ทำไม AI นับตัว r ใน strawberry ไม่ถูก เข้าใจกลไกพื้นฐานของ tokenization
AI ตอบเรื่องยากๆ ได้คล่อง แต่นับตัว r ใน strawberry กลับพลาด เพราะมันไม่ได้เห็นข้อความเป็นตัวอักษร แต่เห็นเป็นก้อนที่ประกอบมาเสร็จแล้วก่อนถึงมือ
AI ไม่ได้อ่านตัวอักษรทีละตัว มันอ่านเป็นก้อนที่ประกอบมาเสร็จแล้ว ลองพิมพ์ถาม AI ว่า "strawberry มีตัว r กี่ตัว" คำตอบที่ได้บ่อยที่สุดคือ 2 ทั้งที่จริงเป็น 3 และไม่ใช่ AI ตัวใดตัวหนึ่งเผลอพลาด แต่เกือบทุกตัวพลาดเหมือนกัน ถ้า AI ตอบเรื่องชีวเคมี ปรัชญา กฎหมาย ได้คล่อง แล้วทำไมเรื่องเด็กอนุบาลแบบนี้กลับพังขนาดนี้
สามตัว r ที่ AI หาไม่เจอ
ลองทำตามจริงดูสักครั้ง เปิดแชท AI ที่ใช้อยู่ทุกวันแล้วถามว่า "ในคำว่า strawberry มีตัว r กี่ตัว" คำตอบที่ได้มักเป็น 2 บางทีเป็น 1 ที่ถูกคือ 3 ตัว (s-t-r-a-w-b-e-r-r-y)
เรื่องน่าสนใจคือมันไม่ใช่ปัญหาของ AI ตัวเดียว ไม่ว่าจะถาม Claude ถาม ChatGPT ถาม Gemini หรือ model อื่นในตระกูลเดียวกัน อาการนี้ก็โผล่เหมือนกัน paper ของทีม Fu และคณะ ในปี 2024 ทดสอบกับ model หลายตัวและพบว่ามีรูปแบบความผิดที่เกิดซ้ำในทุกตัวที่ทดสอบ (Fu et al. 2024) พูดอีกอย่างคือมันไม่ใช่อุบัติเหตุ แต่เป็นเงื่อนไขที่อยู่ในโครงสร้างของระบบ
ปัญหานี้ไม่ได้อยู่ที่ความฉลาดของ AI แต่อยู่ที่ขั้นตอนก่อนข้อความเข้าถึง model

AI เห็นข้อความเป็นก้อนคำ ไม่ใช่ตัวอักษร
