ระบบ memory ของ Claude Code ที่ Karpathy ทำ viral 18 ล้านวิว และจุดที่มันพังตอน scale
ช่อง Jack Roberts สรุประบบ memory แบบ Claude Code + Obsidian ที่ Andrej Karpathy ทำ viral กว่า 18 ล้านวิว ซึ่งทำงานเป็น personal Wikipedia ที่ LLM ดูแลเอง 1 source อัปเดต 10-15 หน้าในรอบเดียว พร้อมเปิด 5 จุดที่ระบบพังตอน scale และทางแก้เป็นสถาปัตยกรรม 4 ชั้น
ช่อง Jack Roberts สรุปกระแสจาก Andrej Karpathy ผู้ร่วมก่อตั้ง OpenAI ที่ทำ viral กว่า 18 ล้านวิว จากการพูดถึงการต่อ Claude Code เข้ากับ Obsidian จนกลายเป็นระบบความจำที่เรียกว่า Obsidian memory system ระบบนี้ตามที่ Jack Roberts นำเสนอ แก้ปัญหาที่นักพัฒนาเจอบ่อยที่สุดอย่างหนึ่ง คือ context loss หรืออาการ "ลืม" ของโมเดล โดยปกติ LLM จะ hallucinate อย่างน้อยราว 1% และอาจสูงถึง 10% เมื่อบทสนทนายาวขึ้น ผู้ใช้จึงไม่มีทางรู้ว่าตอนไหนโมเดลตอบผิดอย่างมั่นใจ จุดเด่นของบทความนี้ไม่ได้อยู่ที่การอธิบายระบบให้ฟังดูสวยงามเท่านั้น เพราะ Jack Roberts ระบุว่า 90% ของคอนเทนต์ที่พูดถึงเรื่องนี้เป็นเพียง "node porn" คือโชว์ภาพกราฟสวยแต่ไม่ลงลึกถึงข้อจำกัดร้ายแรงหลายข้อ บทความนี้จึงสรุปตามคลิป ทั้งวิธีทำงาน จุดที่ระบบพังตอน scale และทางแก้เป็นสถาปัตยกรรม 4 ชั้นที่ออกแบบให้ใช้ได้ระยะยาว
1. Obsidian memory system คืออะไร
Jack Roberts อธิบายในคลิปว่า แนวคิดของ Andrej Karpathy คือการใช้ LLM สร้างฐานความรู้ส่วนตัวสำหรับแต่ละหัวข้อที่สนใจ วิธีเห็นภาพง่ายที่สุดคือมองว่ามันเป็น Wikipedia ส่วนตัว แทนที่ระบบ retrieval แบบเดิมจะดึงเอกสารดิบกลับมาทุกครั้งที่ถาม ระบบนี้ให้ LLM ค่อย ๆ เรียบเรียงและดูแล wiki ที่อยู่กึ่งกลางระหว่างผู้ใช้กับแหล่งข้อมูลดิบ โดย wiki ก็คือชุดของไฟล์ markdown กับโครงสร้างไดเรกทอรีเท่านั้น เมื่อมีคำถามเข้ามา Claude จะไล่ผ่านไดเรกทอรี หาไฟล์ที่เกี่ยวข้อง เปิดอ่าน แล้วจึงตอบ
