Karpathy บอกว่าไม่ต้องใช้ RAG: ทำ knowledge base ด้วย folder markdown + Claude Code ใน 5 นาที
Andrej Karpathy โพสต์บน X ว่าเขาทำ personal knowledge base ด้วย folder ของไฟล์ markdown ดิบที่ให้ Claude Code อ่านโดยตรง โดยไม่พึ่ง vector database หรือ embedding ใด ๆ ที่ scale ราว 100 บทความ ครึ่งล้านคำ วิธีนี้ประหยัด token กว่าการคิวรีแบบ naive ถึง 95% และตั้งค่าได้ในห้านาที

Andrej Karpathy โพสต์ thread บน X ว่าเขาเลิกใช้ระบบ RAG ที่ซับซ้อน แล้วเปลี่ยนมาทำ personal knowledge base เป็น folder ของไฟล์ markdown ดิบ ให้ Claude Code อ่านโดยตรง ไม่ต้องพึ่ง vector database, embedding หรือ chunking pipeline ใด ๆ ใน scale ประมาณ 100 บทความ ครึ่งล้านคำ LLM จึง maintain index file และอ่านข้อมูลที่เกี่ยวข้องได้ดีพอ ส่วน Nate Herk จากช่อง Nate Herk | AI Automation นำแนวคิดนี้มาสาธิตการ setup จริงใน 5 นาทีด้วย Obsidian + Claude Code พร้อมยกตัวอย่างผู้ใช้บน X ที่รายงานว่าวิธีนี้ลด token usage ลงได้ถึง 95% เมื่อเทียบกับการคิวรีแบบเดิม
ในคลิป Nate Herk เล่าว่าแนวคิดนี้ได้รับความสนใจวงกว้างภายในไม่กี่วันหลังโพสต์ ผู้ใช้จำนวนมากบน X มองว่านี่อาจเป็น pattern หลักของการสร้าง AI agentic software ในปี 2026 เพราะไม่ต้องวาง infrastructure ก่อนเขียน knowledge base แค่บอก Claude Code ว่า "อ่านไอเดียนี้จาก Karpathy แล้วสร้างให้หน่อย" ระบบก็วาง folder structure ให้เองทั้งหมด
หลักการของ Karpathy: ทำไมโครงสร้าง folder ถึงพอ ไม่ต้องใช้ vector DB
Nate Herk อ้างคำพูดของ Karpathy ตรง ๆ ว่า "I thought that I had to reach for fancy rag, but the LLM has been pretty good about auto maintaining index files and brief summaries of all documents, and it reads all the important related data fairly easily at this small scale" ประโยคนี้สะท้อนว่า Karpathy เริ่มจากคิดว่าต้องใช้ระบบ RAG ที่ซับซ้อน แต่กลับพบว่า LLM รุ่นปัจจุบันดูแล index file และสรุปสั้น ๆ ของทุก document เองได้ดีพอ และ retrieve ข้อมูลที่เกี่ยวข้องมาใช้ในงานจริงได้
