเอกสารของบริษัท หรือผลค้นจาก Google ไม่ใช่ตอบจากความจำของตัวเองล้วนๆ วิธีนี้ลด factuality hallucination ได้เยอะ เพราะคำตอบยึดกับเอกสารที่ดึงมาจริง ทางที่สองคือใช้ AI ในเรื่องที่มีตัวตรวจคำตอบอัตโนมัติภายนอก เช่นโจทย์คณิตที่พิสูจน์ได้ หรือ code ที่รันแล้วเห็นผลทันที ตัวตรวจจะจับ hallucination ได้ตรงๆ
ข้อระวังที่สำคัญคือไม่มีวิธีไหนที่แก้ทุกอย่างได้ฟรี RAG ลด factuality hallucination ได้ดี แต่กลับเปิดช่องให้ faithfulness hallucination เกิดขึ้นใหม่ เพราะ model อาจตอบไม่ตรงกับเอกสารที่ดึงมาก็ได้ (Huang et al. 2023) วิธีแก้แต่ละแบบมาพร้อมข้อแลกของตัวเอง ไม่มีปุ่มเดียวที่กดแล้ว AI ตอบถูกทุกครั้ง

7. สรุป เปลี่ยนคำถามจาก "AI โกหกหรือเปล่า" เป็น "AI กำลังเดาหรือเปล่า"
กลับมาที่ใจความหลักของบทความทั้งหมด hallucination ไม่ใช่ความตั้งใจหลอกของ model ไม่ใช่ bug ลึกลับ ไม่ใช่ความผิดของบริษัทที่สร้าง มันคือแรงกดดันทางสถิติที่เกิดจากระบบให้คะแนนที่ฝึกมันมา 3 ชั้นที่เพิ่งเล่าไปคือกลไกเดียวกันมองจาก 3 มุม ชั้นแรก hallucination คือผลของการแยกข้อมูลจริงกับข้อมูลที่ฟังดูเหมือนจริงไม่ออก ชั้นที่สอง ของหายากในข้อมูลฝึก (เรื่องที่ปรากฏแค่ครั้งเดียว) model จะจดจำไม่ได้เสมอ ฝึกข้อมูลเพิ่มก็แก้ไม่หมด ชั้นที่สาม benchmark ที่ให้คะแนนแบบ ถูก/ผิด สอน model ให้เดาแทนยอมรับว่าไม่รู้
การเปลี่ยนมุมมองที่อยากให้ผู้อ่านเอาไปใช้คือ เลิกถามคำถามแบบใช่/ไม่ใช่ อย่าง "เชื่อ AI ได้ไหม" เพราะคำตอบเป็น "ได้บ้างไม่ได้บ้าง" ตลอดเวลาและไม่ช่วยให้คุณตัดสินใจ เริ่มถามคำถามที่ละเอียดกว่า 3 ข้อแทน
หนึ่ง คำตอบนี้เป็นเรื่องที่คนพูดซ้ำเยอะในเว็บ หรือเรื่องเฉพาะทางที่มีปรากฏน้อย ถ้าเป็นเรื่องเยอะ model น่าจะแม่น ถ้าเป็นเรื่องน้อย ระวัง
สอง model มีคำกำกวมในประโยคไหม "อาจจะ" "เท่าที่เข้าใจ" บ้างไหม หรือตอบลื่นมั่นใจไปหมด
สาม คุณมีวิธีตรวจคำตอบนี้ไหม ถ้ามีเอกสาร source หรือมีตัวตรวจอัตโนมัติก็ใช้ ถ้าไม่มีเลยต้องเพิ่มความระวังอีกระดับ
ลองทำดูง่ายๆ หลังอ่านจบ เลือก AI tool ที่คุณใช้บ่อยที่สุด ถามคำถามที่คุณรู้คำตอบในเรื่องที่คุณถนัด 5 คำถาม นับว่ามันยอมรับว่าไม่รู้กี่ครั้ง เดามั่นใจกี่ครั้ง ตอบถูกกี่ครั้ง ในไม่กี่นาทีคุณจะเริ่มเห็นคะแนนความน่าเชื่อถือของ tool นั้นกับเรื่องที่คุณใช้
หลักการสุดท้ายที่อยากทิ้งไว้คือ AI ที่ดีไม่ใช่ AI ที่ตอบทุกคำถามได้ แต่คือ AI ที่รู้ตัวว่าเมื่อไรไม่รู้ และเราในฐานะคนใช้ก็ต้องเรียนรู้ที่จะให้คุณค่ากับการ "ไม่รู้" เท่ากับ "ตอบถูก" ตราบใดที่ทั้งวงการยังให้รางวัลการเดามากกว่ายอมรับว่าไม่รู้ hallucination ก็จะยังอยู่ แต่คุณในฐานะคนใช้ AI เปลี่ยนระบบให้คะแนนของตัวเองก่อนได้ เริ่มสังเกตคำกำกวม เริ่มเช็คแหล่งอ้างอิง เริ่มถามซ้ำ การเปลี่ยนคำถามจาก "AI โกหกหรือเปล่า" เป็น "AI กำลังเดาหรือเปล่า" จะอยู่กับคุณไปอีกหลายปี ไม่ว่า model จะเปลี่ยนชื่อเป็นอะไร tool จะเปลี่ยนเจ้าของกี่รอบก็ตาม
แหล่งอ้างอิง
- OpenAI (2025). Why language models hallucinate (companion blog post)