ลองนึกภาพชุดของเล่น Lego ที่โรงงานประกอบสำเร็จมาแล้ว เปิดกล่องออกมาเจอเด็ก หมวก รถ แทนที่จะเป็นชิ้นเล็กๆ ให้เราต่อเอง ถ้าใครถามว่า "เด็กตัวนี้ใช้ชิ้น 2x2 กี่ชิ้น" เราตอบไม่ได้เพราะเราไม่เห็นชิ้นย่อย เราเห็นแค่ "เด็ก" ที่ประกอบมาเรียบร้อย
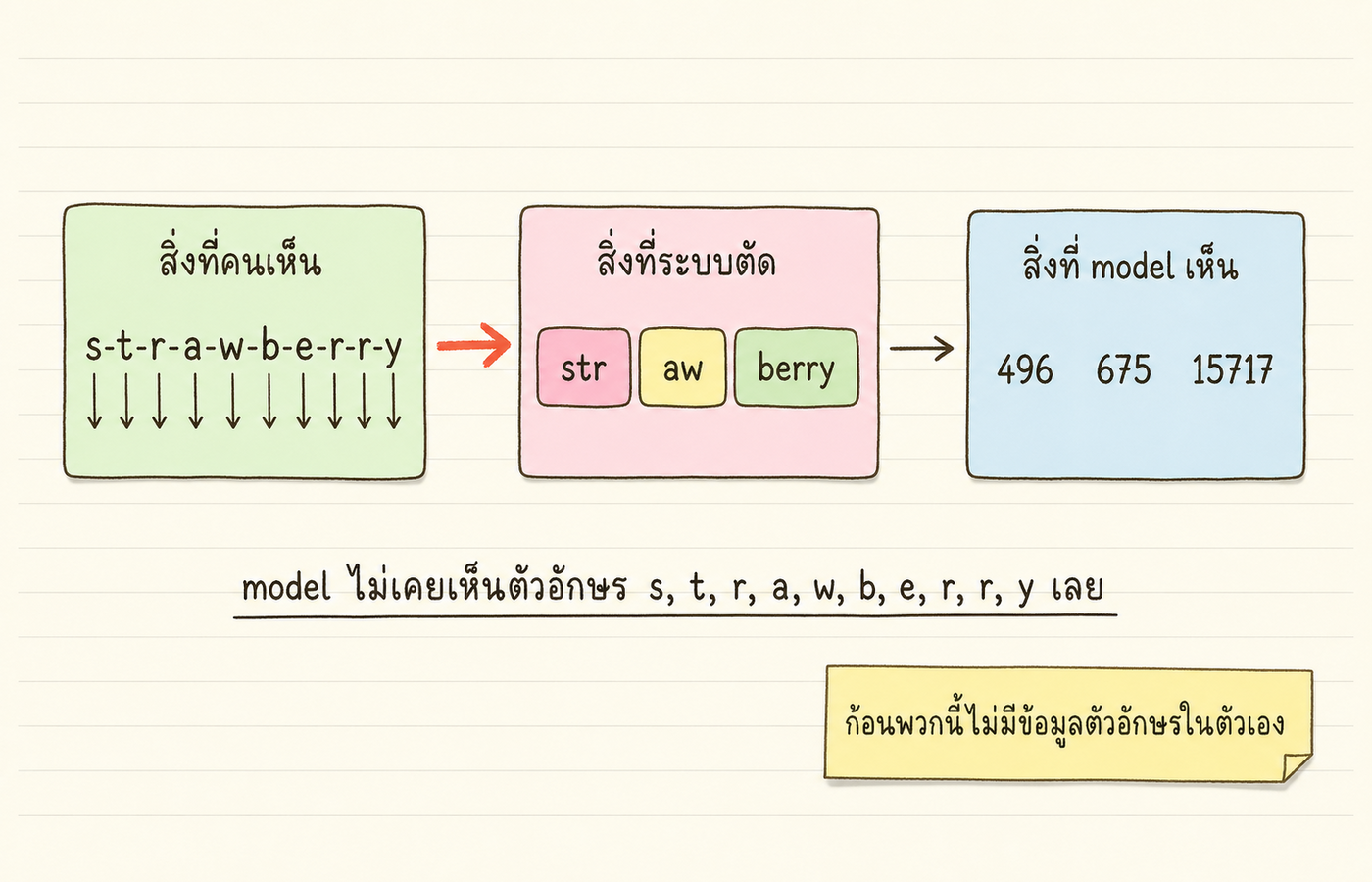
AI ก็ทำงานกับข้อความแบบนั้น ก่อนข้อความจะถึง model มันจะถูกตัดเป็นก้อน เรียกว่า token (token = ก้อนข้อความที่ระบบประกอบไว้ก่อนป้อนเข้า model อาจเป็นคำเต็ม คำเศษ หรือแม้แต่ครึ่งคำ) แล้วแต่ละก้อนก็ถูกแปลงเป็นเลขประจำตัว
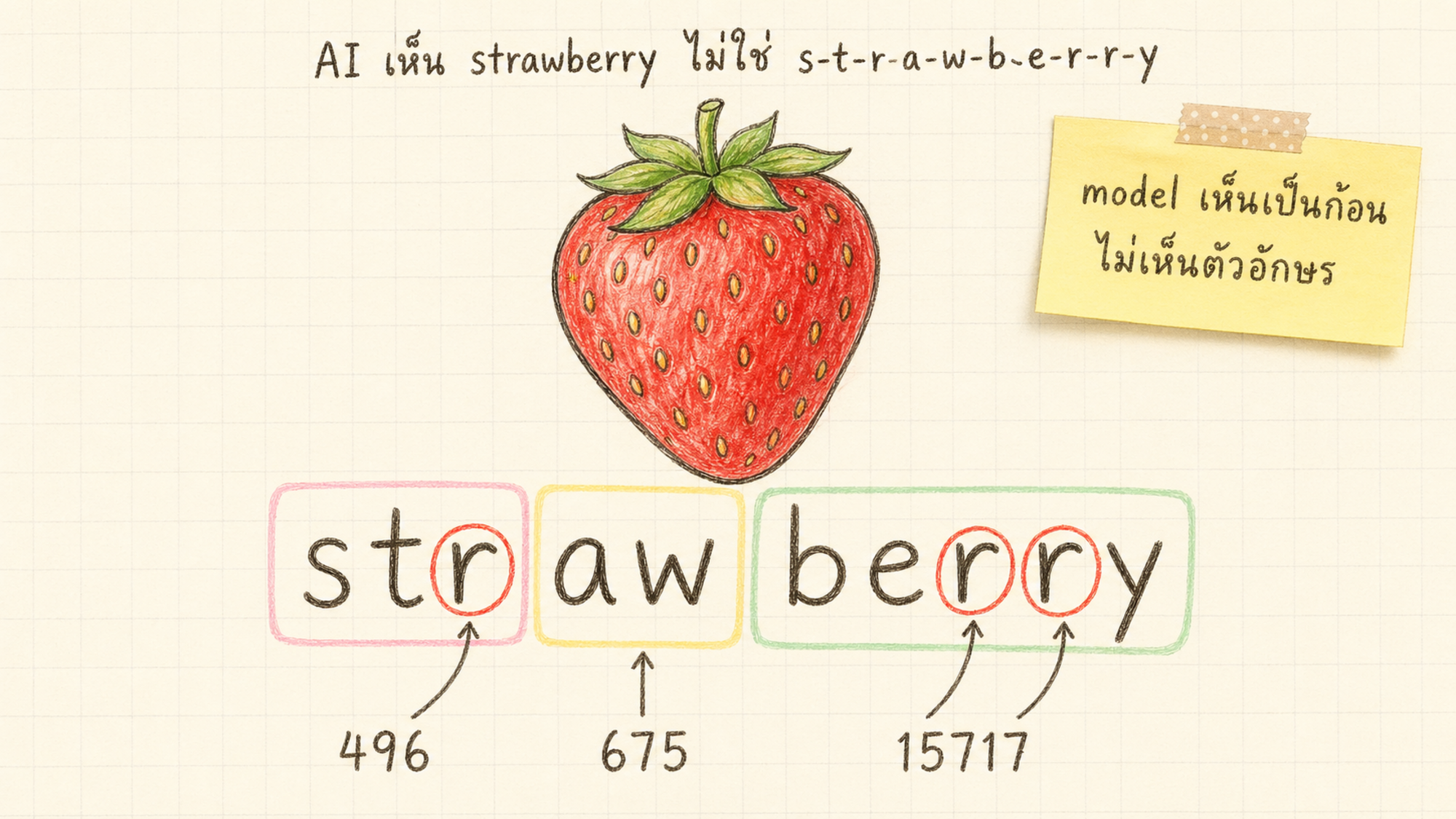
คำว่า "strawberry" ระบบของ GPT-4 แบ่งเป็น 3 ก้อน คือ str + aw + berry แล้วแปลงเป็นตัวเลข 496, 675, 15717 (อ้างอิงตาม Cosma et al. 2025) สิ่งที่ model มองเห็นจริงๆ คือ ลำดับเลข 3 ตัวนี้ ไม่ใช่ตัวอักษร s, t, r, a, w, b, e, r, r, y ที่เราเห็น
ทีนี้ลองคิดในมุม model อีกครั้ง ถามว่า "strawberry มีตัว r กี่ตัว" สำหรับ model มันเหมือนถูกถามว่า "ก้อน 496, 675, 15717 มีตัว r กี่ตัว" ก้อนพวกนี้ไม่มีข้อมูลตัวอักษรของตัวเองติดมา ตัวเลข 496 ไม่ได้บอกว่าตัวเองคือ str ที่มี r 1 ตัว model ต้องเดาทางอ้อมจากสิ่งที่เคยเรียนรู้ในตอนฝึก ซึ่งบ่อยครั้งมันก็เดาไม่ตรง
แล้วทำไมระบบถึงตัดข้อความเป็นก้อน
คำถามต่อมาคือ ทำไมต้องตัดเป็นก้อนตั้งแต่แรก ทำไมไม่ป้อนตัวอักษรเดี่ยวๆ ให้ model ไปเลย คำตอบคือ "ประหยัดและทำงานเร็วขึ้น"
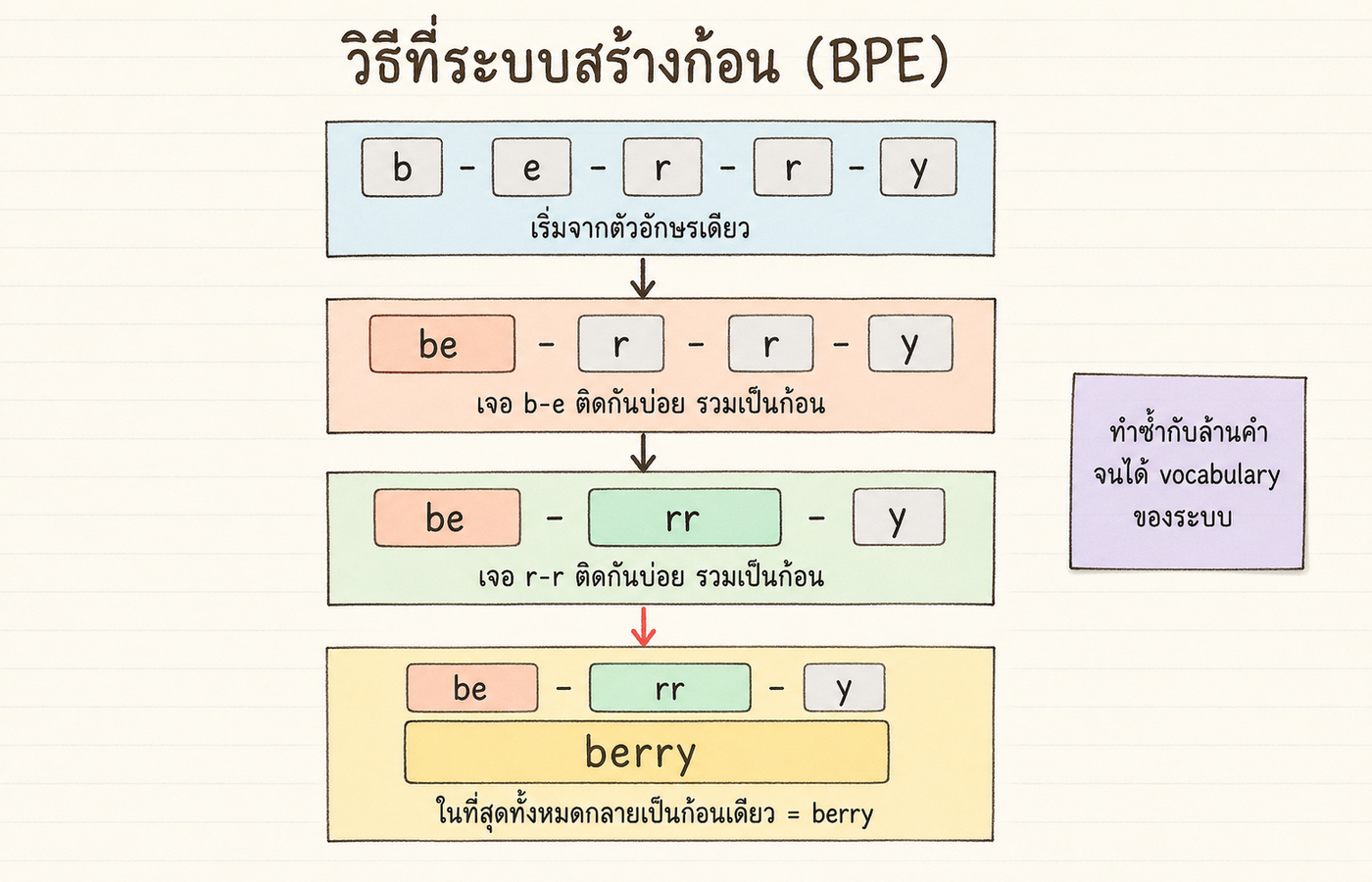