Jack Roberts ชี้ว่า Obsidian เองเป็นเพียงเลเยอร์สำหรับมองไฟล์ในเชิงภาพ ไม่ใช่หัวใจของระบบ จึงนำแนวคิดนี้ไปใช้กับสภาพแวดล้อมใดก็ได้ ทั้ง Antigravity, Cursor หรือ terminal ส่วน graph view ที่หลายคนชอบโชว์นั้น Jack Roberts ให้ความเห็นว่ายังไม่เคยเห็นใครใช้มันตัดสินใจอะไรได้จริง มันเป็นเพียงภาพที่ดูสวย แม้ความสัมพันธ์ระหว่าง node บางส่วนจะสำคัญอยู่บ้างก็ตาม
ข้อมูลจากคลิปชี้ว่าโครงสร้างทั้งหมดมีเพียง 3 ที่เก็บ ไม่มีฐานข้อมูลใด ๆ ได้แก่ โฟลเดอร์สำหรับ raw sources ที่ป้อนข้อมูลเข้าไป โฟลเดอร์สำหรับ wiki ที่ Claude เป็นคนเขียน และไฟล์เดียวที่บอกกฎให้ Claude ทำงาน ซึ่งก็คือ schema rulebook โดย raw sources อาจเป็นบทความ PDF transcript หรือ web clip ส่วน wiki คือสรุปที่ Claude เขียนให้ผู้ใช้อ่าน และ rulebook คือ convention กับ workflow ที่เปลี่ยน Claude ให้เป็นผู้ดูแล wiki แทนที่จะเป็นแค่ผู้ตอบคำถาม
2. Compounding effect และ 3 operation หลัก
ประเด็นที่ Jack Roberts เน้นมากที่สุดคือความต่างระหว่าง RAG แบบเดิมกับระบบ LLM Wiki นี้ RAG แบบเดิมทำงานเป็นวงจร คือ query เข้าไป หา chunks เย็บคำตอบ แล้วลืม วันต่อมาก็เริ่มกระบวนการเดิมตั้งแต่ศูนย์ทุกครั้ง ในทางกลับกัน Jack Roberts อธิบายว่า ระบบ Obsidian memory จะทับถมคุณค่าขึ้นเรื่อย ๆ ตามเวลา เพราะ source ใหม่ 1 ชิ้นจะอัปเดต wiki ราว 10-15 หน้าในรอบเดียว ความรู้นั้นจะค้างอยู่ และทุกคำถามในอนาคตจะอ่านจากมัน นี่คือสิ่งที่คลิปเรียกว่า compounding effect
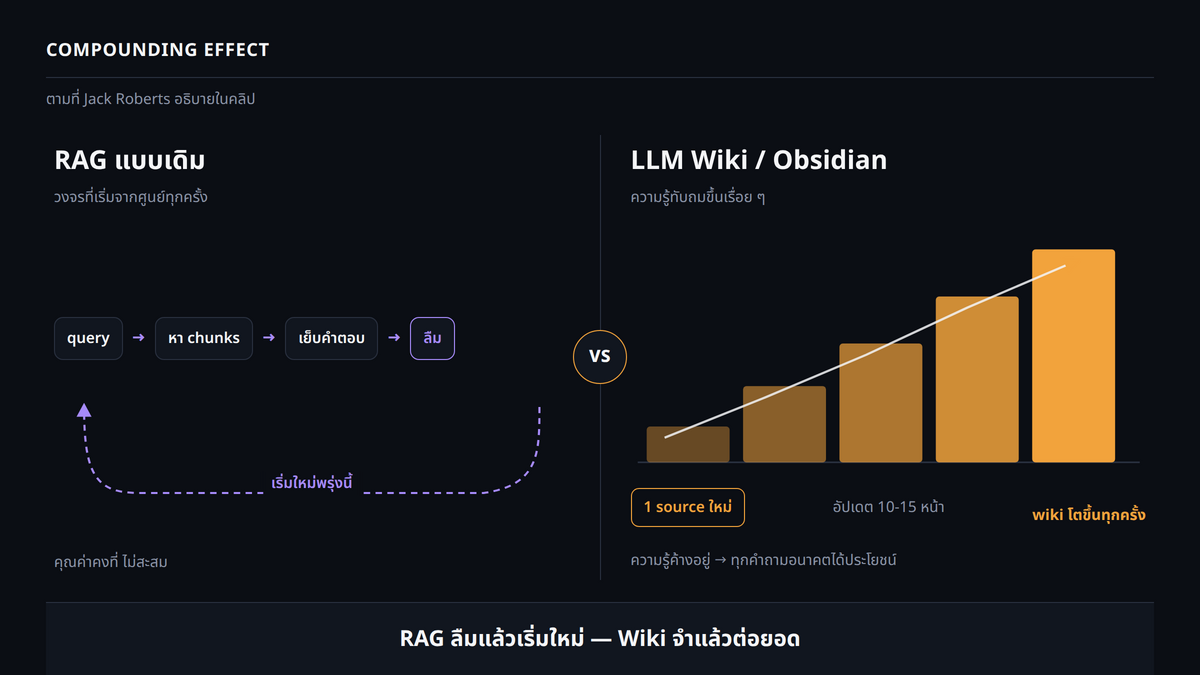