ตามที่ Nate Herk นำเสนอ scale ที่ Karpathy พูดถึงคือประมาณ 100 บทความ รวมราว 500,000 คำ ขนาดนี้ Claude Code ยังอ่านโครงสร้าง folder + index + ไฟล์ที่เกี่ยวข้องได้ครบในขั้นตอนเดียว โดยไม่ต้องทำ similarity search ผ่าน embedding ส่วน RAG ปกติต้อง chunk knowledge ออกเป็นชิ้นเล็ก ๆ แปลงเป็น vector แล้วเก็บใน vector database และต้อง re-embed ใหม่ทุกครั้งที่ข้อมูลเปลี่ยน แต่วิธีของ Karpathy เก็บทุกอย่างเป็น raw markdown เปลี่ยนเมื่อไหร่ก็แค่แก้ไฟล์ ไม่ต้องประมวลผลเพิ่ม
Nate Herk ชี้ว่าความได้เปรียบที่แท้จริงของวิธีนี้ไม่ใช่แค่ความง่าย แต่เป็น "relationship depth" หรือความลึกของความสัมพันธ์ระหว่าง knowledge เพราะระบบ RAG หา chunk ที่ similarity score สูงเป็นหลัก บางครั้งผลจึงค่อนข้างผิวเผิน ขณะที่ Claude Code อ่านไฟล์ทั้งโฟลเดอร์เมื่อจำเป็น จึงเห็น link ระหว่างบทความ, tag ระหว่าง concept และ relationship ที่ระบบ embedding มองข้าม
Note: Karpathy ระบุชัดว่าวิธีนี้ใช้ได้ดีที่ "small scale" เท่านั้น ถ้าทำงานกับเอกสารหลักล้านชิ้น ยังต้องใช้ RAG หรือ knowledge graph แบบเดิม รายละเอียดของขอบเขตอยู่ในหัวข้อสุดท้ายของบทความ

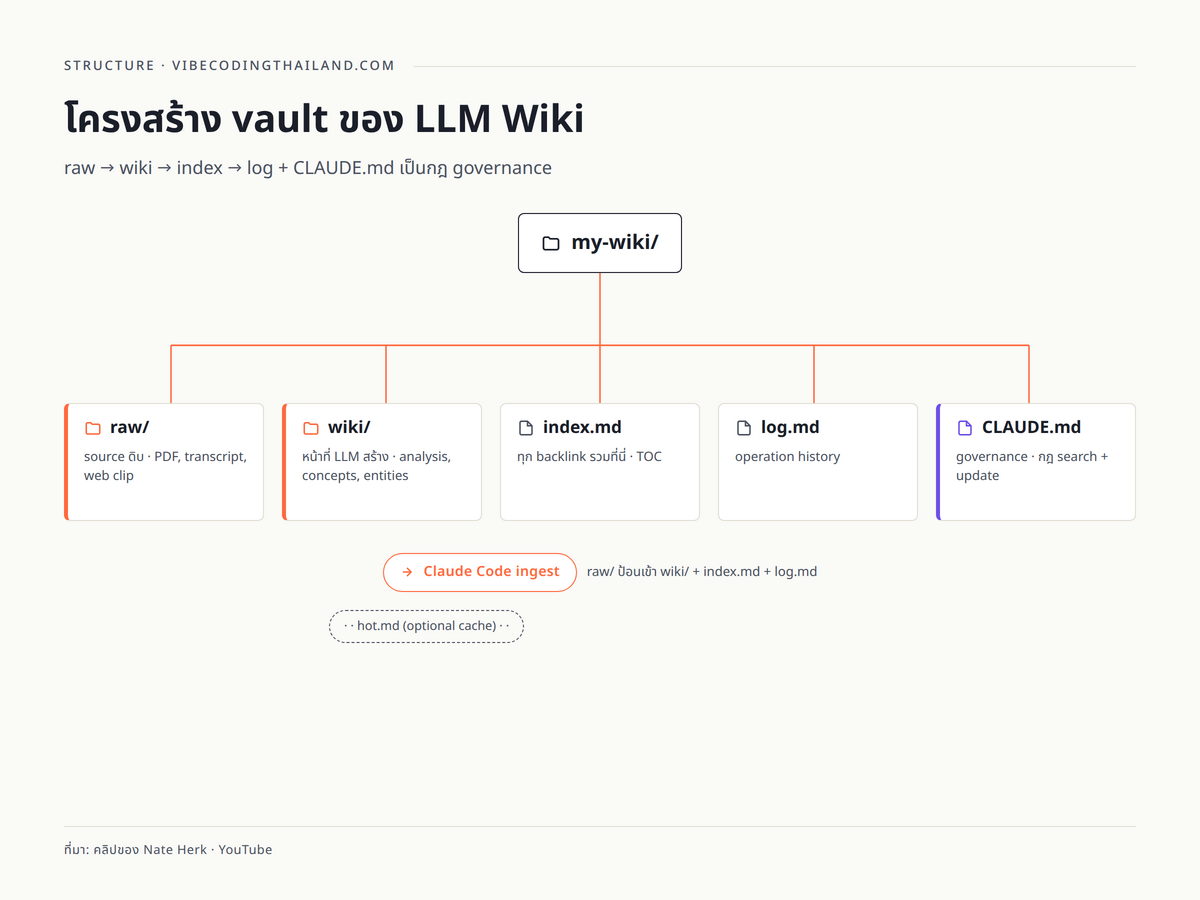
โครงสร้าง folder ของ LLM Wiki: raw → wiki → index → log + CLAUDE.md
ในคลิป Nate Herk เปิด vault จริงให้ดู โครงสร้างมีเพียงไม่กี่ folder และทุก folder เป็นไฟล์ markdown ทั้งหมด ไม่มี database หรือ config พิเศษ รากของ vault คือชื่อโครงการ เช่น my-wiki แล้วภายในประกอบด้วยส่วนหลักดังนี้
raw/คือที่เก็บ source ดิบทั้งหมด เช่น บทความที่ clip มาจากเว็บ, transcript ของ YouTube หรือ PDF ที่ paste เข้ามา Karpathy บอกว่าให้โยนเข้ามาตรง ๆ ไม่ต้องจัดรูปแบบwiki/คือ folder ที่ LLM สร้างเองจากการอ่านraw/แล้วแยกเป็นหัวข้อ ๆ Nate Herk เล่าว่าโดย default Claude Code สร้าง 4 subfolder คือanalysis,concepts,entities,sourcesส่วน Karpathy เองชอบแบบ flat ไม่มี subfolder ผู้สนใจปรับได้ตาม taste ของโครงการindex/หรือไฟล์index.mdที่ระดับ vault เป็น table of contents ที่ LLM maintain เอง มีหัวข้อหลัก เช่น tools, techniques, concepts, sources, people, comparisons และทุกหัวข้อมี backlink ไปยังไฟล์ wiki ที่เกี่ยวข้องlog/หรือไฟล์log.mdคือ operation history ที่บันทึกว่า ingest อะไรเข้ามาเมื่อไหร่ ทำให้ผู้สนใจตรวจสอบย้อนกลับได้ว่า knowledge base ผ่านการ update อะไรไปบ้างCLAUDE.mdคือไฟล์ governance ที่อธิบายว่าโครงการนี้คืออะไร, search อย่างไร, update อย่างไร และห้ามทำอะไร Nate Herk ใช้ไฟล์นี้บอก agent ตัวอื่นด้วยว่าให้อ่าน wiki path นี้เมื่อจำเป็น
Nate Herk ยกตัวอย่างเพิ่มเติมจาก vault ส่วนตัวชื่อ "Herc Brain" ซึ่งมีไฟล์เพิ่มชื่อ hot.md สำหรับเก็บ cache ขนาดราว 500 คำของสิ่งที่เพิ่งคุยกับ executive assistant ของเขา hot cache ช่วยลดการอ่านไฟล์ทั้ง wiki เมื่อ context เกี่ยวกับเรื่องล่าสุด แต่ใน vault ของ YouTube transcript เขาไม่ได้ใส่ hot.md เพราะไม่จำเป็น
วิธี setup จริงใน 5 นาที: Obsidian + Claude Code + starter prompt
ในคลิป Nate Herk สาธิตการ setup vault ใหม่ทั้งหมด โดยแบ่งขั้นตอนเป็น 3 ส่วน
ส่วนแรกคือดาวน์โหลด Obsidian จาก obsidian.md ซึ่งเป็น tool ฟรีที่ทำหน้าที่แสดงไฟล์ markdown แบบ visual และมีฟีเจอร์ graph view ที่ช่วยให้เห็นความสัมพันธ์ระหว่างไฟล์ทั้งหมด Nate Herk ระบุว่า Obsidian ไม่ใช่สิ่งจำเป็น เพราะ LLM Wiki เป็นเพียง folder ของไฟล์ markdown ดังนั้น text editor อะไรก็ได้ใช้แทนได้ แต่ Obsidian ทำให้เห็น relationship ระหว่างไฟล์ในเชิงภาพได้ดี
ส่วนที่สองคือสร้าง vault ใหม่ใน Obsidian เปิดด้วย VS Code หรือ terminal แล้วรัน claude ใน directory นั้นเพื่อเปิด Claude Code Nate Herk แนะนำให้รันใน terminal แยกจาก VS Code เพราะเห็น status line ได้ชัดกว่า แต่ทั้งสองรูปแบบใช้ได้เหมือนกัน
ส่วนที่สามคือ paste prompt ของ Karpathy ที่ให้ไว้ใน X gist แล้วตามด้วย instruction สั้น ๆ ให้ Claude Code build ระบบ จากที่ Nate Herk นำเสนอ ข้อความที่เขาเติมต่อท้ายมีโครงสร้างประมาณนี้
You are now my LLM Wiki agent. Implement this exact idea file as my
complete second brain. Guide me step-by-step. Create the claude.md
schema, the raw/ folder, the wiki/ folder, the index, and the log.
Ask me what this project is for so the structure fits the use case.
หลังจาก Claude Code อ่าน prompt เสร็จ ระบบจะสร้าง folder structure อัตโนมัติและถามว่าโครงการนี้ใช้สำหรับอะไร เช่น personal second brain, research vault หรือ business knowledge base เพื่อปรับ subfolder ให้เหมาะกับงาน ตัวอย่างของ Nate Herk คือเมื่อเขาบอกว่าโครงการนี้ใช้ research เรื่อง AI ระบบก็ปรับ subfolder ใน wiki ให้สอดคล้องกับ scope นั้น
Nate Herk ชี้ว่าหลัง setup เสร็จ ผู้สนใจแค่ใส่ source ลง raw/ แล้วบอก Claude Code ว่า "ingest the new article ในชื่อ X" ระบบจะอ่านบทความ ถามว่าต้องการ emphasize ส่วนไหนและ granularity แค่ไหน จากนั้นแตก source ออกเป็นหลายไฟล์ใน wiki ที่มี relationship ระหว่างกัน ในตัวอย่างของคลิป ระบบแปลงบทความเดียวจาก AI 2027 เป็น wiki page ราว 23 ไฟล์ แยกหัวข้อ people, organizations, AI systems, concepts และ analysis ใช้เวลา ingest ประมาณ 10 นาที ส่วนการ ingest YouTube transcript 36 คลิปพร้อมกันใช้เวลา 14 นาที
Tip: เพื่อให้ clip บทความจากเว็บง่ายขึ้น Nate Herk แนะนำ extension ของ Chrome ชื่อ Obsidian Web Clipper ใช้ดึงเนื้อหาจาก URL ที่เปิดอยู่เข้า vault โดยตรง ผู้สนใจต้องไปที่ option ของ extension แล้วเปลี่ยน default location จาก
clippings/เป็นraw/เพื่อให้ Claude Code หา source ได้ใน folder ที่ถูกต้อง
ทำไมประหยัด token: case 95% reduction และ knowledge ที่ compound เหมือนดอกเบี้ย
Nate Herk เล่าว่า pattern นี้ได้รับความสนใจไม่ใช่แค่เพราะทำง่าย แต่เพราะ token efficiency ด้วย เขาอ้างถึงผู้ใช้บน X รายหนึ่งที่นำไฟล์ scattered 383 ไฟล์ + meeting transcript กว่า 100 รายการ มาแปลงเป็น compact wiki ตาม pattern ของ Karpathy แล้วลด token usage ลงได้ถึง 95% เมื่อเทียบกับการ query Claude แบบเดิมที่โยนไฟล์ดิบทั้งหมดเข้า context ทุกครั้ง
ในคลิป Nate Herk อธิบายว่ากลไกที่ทำให้ประหยัด token มีสองส่วน ส่วนแรก เมื่อมี index file ที่ดี LLM จะอ่าน index ก่อนเพื่อดูว่ามีไฟล์อะไรบ้าง แล้วเลือกอ่านเฉพาะไฟล์ที่เกี่ยวข้อง ไม่ต้องโยน context ดิบทั้งหมดเข้าไป ส่วนที่สอง เมื่อมี wiki page ที่สรุปและจัดหมวดหมู่แล้ว ระบบไม่ต้องอ่าน raw source ทุกครั้งที่ตอบคำถาม จึงใช้ token น้อยลงอย่างมีนัยสำคัญ
Nate Herk ยกตัวอย่างจากประสบการณ์ของตัวเองว่า เขาเปลี่ยน executive assistant agent จากเดิมที่ใช้ context file ทั้งหมดที่ pin ไว้ใน project มาเป็นการชี้ไปที่ wiki path ของ vault "Herc Brain" แล้วเห็น token consumption ลดลงจริง ใน CLAUDE.md ของ agent นั้น เขียนกฎไว้ว่า "Don't read from the wiki unless you actually need it" พร้อมระบุชนิดของงานที่ไม่จำเป็นต้องอ่าน wiki ไว้ชัด ๆ เพื่อไม่ให้ agent โหลด context เกินจำเป็น