ระบบที่ใช้ตัดข้อความชื่อ BPE หรือ Byte Pair Encoding (วิธีตัดข้อความที่จับคู่ตัวอักษรที่เจอติดกันบ่อยให้กลายเป็นก้อนเดียว) วิธีคิดเรียบง่ายมาก ระบบจะวนดูข้อมูลฝึกขนาดมหาศาล แล้วถามว่า "ตัวอักษรคู่ไหนปรากฏติดกันบ่อยที่สุด" ถ้าเจอว่า b-e ปรากฏติดกันบ่อย ก็รวมเป็นก้อนเดียวชื่อ be ทำซ้ำกับคู่อื่น เช่น r-r บ่อย รวมเป็น rr ทำซ้ำไปอีกหลายล้านรอบจนได้คลังก้อนทั้งหมดของระบบ
เปรียบเหมือนซื้อชุดประกอบสำเร็จที่โรงงานเตรียมไว้ ถ้าโรงงานเห็นว่าคนซื้อ "berry" บ่อย ก็ทำชุดสำเร็จ "berry" ติดสต็อกไว้เลย แทนที่จะให้ลูกค้ามาประกอบจาก b+e+r+r+y ทุกครั้ง
ผลพลอยได้ที่สำคัญคือ คำที่เจอบ่อยในข้อมูลฝึกจะกลายเป็นก้อนใหญ่ก้อนเดียว ส่วนคำที่เจอน้อยจะถูกหั่นย่อยเป็นหลายก้อน นี่เป็นจุดที่จะอธิบายอาการอื่นๆ ในส่วนถัดไป
ทำไมพลาดแบบนี้เกือบทุกตัว
ถ้าปัญหาเกิดจากการตัดข้อความเป็นก้อน คำถามต่อไปคือ ทำไมความผิดถึงเกิดเป็นรูปแบบเดียวกันในทุก model
paper ของทีม Fu และคณะ ในปี 2024 (Fu et al. 2024) ทดสอบ model หลายตัวแล้วพบเงื่อนไขที่คาดเดาได้ 3 ข้อ
ข้อแรก คำยิ่งยาว ความผิดยิ่งสูง เพราะคำยาวมีก้อน token เยอะ ทำให้ model ต้องเดาความสัมพันธ์ระหว่างก้อนกับตัวอักษรหลายชั้น
ข้อสอง model "รู้ว่า" ตัวอักษรนั้นมีอยู่ในคำ แต่ "นับ" ไม่ถูก paper สรุปอาการนี้ตรงๆ ว่า model จำตัวอักษรได้ แต่นับไม่ได้
ข้อสาม ความผิดสูงสุดเกิดเมื่อต้องนับตัวอักษรที่ปรากฏมากกว่า 2 ครั้งในคำเดียวกัน