Jack Roberts ยกตัวอย่างว่า ถ้าต้องการขยายบัญชี LinkedIn เมื่อนำบทความที่ดีเรื่องการเติบโตบน LinkedIn ใส่เข้าระบบ Claude จะอ่านมัน ไล่หาทุกหน้าใน wiki ที่เกี่ยวข้องกับ LinkedIn แล้วอัปเดตให้ทั้งหมด พร้อมทั้งทำเครื่องหมายจุดที่ขัดแย้งกับข้อมูลเดิม ความขัดแย้งจึงคลี่คลายไประหว่างทาง สรุปคือ source เดียวเข้าไปแล้ว Claude อัปเดต 15 ไฟล์ในรอบเดียว
นอกจากนี้ Jack Roberts ยังระบุ 3 operation หลักของระบบ ได้แก่ ingest คือการป้อนข้อมูลเข้าไป query คือการตั้งคำถาม และ linting ซึ่งเป็นกระบวนการที่ Andrej Karpathy พูดถึง ทุก ๆ สองสามสัปดาห์ ระบบจะไล่หาความขัดแย้ง ข้อมูลที่ค้างเก่า และงานดูแลที่มนุษย์มักลืมทำตามธรรมชาติ คลิปยังชี้ว่าไฟล์ที่แบกงานหนักที่สุดคือ index.md กับ log.md เพราะทำให้ LLM รับงานบันทึกบัญชีแทน และ wiki จะทับถมคุณค่าขึ้นเอง สิ่งที่สร้างได้ด้วยระบบนี้มีตั้งแต่ book companion ไปจนถึง research deep dive, wiki ของทีมหรือธุรกิจ และ wiki ชีวิตส่วนตัว
3. 4 ขั้นตอนการใช้งานจริง
Jack Roberts นำเสนอว่า การใช้ระบบนี้มีกฎอยู่ 4 ข้อที่ค่อนข้างเรียบง่าย ข้อแรกคือเลือกหนึ่ง domain เท่านั้น ไม่ใช่รวมทุกอย่างเข้าด้วยกัน เช่น หนังสือหนึ่งเล่ม project หนึ่งงาน หรือคำถามวิจัยหนึ่งคำถาม เพราะระบบทำงานได้ดีกว่าเมื่อเป็น project ที่กำหนดขอบเขตชัด ให้มองแต่ละ wiki เป็นฐาน Wikipedia ขนาดเล็กที่แยกกัน และเรียกใช้ตามแต่ละหัวข้อ
ข้อสอง Jack Roberts อธิบายว่าต้องให้เวลากับ section แรก เพราะ Claude จะถามคำถามและผู้ใช้ต้องตอบให้ดี จุดนี้คือช่วงที่เขียน rulebook ขึ้นมา ข้อสามคือทำงานสองหน้าจอ ฝั่งหนึ่งเป็น Claude Code อีกฝั่งเป็น graph view ของ Obsidian เพื่อดู node ที่ติดสว่างขึ้นขณะ Claude ทำงาน ส่วนข้อสี่คือทุก ๆ สองสามสัปดาห์ให้ purge หรือกวาดล้างระบบหนึ่งครั้ง