นอกจากนี้ Nate Herk ชี้ว่าประโยชน์อีกอย่างจับต้องได้น้อยกว่าแต่สำคัญไม่แพ้กัน คือ knowledge ที่ "compound" เหมือนดอกเบี้ย ระบบ chat ปกติของ AI เป็น ephemeral ความรู้หายไปหลังจบ conversation แต่ LLM Wiki บันทึก knowledge สะสมตลอด ทำให้ AI agent ทำงานเหมือนเพื่อนร่วมงานที่จำทุกอย่างได้ และเห็น relationship ระหว่างเรื่องที่เคยคุยทั้งหมด จุดนี้เองที่ผู้ใช้บน X เรียก pattern นี้ว่า game-changer
ขอบเขตและ tradeoff: ใช้แทน RAG ได้แค่ไหน
ในตอนท้ายคลิป Nate Herk ใช้ Claude Code สร้างตารางเปรียบเทียบระหว่าง Karpathy LLM Wiki กับ semantic search RAG แบบปกติ และพบความแตกต่างใน 5 มิติ
มิติแรกคือ retrieval mechanism วิธีของ Karpathy ใช้การอ่าน index แล้วตาม backlink ไปยังไฟล์ที่เกี่ยวข้องโดยตรง ทำให้เห็น relationship ระหว่าง concept ชัดเจน ส่วน semantic search RAG ใช้ similarity score ระหว่าง vector จึงเก่งในการหา chunk ที่คล้ายกัน แต่ไม่เห็นความสัมพันธ์เชิงโครงสร้าง
มิติที่สองคือ infrastructure วิธีของ Karpathy ใช้แค่ folder ของ markdown ไม่ต้องมี embedding model, vector database หรือ chunking pipeline ส่วน semantic search RAG ต้องมีทั้งสามส่วนนี้ครบ จึงต้องใช้ทั้งความรู้และ infrastructure cost เพิ่มเติม
มิติที่สามคือ cost วิธีของ Karpathy แทบไม่มี ongoing cost ใด ๆ ยกเว้น token ที่ใช้ใน Claude Code เอง ส่วน RAG ต้องเสีย compute และ storage cost ของ vector database เป็นรายเดือน
มิติที่สี่คือ maintenance วิธีของ Karpathy ดูแลด้วยการรัน "lint" บน wiki เป็นระยะ เช่น ทุกวันหรือทุกสัปดาห์ ให้ LLM ตรวจ inconsistency, เติม missing data ด้วย web search และหา connection ใหม่ระหว่าง article ส่วน RAG ต้อง re-embed ใหม่ทุกครั้งที่ข้อมูลเปลี่ยน จึงมี compute cost ต่อเนื่อง
มิติที่ห้าและสำคัญที่สุดคือ scale ซึ่งเป็นจุดอ่อนโดยตรงของวิธี Karpathy Nate Herk ระบุว่าถ้า knowledge base มีหลัก "hundreds of pages with good indexes" วิธีนี้ยังพอไหว แต่ถ้าขึ้นถึงระดับล้านเอกสาร ต้อง fall back ไปใช้ RAG หรือ knowledge graph แบบเดิม เพราะ Claude Code อ่านไฟล์ทั้ง folder ในระดับ enterprise ไม่ไหวและไม่คุ้ม
Warning: Karpathy เองยอมรับใน gist follow-up ว่า prompt ที่เขาแชร์เขียนไว้ vague โดยตั้งใจ เพื่อให้ผู้ใช้ปรับเองตาม use case จริง ถ้าทำตามตรง ๆ ทั้ง vault ผู้สนใจจึงอาจได้ folder structure ที่ไม่เหมาะกับงานของตัวเอง การคุยกับ Claude Code เพื่อปรับ subfolder + ขอบเขตของ wiki ในช่วง setup จึงสำคัญพอ ๆ กับการรัน prompt เริ่มต้น
สำหรับนักพัฒนาที่ใช้ Claude Code เป็นเครื่องมือหลักอยู่แล้ว pattern นี้แทบไม่มีต้นทุนเริ่มต้น Nate Herk สรุปว่ามูลค่าที่แท้จริงไม่ได้อยู่ที่ tool แต่อยู่ที่ idea คือเลิกคิดว่า personal knowledge base ต้องมี infrastructure ซับซ้อนเสมอ และยอมรับว่าในระดับ small scale LLM ทำหน้าที่ retrieval + organization ได้ดีพอจริง
ที่มา: สรุปจากคลิป "Andrej Karpathy Just 10x'd Everyone's Claude Code" ของช่อง Nate Herk | AI Automation เผยแพร่ 5 เมษายน 2026 (520,629 views ณ วันที่อ้างอิง)