ทีนี้กลับมาดู strawberry มันเป็นคำยาว 10 ตัวอักษร และมี r ปรากฏ 3 ครั้งในคำเดียว เข้าเงื่อนไขที่ยากที่สุดทุกข้อพอดี เลยกลายเป็นปริศนาที่ทุกคนเล่าต่อ ไม่ใช่อุบัติเหตุ มันคือเงื่อนไขที่หินที่สุดของอาการที่อยู่ในโครงสร้าง
อาการเดียวกันโผล่ที่อื่นด้วย
ถ้าเข้าใจหลักการเรื่องก้อน token แล้ว จะเห็นว่าอาการอื่นที่ดูเหมือนเป็นคนละเรื่อง จริงๆ มาจากสาเหตุเดียวกัน
ภาษาไทยใช้ token แพงกว่าอังกฤษหลายเท่า ภาษาอังกฤษเป็นภาษาที่อยู่ในข้อมูลฝึกของ AI เยอะที่สุด ระบบ BPE จึงเตรียมก้อนสำเร็จไว้ให้ภาษาอังกฤษเยอะที่สุดด้วย โดยเฉลี่ยตัวอักษรอังกฤษ 4-5 ตัวเท่ากับ 1 ก้อน คำเช่น "hello" เป็นก้อนเดียวเลย ส่วนภาษาไทยอยู่ในข้อมูลฝึกน้อยกว่ามาก ระบบจึงหั่นคำว่า "สวัสดี" เป็นประมาณ 6 ก้อน (ตรวจสอบได้ผ่านเครื่องมือ tiktoken ของ OpenAI)
ผลตามมาที่จับต้องได้คือ ค่าเรียกใช้ AI ผ่าน API (ช่องทางที่โปรแกรมเรียกใช้ AI ซึ่งคิดเงินตามจำนวน token) สำหรับบทความภาษาไทยแพงกว่าภาษาอังกฤษหลายเท่า ทั้งที่ตัวอักษรอาจพอๆ กัน ไม่ใช่เพราะ AI ไม่ชอบไทย แต่เพราะระบบเห็นภาษาไทยเป็นก้อนย่อยเยอะกว่า และ AI "งง" ภาษาไทยมากกว่าอังกฤษเล็กน้อยด้วยเหตุผลเดียวกัน เพราะหน่วยที่มันเห็นไม่ตรงกับคำที่มนุษย์ไทยเห็น