Jack Roberts สรุป loop การทำงานว่า session แรกให้วาง prompt ตั้งต้นเข้าไป Claude จะถามว่า wiki นี้ทำเพื่ออะไร แล้วผู้ใช้กับ Claude จะร่วมกันเขียนกฎขึ้นมา หลังจากนั้นทุก session ต่อมาจะวนซ้ำ คือ drop source ใหม่เข้าไป Claude รวมมันเข้าระบบ อัปเดต 10-15 หน้าที่เกี่ยวข้อง แล้วผู้ใช้จะเห็น wiki ขยายตัวใน Obsidian ในคลิป Jack Roberts ยังแนะนำเสริมว่า Obsidian มี web clipper อย่างเป็นทางการที่ติดตั้งเป็น extension ของ browser ได้ ช่วยให้การ clip ข้อมูลจากหน้าเว็บเข้า vault สะดวกขึ้นมาก รวมถึงตั้งค่าให้ดาวน์โหลดรูปจากบทความมาเก็บในเครื่องด้วย
Tip: Jack Roberts ระบุว่ายังไม่จำเป็นต้องสร้าง search interface ให้สวยตั้งแต่แรก เพราะ search engine ที่ใช้อยู่แล้วก็คือ Claude ที่เปิด master folder พร้อม subfolder ทั้งหมดในสภาพแวดล้อมการทำงาน ค่อยเพิ่มลูกเล่นเมื่อระบบโตถึงระดับหนึ่ง
4. จุดที่ระบบพังตอน scale
นี่คือส่วนที่ Jack Roberts ระบุว่าแทบไม่มีใครพูดถึงในกระแส hype รอบนี้ คลิปชี้ว่าถ้าใช้ Obsidian ร่วมกับ Claude Code เพียงอย่างเดียว ระบบจะมีจุดเปราะอยู่ราว 5 จุด จุดแรกคือไฟล์ CLAUDE.md และไฟล์ index จะโตขึ้นตามเวลา ถ้าแต่ละรายการใน index กินราว 75 token เมื่อมี 10 ไฟล์ก็ราว 750 token แต่เมื่อมี 10,000 ไฟล์ token window สำหรับการไล่อ่านหน้า index อย่างเดียวจะโตแบบ exponential และ token cost ของการใช้ระบบก็โตตาม จึงมีต้นทุนที่ต้องจ่ายเสมอเมื่อระบบขยาย
Jack Roberts อธิบายจุดที่เหลือต่อว่า ระบบนี้ไม่มี semantic search เพราะมันไล่ตามหัวข้อของเรื่อง ไม่ใช่ความหมายเชิงความสัมพันธ์ ข้อมูลบางส่วนอาจค้างเก่าเพราะ drift ของ CLAUDE.md หน้าต่าง token ขนาดล้าน token จะเต็มเร็วขึ้นด้วยวิธีนี้ และระบบไม่ได้ออกแบบมาสำหรับ dataset ขนาดใหญ่ คลิปสรุปเป็นประโยคที่จำง่ายว่า มันรู้สึกเหมือนเวทมนตร์ตอนมี 100 ไฟล์ แต่จะกินทรัพยากรอย่างหนักเมื่อถึง 10,000 ไฟล์ Jack Roberts เปรียบเทียบว่า Obsidian มี cost ที่ scale แบบเชิงเส้น ขณะที่ระบบ vector database อย่าง Pinecone จะมี cost คงที่ ทั้งนี้คลิประบุชัดว่าตัวเลขเหล่านี้เป็นเพียงการประมาณคร่าว ๆ ในเชิง order of magnitude ไม่ใช่ benchmark ที่วัดจริง สิ่งสำคัญคือรูปร่างของเส้นกราฟ ไม่ใช่ตัวเลขเป๊ะ ๆ
Jack Roberts ยกตัวอย่างว่า ถ้ามี YouTube transcript จำนวนมาก เช่น 184 transcript ข้อมูลแบบนี้ไม่ควรอยู่ใน Obsidian เพราะถ้าใส่ผ่าน Obsidian โดยใช้ Claude โมเดลต้องอ่าน context window ทั้งหมดเพื่อทำความเข้าใจ แล้วยังต้องพิมพ์กลับออกมาเป็นส่วนสรุปต่าง ๆ ในทางกลับกัน Pinecone จะรัน script ที่ Claude แทบไม่ต้องเข้ามาเกี่ยวข้อง และต้นทุน embedding ถูกกว่าราว 100 เท่าตามโมเดล embedding ที่ใช้ ทำให้ต้นทุน ณ จุด ingestion ต่ำกว่ามาก หลักการที่ Jack Roberts ให้ไว้คือ Obsidian เหมาะกับสิ่งที่เปลี่ยนแปลง ส่วน Pinecone เหมาะกับสิ่งที่ไม่เปลี่ยน
5. ทางแก้ — สถาปัตยกรรม memory 4 ชั้น
Jack Roberts สรุปว่าระบบที่ scale ได้จริงไม่ใช่สองชั้น แต่เป็นสี่ชั้น และให้ analogy ที่ทำให้เห็นภาพชัด คือ CLAUDE.md คือตัวตน Pinecone คือสิ่งที่เคยพูดไว้ และ Obsidian คือวิธีคิด คลิปขยายความว่า CLAUDE.md คือ identity badge ที่บอกชื่อ บทบาท และกฎที่ต้องอ่านก่อนสิ่งอื่นและไม่เปลี่ยน Obsidian rag คือ workshop ที่ลงมือทำงานหนัก เหมาะกับ active project, decision log และพื้นที่ที่โครงสร้างสำคัญ ส่วน Pinecone คือ warehouse ที่เก็บของชิ้นใหญ่ทั้งหมด ทั้ง transcript, research archive และหนังสือที่ต้องการ recall แบบเป๊ะ คำสำคัญที่ Jack Roberts ให้ไว้คือ Obsidian มีค่าที่การให้เหตุผล ไม่ใช่ความจำ มันให้เหตุผลข้ามโครงสร้างแบบกราฟได้ ขณะที่ Pinecone ให้การ recall ที่สมบูรณ์แบบของ archive ขนาดใหญ่ด้วย exact text และ cost คงที่ แต่ทำได้แค่ similarity ไม่มี graph ไม่มีการ reason ข้ามความสัมพันธ์
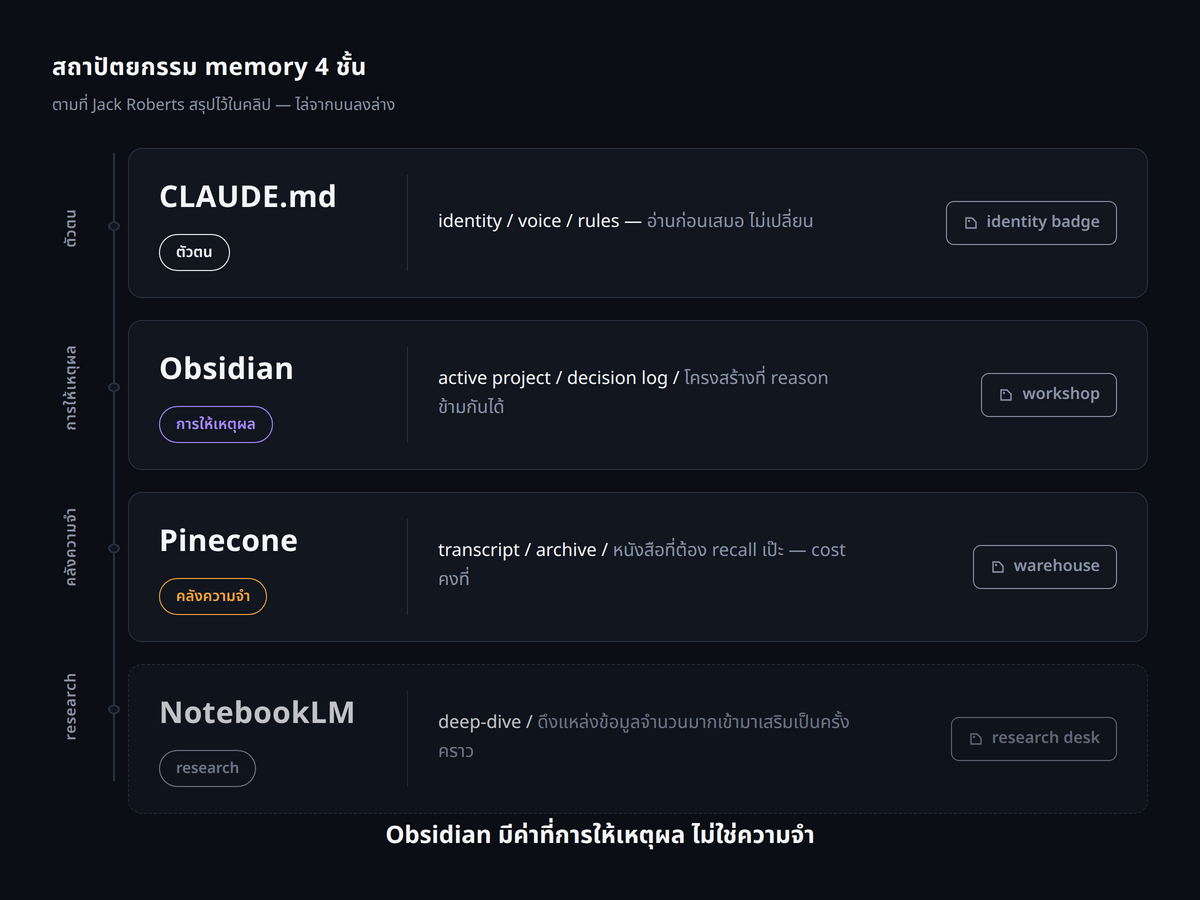
นอกจากสามชั้นนั้น Jack Roberts เพิ่มชั้นที่สี่เข้ามาคือ NotebookLM สำหรับงาน deep dive และ research โดยยกตัวอย่างว่าถ้ากำลังเรียนรู้กระบวนการผลิตบางอย่าง สามารถสั่งให้ปั่น notebook ขึ้นมาพร้อมแหล่งข้อมูล 200 ชิ้นที่อธิบายทุกอย่าง แล้วดึงกลับเข้ามาที่เครื่อง และโยนเข้า long-term memory ได้ถ้าต้องการ recall ภายหลัง คลิปเน้นว่าเรื่องสำคัญคือการเข้าใจว่าทั้งสี่ชั้นนี้เชื่อมโยงกันเชิงความสัมพันธ์อย่างไร Jack Roberts ระบุว่า การเชื่อม Pinecone เข้ากับ Claude ทำได้ง่ายมากในตอนนี้ ถึงขั้นที่เพียงตั้งคำถาม Claude จะเอื้อมไปหา Pinecone หาคำตอบ แล้วนำกลับมาให้ บทสรุปของ Jack Roberts คือถ้าไม่มีระบบ long-term memory ก็เท่ากับทิ้งคุณค่าไว้บนโต๊ะ จึงต้องเรียนรู้การผสาน Pinecone เข้ากับระบบเพื่อรักษาข้อมูลไว้ในระยะยาว
Jack Roberts สรุปว่า ระบบ memory แบบ Obsidian ที่ Andrej Karpathy ทำให้เป็นที่รู้จัก ไม่ใช่คำตอบเดียวที่ครอบคลุมทุกสถานการณ์ แต่เป็นชั้นหนึ่งที่มีคุณค่าเฉพาะตัวด้านการให้เหตุผลข้ามโครงสร้าง ผู้ใช้จึงต้องเข้าใจว่าจะใช้มันทำอะไรและจะเสริม Pinecone เข้ามารองรับตรงไหน จึงจะได้ระบบความจำที่ไม่ลืมในระยะยาวอย่างแท้จริง
เนื้อหานี้สรุปและเรียบเรียงจากคลิปของช่อง Jack Roberts
ดูคลิปเต็มของ Jack Roberts: https://www.youtube.com/watch?v=eglVxLaWRUU
อ่านฉบับเต็มที่: https://vibecodingthailand.com/blog/claude-code-obsidian-memory