AI บวกเลขยาวๆ พลาด อาการนี้ก็มาจากกลไกเดียวกัน ตัวเลข "1234" อาจถูกตัดเป็น "1" + "234" หรือเป็น "1234" ทั้งก้อน ขึ้นกับ tokenizer ของแต่ละ model paper ของ Singh และ Strouse ในปี 2024 (Singh & Strouse 2024) เปรียบเทียบ model หลายตัวแล้วพบว่า model ที่ตัดเลขทีละหลัก (1 หลัก = 1 ก้อน) บวกเลขแม่นกว่า model ที่บางทีรวมหลายหลักเป็นก้อนเดียว เพราะหน่วยที่ model เห็นไม่สม่ำเสมอ
สรุปคือ การนับตัวอักษร ภาษาไทยใช้ token แพง และการบวกเลขพลาด เป็นอาการที่ดูแยกกัน 3 อาการ แต่สาเหตุเดียวกัน นั่นคือ ก้อนที่ระบบเตรียมไว้ ไม่ตรงกับหน่วยที่งานนั้นต้องการ

วิธีแก้ที่ใช้ได้พรุ่งนี้
ข่าวดีคือ ถึงแม้เราจะแก้วิธีตัดข้อความของ AI ไม่ได้ แต่เราเปลี่ยนวิธีถามได้ และมันได้ผลจริง หลักการคือ บังคับให้ AI ออกจากระดับ "ก้อน" ลงไปที่ระดับ "ตัวเดี่ยว" ก่อนนับ
วิธีที่ 1 ขอให้แยกเป็นรายการก่อน แทนที่จะถาม "strawberry มีตัว r กี่ตัว" ให้ถามว่า "ช่วยเขียนตัวอักษรของ strawberry ทีละตัวเรียงเป็นรายการ แล้วนับว่ามี r กี่ตัว" คำสั่งนี้บังคับ AI ให้พิมพ์ตัวอักษรเดี่ยวออกมาก่อน พอมันเขียน s, t, r, a, w, b, e, r, r, y เรียงให้ดู การนับในขั้นต่อไปก็แม่นขึ้นเยอะ
วิธีที่ 2 ขอให้คิดทีละขั้น เพิ่มคำสั่งว่า "นับ r ใน strawberry ทีละตัวอักษร เช่น s ไม่ใช่ r, t ไม่ใช่ r, r ใช่ นับเป็น 1..." ให้ AI เดินทีละก้าวแทนการตอบรวดเดียว วิธีนี้ paper ของทีม Zhang และคณะ ในปี 2024 (Zhang et al. 2024) ยืนยันว่าช่วยลดความผิดในงานนับได้
วิธีที่ 3 ขอให้เขียน code นับให้ ถ้า AI ตัวที่ใช้รัน code ได้ บอกไปเลยว่า "เขียน Python นับตัว r ใน strawberry แล้วบอกผล" วิธีนี้ย้ายงานนับจาก AI ไปให้โปรแกรมที่เห็นตัวอักษรจริงๆ ทำ คำตอบที่ได้แม่นยำเสมอ
ทั้ง 3 วิธีใช้กับงานออฟฟิศได้ด้วย เช่น นับจำนวนคำในประโยค นับช่องในรายชื่อ Excel นับจำนวนข้อในรายงาน หลักการเดียวกันคือ ขอให้ AI เขียนทุกตัวออกมาก่อนแล้วค่อยนับ ไม่ใช่ขอตัวเลขรวดเดียว
รอ AI รุ่นใหญ่กว่านี้ก็ไม่ใช่คำตอบ
หลายคนพอเจอ AI พลาดเรื่องนับแบบนี้ จะคิดว่า "ก็รอ model รุ่นต่อไปสิ ใหญ่กว่านี้ก็คงเก่งกว่า" คำตอบจริงคือ ไม่แน่
paper ของทีม Cosma และคณะ ในปี 2025 (Cosma et al. 2025) วิเคราะห์ปรากฏการณ์นี้ตรงๆ และพบว่าความสามารถเข้าใจระดับตัวอักษร ทั้งการนับและการสะกดกลับด้าน ค่อยๆ ปรากฏช้าและไม่สมบูรณ์ ยิ่งระบบเตรียมก้อนไว้เยอะ ความสามารถนี้ยิ่งมาช้าเข้าไปอีก
เหตุผลที่ลึกกว่านั้นคือ ในข้อมูลที่ใช้ฝึก AI แทบไม่มีคนเขียนอธิบายว่า "strawberry สะกดด้วย s-t-r-a-w-b-e-r-r-y" บนเว็บ มนุษย์ใช้คำเป็นก้อนเหมือนกัน เราไม่ได้สะกดให้กันฟังตลอดเวลา AI จึงได้สัญญาณการฝึกเรื่องนี้น้อยมาก ขนาด model ใหญ่ขึ้นช่วยได้บ้าง แต่ไม่ได้แก้ที่รากของปัญหา
ข้อสรุปคือ ปัญหาเชิงโครงสร้างต้องการการแก้เชิงโครงสร้าง ไม่ใช่แค่ทำให้ model ใหญ่ขึ้น ถ้าวันนึง AI นับตัวอักษรได้ตรงทุกครั้ง มันจะมาจากการเปลี่ยนวิธีตัดข้อความ หรือเพิ่มกลไกให้ก้อนรู้จักตัวอักษรของตัวเอง ไม่ใช่แค่ใหญ่ขึ้นเฉยๆ
สรุป
หลักการเดียวที่อยากให้ติดตัวกลับไปคือ AI เห็นข้อความเป็นก้อน ไม่ใช่ตัวอักษร เพราะระบบประกอบก้อนตามที่เจอบ่อยในข้อมูลฝึก
จากหลักการนี้เกิดผลที่ใช้ได้ในชีวิตจริง 3 ข้อ
ข้อแรก ถ้างานต้องการหน่วยเล็กกว่าก้อนคำ เช่น นับตัวอักษร นับตัวเลขทีละหลัก ตรวจคำสะกด ให้บังคับ AI เขียนทุกตัวออกมาก่อนนับ ไม่ใช่ขอคำตอบสำเร็จรูป
ข้อสอง ภาษาไทยใช้ token เยอะกว่าอังกฤษหลายเท่า ไม่ใช่เพราะ AI ไม่ชอบภาษาไทย แต่เพราะข้อมูลฝึกภาษาอังกฤษเยอะกว่ามาก เลยมีก้อนสำเร็จไว้ให้ภาษาอังกฤษเยอะกว่า
ข้อสาม ความเก่งของ AI ในเรื่องที่ไม่คาดคิด เช่น สรุปกฎหมาย กับความพลาดในเรื่องที่ดูง่ายเช่นนับ r ไม่ได้ขัดแย้งกัน มาจากกลไกเดียวกันคือ มันทำงานในระดับ "ก้อน" ถ้าก้อนพอที่จะตอบ มันก็เก่ง ถ้างานต้องเล็กกว่าก้อน มันก็พัง
ครั้งหน้าที่ AI พลาดในเรื่องที่เราคิดว่าง่าย ลองถามตัวเองว่า งานนี้ต้องให้มันทำงานในระดับเล็กกว่าก้อนคำหรือเปล่า ถ้าใช่ บังคับมันแยกก่อน
แหล่งอ้างอิง
- Fu, T. et al. (2024). Why Do Large Language Models Struggle to Count Letters?
- Singh, A. K. & Strouse, D. (2024). Tokenization counts: the impact of tokenization on arithmetic in frontier LLMs
- Zhang, X. et al. (2024). Counting Ability of Large Language Models and Impact of Tokenization
- Cosma, A. et al. (2025). The Strawberry Problem: Emergence of Character-level Understanding in Tokenized Language Models
- OpenAI tiktoken (BPE tokenizer)



